MyCat2,你会了吗?
1.概述
1.1定义
MyCAT 是目前最流行的分布式数据库中间件之一,是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的服务器。可把它看作一个数据库代理,可以使用 MySQL客户端访问,后端可以用 MySQL 原生协议与多个 MySQL 服务器通信,也可以用JDBC协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将个大表水平分割为 N个小表,存储在后端 MySQL 服务器里或者其他数据库里。MyCAT 发展至今,已经可以支持 MySQL、SQL Server、Oracle、PostqreSQL等主流数据库,也支持 MonoDB 这种新型 NOSQL方式的存储。MyCat2是对MyCat的升级版本,可以实现读写分离和分库分表。(后续MyCat就表示MyCat2)
官网地址:http://www.mycat.org.cn/ 或http://mycatone.top/(目前前者打不开)
源码地址:https://github.com/MyCATApache/Mycat2
1.2原理
MyCat其实是对数据库的抽象,而数据库是对底层存储文件的抽象。那么什么是抽象?设想一下,如果一个项目只有一个人完成时,此时不需要 Leader,但如果有多人共同完成时,就需要Leader统筹安排,那么这个Leader对于其上级领导来说就是对项目组的抽象,也就是说项目有问题时,只需要找这个Leader而无需找下级的同事。站在技术角度,当应用只需要一台数据库服务器时,是不需要MyCat的,但如果涉及分库分表,面临多台服务器时,就需要对数据库层做一个抽象,来管理这些数据库,而应用只需要找这个抽象的服务即可,这就是MyCat的核心作用。
了解了抽象后,那么就更好理解其原理了。简单来说,MyCat通过拦截用户或应用发送的SQL语句,对SQL语句做了一些特定的分析,如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往真实数据库,并将返回的结果做适当处理后返回给用户,但不会存储数据。换句话说,在工作方式上,MyCat会部署为一个MySQL服务,我们只需要像操作普通的单机MySQL服务一样去操作MyCat,对于代码则无需变动即可使用MyCat。
2.安装
2.1下载
MyCat2目前只支持JDK8,其他版本可能不适用。若未安装请先安装,这里直接在linux中进行安装
官网下载:
- 安装程序包:http://dl.mycat.org.cn/2.0/install-template/mycat2-install-template-1.21.zip
- 依赖的jar包:http://dl.mycat.org.cn/2.0/1.21-release/mycat2-1.21-release-jar-with-dependencies.jar
网盘下载:
注:若官网无法打开,则文件就无法下载。网盘提供的安装文件中,依赖的jar包是1.22。
2.2安装步骤
1)将两个文件上传至Linux的/usr/tools路径下
2)解压zip文件
yum -y install unzip unzip mycat2-install-template-1.21.zip mv mycat /usr/local
3)修改文件权限
cd /usr/local/mycat/bin
chmod +x *
4)把依赖的jar复制到安排目录的lib下
cd ../lib cp /usr/tools/mycat2-1.21-release-jar-with-dependencies.jar ./
5)启动一个MySQL服务
MyCat在启动时需要先默认指定一个数据库,这里就默认MySQL数据库的配置信息【端口:3306,用户名:root,密码:123456】,然后创建一个名为mycat的数据库。
6)配置MyCat的数据源
配置文件位置:mycat/conf/datasources/prototypeDs.datasource.json,打开后如下:
{ "dbType":"mysql", "idleTimeout":60000, "initSqls":[], "initSqlsGetConnection":true, "instanceType":"READ_WRITE", "maxCon":1000, "maxConnectTimeout":3000, "maxRetryCount":5, "minCon":1, "name":"prototypeDs", "password":"123456", "type":"JDBC", "url":"jdbc:mysql://localhost:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8", "user":"root", "weight":0 }
对于这段配置,只需要修改user、password、url三个字段,可以看出这三个字段分表是数据库的用户名、密码和url。这里只用修改url中数据库名称即可
7)启动MyCat
cd /usr/local/mycat/bin
./mycat start
其他额外命令
./mycat stop 停止 ./mycat console 前台运行 ./mycat install 添加到系统自动启动 ./mycat remove 取消随系统自动启动 ./mycat restart 重启 ./mycat pause 暂停 ./mycat status 查看启动状态
8)连接到MySQL服务
启动完成,那肯定要测试是否可以连接到服务。打开MySQL的客户端工具(navicat和SQLyog都支持连接到MyCat),连接一个MySQL服务(MyCat的默认端口是8066)
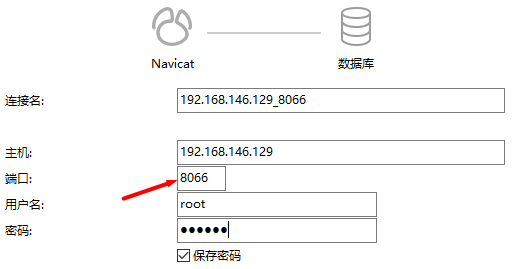
点击左下角测试连接,显示连接成功则说明MyCat安装成功。从这里可以看出,MyCat也是一个MySQL服务,只不过它是一个逻辑库,并不是真实存在的。
3.配置文件说明
虽然说配置文件无需手动配置,但还需了解一番。配置文件即为mycat/conf目录下的文件。
3.1 用户信息(users)
文件位置:mycat/conf/users/{用户名}.user.json。
作用:此文件主要配置MyCat的登录用户,也就是连接到8066这个端口的用户信息。
打开root.user.json,看到配置内容如下
{ "dialect":"mysql", "ip":null, "password":"123456", "transactionType":"proxy", "username":"root" }
说明如下
- dialect:数据库(方言)类型,默认是mysql
- ip:配置白名单使用,默认null。如果要限制ip访问,则需要配置需要访问的ip
- password:配置MyCAT用户的密码(明文)
- transactionType:事务类型
默认值:proxy(本地事务,MyCat不做事务控制,具体的事务控制由后端的真实数据库控制,而且对于分布式场景下事务可能会失败,但是兼容性最好)
可选值:xa(分布式事务,需要确认存储节点集群类型是否支持XA)
- username:配置MyCAT用户的用户名
3.2 数据源(datasource)
文件位置:mycat/conf/datasources/{数据源名称}.datasource.json。
作用:配置MyCat连接真实数据库的数据源。
具体内容详见上述章节2.2已有内容,但配置说明主要字段如下:
- dbType:数据源类型
- name:数据源名字
- password:真实MySQL的密码
- url:真实MySQL的JDBC连接地址
- user:真实MySQL的用户名
- weight:配置数据源负载均衡的使用权重
3.3 逻辑库与逻辑表(logicaltable)
文件位置:mycat/conf/schemas/{库名}.schema.json。
作用:配置MyCat里面和MySQL对应的逻辑表。
打开root.user.json,其主要配置字段如下
{ "customTables": {}, "globalTables": {}, "normalTables": {}, "schemaName": "test", "shardingTables": {}, "targetName": "prototype" }
说明如下
- customTables:自定义表
- globalTables:全局表
- normalTables:默认表
- schemaName:库名
- shardingTables:分片表
- targetName:数据源名,也可以是集群名
3.4 序列号(sequence)
文件位置: mycat/conf/sequences/{数据库名字}_{表名字}.sequence.json。
作用:使用序列号的分片表,对应的自增主键要在建表SQL中体现。(具体见后续章节)
3.5 服务器(server)
文件位置:mycat/server.json
作用:MyCat的服务器的配置信息,一般无需额外配置。端口就在这里配置的。
4.注释配置
MyCat需要通过注释的方式进行配置,其语法就是如此,可能是为了和数据库的执行语句做区分吧。
4.1配置用户
1)创建用户
/*+ mycat:createUser{ "username":"admin", "password":"admin", "transactionType":"xa" } */
上述表示创建一个MyCat的用户,用户名和密码都是admin,事务类型是xa。创建后即可使用这个用户登录MyCat。(以下均在navicat执行)
2)删除用户
/*+ mycat:dropUser{ "username":"admin"} */
删除时,指定用户名即可。
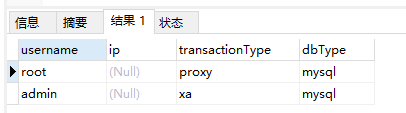
3)显示用户
/*+ mycat:showUsers */
查询的结果
4.2配置数据源
1)创建数据源
只需要设置name、password、type、url、user几个字段即可
/*+ mycat:createDataSource{ "dbType":"mysql", "idleTimeout":60000, "initSqls":[], "initSqlsGetConnection":true, "instanceType":"READ_WRITE", "maxCon":1000, "maxConnectTimeout":3000, "maxRetryCount":5, "minCon":1, "name":"数据源名称", "password":"数据库密码", "type":"JDBC", "url":"jdbc:mysql://127.0.0.1:3306/数据库名?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"数据库用户名", "weight":0 } */;
2)删除数据源
只要设置name字段即可
/*+ mycat:dropDataSource{ "name":"数据源名称" } */;
3)显示数据源
/*+ mycat:showDataSources{} */
4.3配置集群
1)创建集群
/*! mycat:createCluster{ "clusterType":"MASTER_SLAVE", "heartbeat":{ "heartbeatTimeout":1000, "maxRetry":3, "minSwitchTimeInterval":300, "slaveThreshold":0 }, "masters":[ "dc1" //主节点数据源名称 ], "maxCon":2000, "name":"c0", "readBalanceType":"BALANCE_ALL", "replicas":[ "dc2" //从节点数据源名称 ], "switchType":"SWITCH" } */;
2)删除集群
/*! mycat:dropCluster{ "name":"c0" } */;
根据集群名称删除
3)显示集群
/*+ mycat:showClusters{} */
4.4重置配置
把配置的信息重置为默认值
/*+ mycat:resetConfig{} */
5.MyCat2配置读写分离(MySQL版)
前提:MySQL已搭建一主一从服务实现主读写从只读。参考搭建。下面的操作均在MyCat中完成(端口8066)
1)为主节点M1创建数据源
由于其他参数都是默认的,无需修改,这里直接省略,只写主要的参数
/*+ mycat:createDataSource{ "dbType":"mysql", "name":"m1", "password":"123456", "type":"JDBC", "url":"jdbc:mysql://127.0.0.1:3307/test_demo?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root" } */;
2)为从节点M1S1创建数据源
/*+ mycat:createDataSource{ "dbType":"mysql", "name":"m1s1", "password":"123456", "type":"JDBC", "url":"jdbc:mysql://127.0.0.1:3308/test_demo?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root" } */;
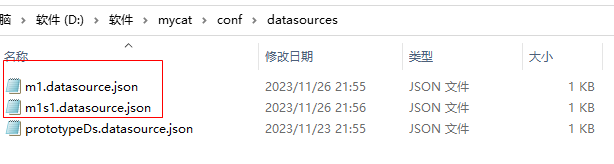
查询数据源信息如下

同时在文件夹中也生成了对应的配置文件
3)为主从节点搭建MyCat集群,在MyCat将主从节点关联起来
/*! mycat:createCluster{ "masters":[ "m1" ], "name":"zxh_test", "replicas":[ "m1s1" ] } */;
指定了主节点和从节点,集群名称是zxh_test,查询结果

可以看出,写操作只在m1中允许,读操作可以在m1和m1s1之间轮询。
4)创建逻辑库,用于指向集群
虽然上面已经配置好了集群,但如何去操作这个集群呢?这时可以创建一个数据库,这个库是逻辑库,关联到集群,那么后续只需要对这个逻辑库操作,就会转发到集群,集群再转发到主节点和从节点的逻辑数据源,这些逻辑数据源再分发到真实的数据库。这就是MyCat2的读写分离。
CREATE DATABASE test_demo DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
创建数据库(建议和真实数据库的库名一致)
5)指定逻辑库的集群名称MyCat2暂时还未提供命令方式关联集群名称,这就需要手动打开配置文件conf/schemas/test_demo.schema.json,在里面添加
"targetName":"zxh_test",
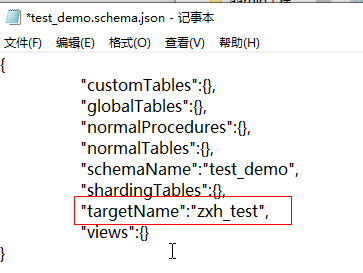
让逻辑库和集群进行对应,保存后重启MyCat2服务。
6)创建表进行测试
在MyCat中创建表并添加数据进行测试
use test_demo; CREATE TABLE `sys_enterprise` ( `id` int NOT NULL, `name` varchar(100) DEFAULT NULL, `ent_no` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; insert into sys_enterprise values(1,"武汉小米","A001"); insert into sys_enterprise values(2,"深圳腾讯小米","C001"); select * from sys_enterprise;
在真实的数据库中查询
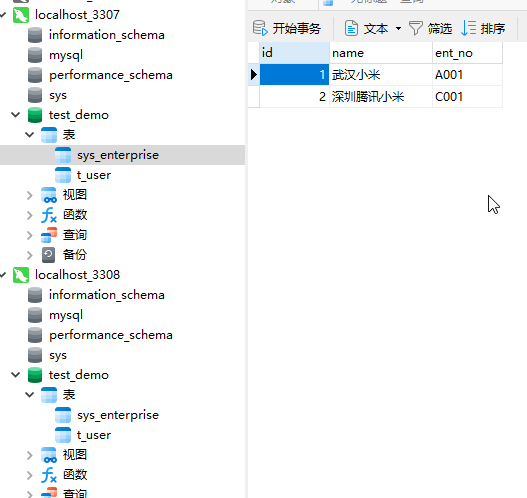
7)手动修改从节点真实库的数据(现实场景一般不允许直接修改从库数据),在MyCat2中查询,发现查询的数据会出现不一样的情况,这更好的体现了读操作是在主节点和从节点之间轮询。
从这里可以看出,并未对真实数据库操作,仅仅只是在MyCat进行操作,执行的SQL已按预期进行了读写操作,实现了读写分离。
6.MyCat2配置数据库集群(MySQL版)
--------待更新--------
前提:MySQL已完成主从复制的搭建。
按照主从复制的搭建方式,再搭建一套主从复制(一主两从),具体配置如下表:
| 节点名称 | ip(根据实际修改) | 端口 | 说明 |
| M1 | 172.18.80.1 | 3307 | 主节点 |
| M1S1 | 172.18.80.1 | 3308 | M1的从节点 |
| M2 | 172.18.80.1 | 3310 | 主节点 |
| M2S1 | 172.18.80.1 | 3311 | M2的从节点 |
| M2S2 | 172.18.80.1 | 3312 | M2的从节点 |
7.MyCat2实现分库分表(MySQL版)
--------待更新--------
