Redis之性能优化,你用了几个
本文共 2,477 字,预计阅读时间 8 分钟
在使用redis作为缓存时,为提供查询数据和效率,优化也是必不可少的。
1.强化开发规范
1)不使用bigkey:即key对应的value的值不能太大。对于String类型,value超过10KB即为bigkey;对于非字符串类型,其元素超过5000个即为bigkey。
2)key命名优化:所有的key尽量以业务名为前缀,使用冒号分隔,但要保持简洁,同时不能包含特殊字符(空格,单引号,转义符,换行等)。示例

product:stock:1001
表示产品为1001的库存。
2.设置过期时间
比如商品数据,在创建时会根据商品ID存入到redis,当修改时也会同步更新到redis,那么在查询时先会根据商品ID去redis查询,若存在就直接返回,若不存在就从数据库查询后返回,与此同时会存入redis。因此也就提高了查询速度,降低了数据库的压力。但对于上千万的数据,全部都存如redis是不现实的。
其实很简单,只需在加入缓存时,都设置一个过期时间,如24小时。这样一来,redis中的商品数据便是热点商品。另外,在查询时,若直接从缓存中获取,建议给其进行续期处理(再设置一次过期时间),避免后期在查询时因过期而从数据库查询。
3.缓存穿透
指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
那么如何解决这种问题呢?既然是因为缓存中不存在商品信息进而转向数据库查询,那么就从根源开始。
方案一:当第一次查询到数据库中不存在该商品时,将商品ID作为key,value为一个特定的值来标明是空数据(如isEmpty,当然也需要设置过期时间)。那么后续的请求在查询时,若查询到缓存中有数据,先判断是否是空数据(isEmpty),若是空数据则直接返回null或以实际场景未知进行无数据返回,若有数据则返回数据即可。但是这种方式,增加了内存的消耗,也会导致数据的不一致,因为如果后续创建了此数据后,缓存中仍然是空值。
方案二:使用布隆过滤器。其流程如下:
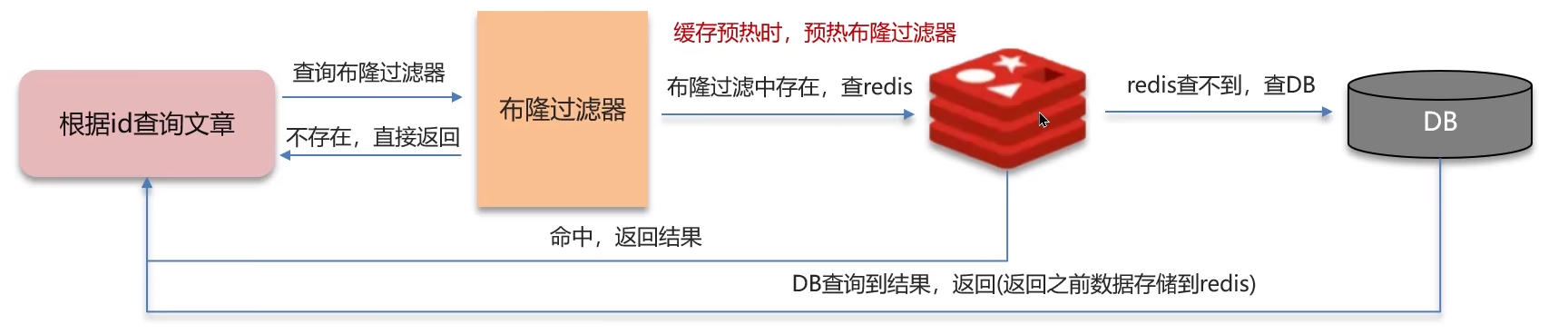
布隆过滤器的主要作用就是拦截不存在的数据,在缓存预热时(存入缓存时)也往布隆过滤器存一份。主要是把key进行多次hash获取hash值,将其存入位图(位图:以bit为单位的数组,只能存放二进制0或1)中,而布隆过滤器就来检索key是否在这个数组中。
4.缓存击穿
某一个热点数据在缓存中过期,而在该热点数据重建缓存之前,有大量的请求过来,压力会同时转向数据库,这种现象叫做缓存击穿。
那么如何解决这种问题呢?有两种方式,一是添加互斥锁,二是这是逻辑过期。
1)互斥锁:给过期的热点的key添加互斥锁,一次只允许一个线程操作。也就是说,有多个线程同时请求时,让其中的一个线程添加互斥锁,让其进行缓存重建,直至缓存重建完成才释放此锁。在此期间,其他线程就一直重试获取数据,在锁释放后即可获取最新缓存的数据。但这种方式性能很低,不过数据可以保证强一致性。
2)逻辑过期:在添加缓存时,给每个数据添加一个字段,用来标识过期时间,而这些缓存不再设置过期时间。当多个线程同时请求时,判断此字段是否过期,如果过期就让其中一个线程进行缓存的重建,而其他线程先获取已过期的数据进行返回。进行缓存重建的线程,也是需要先获取互斥锁,然后新开一个线程异步进行真正的缓存重建,然后释放锁,而原线程开启线程后即可进行返回过期数据。这种方式性能高,但数据会存在一定的误差。
5.缓存雪崩
在同一时刻有大量的缓存key同时失效或redis宕机,压力会同时转向数据库,这种现象叫做缓存雪崩。
根源是同时失效,那么只需要给这些key设置不同的过期时间即可,如果需要设置相同的过期时间,那么可以给这些时间再添加一个允许范围内的随机时间。如果条件允许的情况下,可以对redis进行集群部署,或者进行服务降级限流处理。
6.双写一致性问题
修改数据库的同时也需要修改缓存,使得数据库的数据和缓存保持一致。问题主要出现在更新数据上,下面看两种操作:
1)读操作:若缓存命中,则直接返回;若缓存未命中,则查询数据库并把数据写入缓存。
2)写操作:常用的方式就是删除缓存,然后更新数据库。
那么对于这种情况,就有几种情况了(假设有两个线程同时请求,分别是线程1和线程2,在正常情况下,是不会出现问题的,但在特殊的情况下,就出现了数据不一致问题:
A:先删除缓存,再更新数据库。【特殊情况·写写】当线程1删除了数据,正准备更新数据库时由于某种原因被线程2抢占了资源,那么线程2发现没有数据,就会把数据库中还未更新的数据写入缓存。然后线程1才更新完成数据,那么已经导致了数据不一致。
B:先更新数据库,再删除缓存。【特殊情况·读写】当线程1查询数据时由于未命中,则把数据库中还未更新的数据查询出来,正准备写入缓存时由于某种原因被线程2抢占了资源,那么线程2更新数据库并删除了缓存,然后线程1缓存也写入完成,那么已经导致了数据不一致。
如何解决上述的问题呢?那就需要用到延迟双删。
![]()
为什么要进行两次删除呢?显然,上述情况A只用一次删除会存在脏数据,只需要在更新数据后延迟再删除一次缓存即可,延迟的原因是数据库是主从架构,数据的主从复制是需要一定的时间。原因很简单,由于线程2把未更新的数据写入缓存后线程1才更新数据,那么这种情况下,在更新完成后只需要把线程1造成的不正确的缓存删除,那么在下次查询时,由于未命中则会再去数据库查询并存入缓存,此时数据就保证了一致。不过这种方式也不能完全保证数据的一致性,因为延时时间不好控制,但是可以减少大量的脏数据。
如果需要保证强一致性,那么可以使用redisson读写锁。
还有一种方式是使用异步通知保证数据的最终一致性。也就是使用MQ,先更新数据库,然后给mq发送消息,缓存服务接收到消息后再存入缓存,从而保证数据的最终一致性。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!