多线程面试题
本文共 3,214 字,预计阅读时间 11 分钟
1.多线程的主要参数有哪些,有什么用?
1)corePoolSize(核心线程数)
指的是长期存活的线程数。比如地主家的长工,无论这一年活多还是活少,都不会被辞退。
2)maximumPoolSize(最大线程数)
指的是线程池允许创建的最大线程数,其中包含核心线程数(最大线程数 >= 核心线程数)。比如地主家临时活太多,长工干不完,就找临时工来帮忙,那么最大线程数=长工数量+临时工数量。
3)keepAliveTime(空闲线程存活时间)
指的是空闲线程的存活时间。主要是当线程池中没有任务时,会销毁一批线程,减少资源的浪费。销毁的线程数=最大线程数-核心线程数。
4)unit(时间单位)
指的是空闲线程的存活时间的单位,包括天、小时、分钟、秒...
5)workQueue(线程任务池队列)
也叫阻塞队列,指的是线程池存放任务的队列,用来存放线程池中所有待执行的任务。常用的是由链表组成的有界阻塞队列(LinkedBlockingQueue)。
6)threadFactory(线程工厂)
指的是线程池创建线程时调用的工厂方法,通过此方法可以设置线程命名规则及优先级等信息。


public static void main(String[] args) { // 创建线程工厂 ThreadFactory threadFactory = new ThreadFactory() { @Override public Thread newThread(Runnable r) { // 创建线程池中的线程 Thread thread = new Thread(r); // 设置线程名称 thread.setName("线程-" + r.hashCode()); // 设置线程优先级 thread.setPriority(Thread.MAX_PRIORITY); // 设置线程类型(守护线程、用户线程), false-用户线程 thread.setDaemon(false); return thread; } }; ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(), threadFactory); threadPoolExecutor.submit(new Runnable() { @Override public void run() { Thread thread = Thread.currentThread(); System.out.println(String.format("线程: %s, 线程优先级: %d", thread.getName(), thread.getPriority())); } }); }
7)handler(拒绝策略)
当线程池中的任务超过阻塞队列可存储的最大值时,采用的拒绝策略。
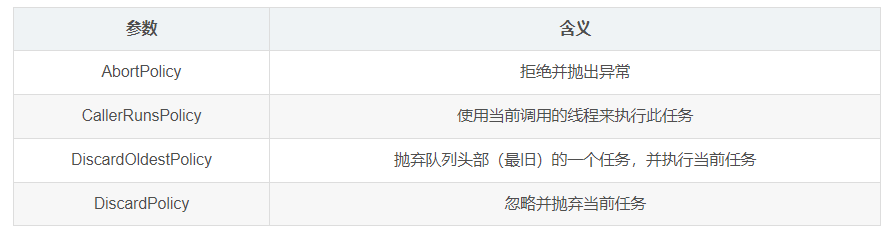
其默认的拒绝策略是AbortPolicy–拒绝并抛出异常。
2.线程池提交一个任务的流程是什么样的?
其流程图如下
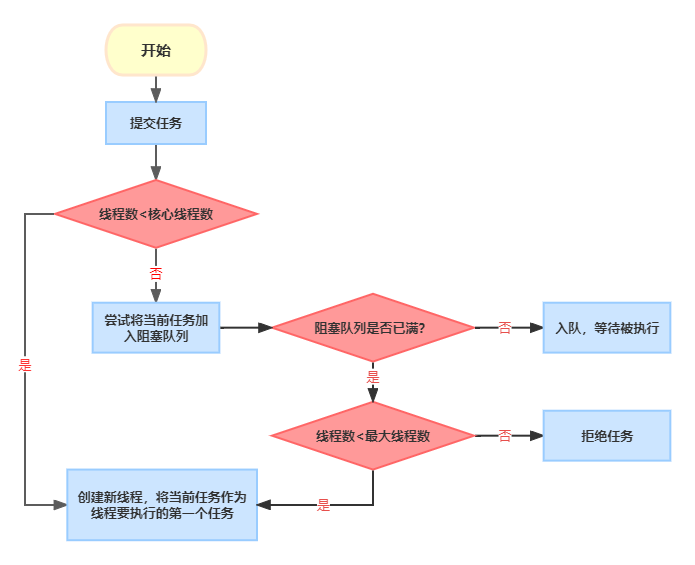
当提交一个新任务(Runnable)时,会进行以下的步骤(也是原理):
1)如果线程数小于核心线程数,则直接创建新的线程,并将当前任务作为要执行的第一个任务;
2)如果线程数大于等于核心线程数,则会尝试将当前任务加入到阻塞队列,在加入时也需要判断阻塞队列是否已满;
3)如果阻塞队列未满,则直接将任务入队,其即可等待被执行;
4)如果阻塞队列已满,则判断线程数是否大于最大线程数;
5)如果线程数大于等于最大线程数则会通过 handler所指定的策略来处理此任务;
6)如果线程数小于最大线程数则,则会创建新的线程,并将当前任务作为要执行的第一个任务。
如果线程数大于核心线程数,并且有线程的空闲时间超过了设置的存活时间,那么这些线程会被销毁。
3.阻塞队列的作用是什么?为什么是先添加队列而不是先创建最大线程?
作用:
可以保证阻塞队列中没有任务时阻塞 获取任务的线程,使线程进入wait状态,释放CPU资源;
另外,阻塞队列自带阻塞和唤醒功能,不需要额外处理,当无任务时,线程池利用阻塞队列的take()挂起,只维持核心线程的存活,不至于一直占用CPU资源。
先添加队列再创建最大线程:
因为在创建线程时,会获取全局锁,这时其他的线程就被阻塞了,影响了整体的效率。因此,把创建最大线程放在了后面,先让其入队,如果队列满了才会创建线程。阻塞队列分担了一些任务,那么就减少了线程的创建所造成的资源消耗,提高了效率。
比如⼀个企业⾥⾯有10个(core)正式⼯的名额,最多招10个正式⼯,要是任务超过正式⼯⼈数(task > core)的情况下,⼯⼚领导(线程池)不是⾸先扩招⼯⼈,还是这10⼈,但是任务可以稍微积压⼀下,即先放到队列去(代价低)。10个正式⼯慢慢⼲,迟早会⼲完的,要是任务还在继续增加,超过正式⼯的加班忍耐极限了(队列满了),就的招外包帮忙了(注意是临时⼯)要是正式⼯加上外包还是不能完成任务,那新来的任务就会被领导拒绝了(线程池的拒绝策略)。
4.线程池中线程复⽤原理
同一个线程可以从阻塞队列中不断获取任务来执行,其核心在于线程池对Thread进行了封装,并不是每次执行任务都会调用Thread.start()方法,而是让每一个线程去执行一个“循环任务”,这个循环任务不停的检测是否有任务需要执行,如果有则直接执行,调用run()方法。通过这种方式就减少了频繁的创建线程造成的资源浪费,提高了效率。
5.核心线程数,最大线程数怎么设置?
线程数设置和CPU的核数是相关的,不同类型的任务,设置的方式不同。线程池执行的任务分为三种情况:
1)CPU密集型任务:存在大量的计算。核心线程数=CPU核数+1,最大线程数=CPU数量+1。(CPU核数和CPU数量是不同的)
正常情况下核心线程数等于CPU核数是最佳的,但会存在某个线程因意外情况发生中断,那么此时多出的一个线程就可以继续利用此CPU,这样效率是最高的,故核心线程数比CPU核数多1。
2)IO密集型任务:主要是IO操作,如文件IO和网络IO。核心线程数=CPU核数*2,最大线程数=CPU数量*2+1。
执行IO操作是比较耗时的,当某些线程在阻塞时,其对应的CPU就可以去执行其他的线程,通常核心数是CPU核数的2倍。但也不是绝对的,因为有可能这2倍的线程全被阻塞。当然下面的计算公式更为合适:核心线程数=CPU核数*(1+线程等待时间(也叫阻塞时间) / 线程运行总时间)。
3)复合型任务
6.如何优雅的停止一个线程?
一般不会使用stop()来停止线程,这种方式简单粗暴,不知道线程执行到哪一步了,该释放的锁都释放了吗?这都是未知的,所以通常使用interrupted()来中断线程,然后在创建线程的内部根据线程中断的标志来判断业务逻辑是否结束。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 记一次.NET内存居高不下排查解决与启示