沉淀,再出发:结合案例看python
沉淀,再出发:结合案例看python
一、前言
关于python,如果不经过大型程序开发的洗礼,我们很难说自己已经懂得了python了,因此,我们需要通过稍微结构化的编程来学习python。
二、一个案例
首先我们看一下需要具备的前提知识。
2.1、新建pandas表格
man_num = 100
women_num = 100
pd.DataFrame( [['w'+str(i) for i in random.sample(range(1,women_num+1),women_num)] for j in range(man_num)], index = ['m'+str(i) for i in range(1,man_num+1)], columns = ['level'+str(i) for i in range(1,women_num+1)] )
通过上述的方式,我们创建出了一个表格:

其中random的sample方法,我们可以从下面的例子中理解,在上面就是挑选自身的一种置换来填充每一个单元,for j in range(man_num)其实就是重复多少行的意思:
import random list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] for i in range(3): slice = random.sample(list, 5) # 从list中随机获取5个元素,作为一个片断返回 print(slice) print(list, '\n') # 原有序列并没有改变

2.2、reset_index()和to_csv()
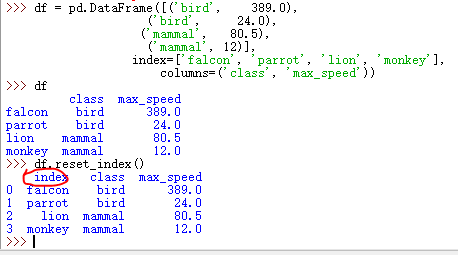
def to_csv(self, path=None, index=True, sep=",", na_rep='', float_format=None, header=False, index_label=None, mode='w', encoding=None, compression=None, date_format=None, decimal='.'): """ Write Series to a comma-separated values (csv) file Parameters ---------- path : string or file handle, default None File path or object, if None is provided the result is returned as a string. na_rep : string, default '' Missing data representation float_format : string, default None Format string for floating point numbers header : boolean, default False Write out series name index : boolean, default True Write row names (index) index_label : string or sequence, default None Column label for index column(s) if desired. If None is given, and `header` and `index` are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex. mode : Python write mode, default 'w' sep : character, default "," Field delimiter for the output file. encoding : string, optional a string representing the encoding to use if the contents are non-ascii, for python versions prior to 3 compression : string, optional A string representing the compression to use in the output file. Allowed values are 'gzip', 'bz2', 'zip', 'xz'. This input is only used when the first argument is a filename. date_format: string, default None Format string for datetime objects. decimal: string, default '.' Character recognized as decimal separator. E.g. use ',' for European data """ from pandas.core.frame import DataFrame df = DataFrame(self) # result is only a string if no path provided, otherwise None result = df.to_csv(path, index=index, sep=sep, na_rep=na_rep, float_format=float_format, header=header, index_label=index_label, mode=mode, encoding=encoding, compression=compression, date_format=date_format, decimal=decimal) if path is None: return result
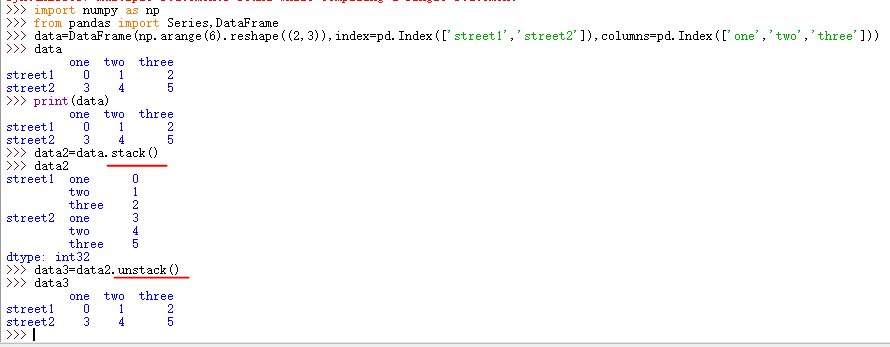
2.3、stack()和unstack()
在用pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”。常见的数据的层次化结构有两种,一种是表格,一种是“花括号”,即下面这样的l两种形式:
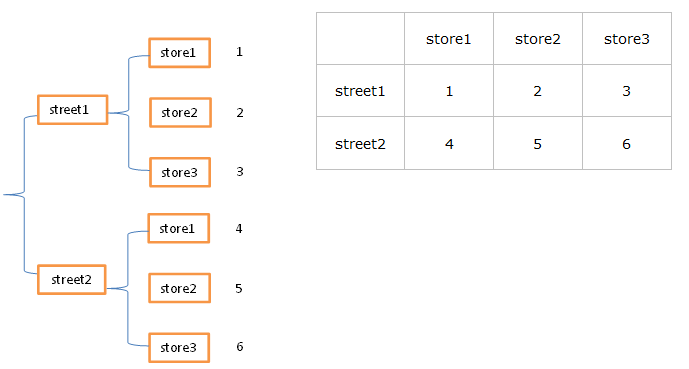
表格在行列方向上均有索引(类似于DataFrame),花括号结构只有“列方向”上的索引(类似于层次化的Series),结构更加偏向于堆叠(Series-stack,方便记忆)。stack函数会将数据从”表格结构“变成”花括号结构“,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构“变成”表格结构“,即要将其中一层的列索引变成行索引。
import numpy as np import pandas as pd from pandas import Series,DataFrame data=DataFrame(np.arange(6).reshape((2,3)),index=pd.Index(['street1','street2']),columns=pd.Index(['one','two','three'])) print(data) print('-----------------------------------------\n') data2=data.stack() data3=data2.unstack() print(data2) print('-----------------------------------------\n') print(data3)
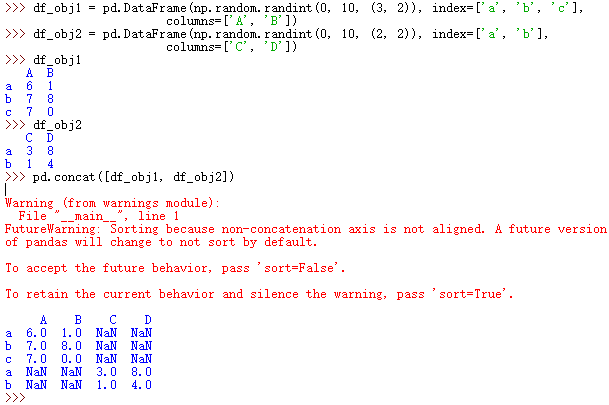
2.4、DataFrame上的concat()
2.5、案例
1 有一座城市,当地风俗是,想结婚的男子必须先向心仪的女子求婚,而女子则需要等待求婚。 2 牧师每年会邀请人数相同的适婚男女参与一次集体相亲。一次相亲活动可能有很多轮,男子会首先向自己最爱的女子求婚,女子则会在所有的追求者中选择她的最爱;
如果男子被拒绝,下一轮会向他第二喜欢的女子求婚;上一轮已经订婚的女子如果得到她更爱的人的求婚,则会毫不留情地抛弃未婚夫,和更爱的人在一起。
被抛弃的男子需要重新参与求婚。如此反复,等大家都订婚,就举办集体婚礼。 3 假设: 4 1)参加求婚的男女数量保持一致 5 2)每个男子都按喜爱程度对女子进行排序,比如最爱a,其次爱b,再次爱c 6 3)每个女子也同样给每个男子排序
2.6、安装 pyecharts和pyecharts_snapshot
2.7、创造样例
1 import pandas as pd 2 import random 3 4 from configuration import MAN_NUM,WOMAN_NUM 5 6 7 def create_sample(): 8 man_num = MAN_NUM 9 women_num = WOMAN_NUM 10 11 #设置男女生喜好样本 12 print('==============================生成样本数据==============================') 13 man = pd.DataFrame( [['w'+str(i) for i in random.sample(range(1,women_num+1),women_num)] \ 14 for i in range(man_num)], 15 index = ['m'+str(i) for i in range(1,man_num+1)], 16 columns = ['level'+str(i) for i in range(1,women_num+1)] 17 ) 18 19 women = pd.DataFrame( [['m'+str(i) for i in random.sample(range(1,man_num+1),man_num)] \ 20 for i in range(women_num)], 21 index = ['w'+str(i) for i in range(1,women_num+1)], 22 columns = ['level'+str(i) for i in range(1,man_num+1)] 23 ) 24 return (man,women) 25 26 if __name__ == '__main__': 27 create_sample(man,women)
2.8、生成映射表
1 import pandas as pd 2 3 #设置姻缘关系表 4 def create_mapping_table(man,women): 5 6 man_ismapping = pd.DataFrame({ 7 'man_id':man.index, 8 'target':'n', 9 'love_level':0, 10 'range':0 11 }).set_index('man_id') 12 13 women_ismapping = pd.DataFrame({ 14 'women_id':women.index, 15 'target':'n', 16 'love_level':0, 17 'range':0 18 }).set_index('women_id') 19 return (man_ismapping,women_ismapping) 20 21 if __name__ == '__main__': 22 create_mapping_table(man,women)
2.9、创建目录,完成初始化
1 from configuration import TEST_NUM 2 import os 3 from scr.create_sample import create_sample 4 from scr.create_mapping_table import create_mapping_table 5 import pandas as pd 6 7 def loop_script(): 8 test_num = TEST_NUM 9 if not os.path.exists('./data'): 10 os.makedirs('./data') 11 12 for i in range(1,test_num+1): 13 print('==============================开始创建测试文件夹{}=============================='.format(i)) 14 path = './data/test' + str(i) 15 if not os.path.exists(path): 16 os.makedirs(path) 17 sample_data = create_sample() 18 man = sample_data[0] 19 women = sample_data[1] 20 man.reset_index().to_csv(path+'/'+'man_sample.csv', index=0) 21 women.reset_index().to_csv(path+'/'+'woman_sample.csv', index=0) 22 print('==============================样本数据生成成功==============================') 23 print('==============================创建婚姻关系表==============================') 24 man = pd.read_csv(path+'/'+'man_sample.csv').set_index('index') 25 women = pd.read_csv(path+'/'+'woman_sample.csv').set_index('index') 26 mapping_data = create_mapping_table(man, women) 27 man_ismapping = mapping_data[0] 28 women_ismapping = mapping_data[1] 29 man_ismapping.reset_index().to_csv(path+'/'+'man_ismapping.csv', index=0) 30 women_ismapping.reset_index().to_csv(path+'/'+'women_ismapping.csv', index=0) 31 print('==============================婚姻关系表创建完成==============================')
2.10、业务逻辑计算
1 import pandas as pd 2 from configuration import TEST_NUM 3 4 def calculation(): 5 test_num = TEST_NUM 6 for i in range(1,test_num+1): 7 path = './data/test' + str(i) 8 man = pd.read_csv(path + '/' + 'man_sample.csv').set_index('index') 9 women = pd.read_csv(path + '/' + 'woman_sample.csv').set_index('index') 10 man_ismapping = pd.read_csv(path + '/' + 'man_ismapping.csv').set_index('man_id') 11 women_ismapping = pd.read_csv(path + '/' + 'women_ismapping.csv').set_index('women_id') 12 print('==============================测试集{}模拟开始=============================='.format(i)) 13 print('==============================开始模拟求婚过程==============================') 14 level_num = 0 15 while man_ismapping['love_level'].min() == 0: 16 level_num += 1 17 print('==============================开始第{}天婚姻配对=============================='.format(level_num)) 18 u_mapping_man = man_ismapping[man_ismapping.target == 'n'].index.tolist() 19 20 if level_num < 2: 21 level_col = 'level' + str(level_num) 22 man_choose = man[man.index.isin(u_mapping_man)][level_col].to_frame().reset_index() 23 man_choose.columns = ['man_id', 'women_id'] 24 man_choose['range'] = 1 25 else: 26 m_id = u_mapping_man 27 l = [] 28 for man_id in m_id: 29 col_n = int(man_ismapping[man_ismapping.index == man_id].range[0]) 30 level_col = 'level' + str(col_n + 1) 31 women_id = man[man.index == man_id][level_col][0] 32 rg = col_n + 1 33 l.append([man_id, women_id, rg]) 34 man_choose = pd.DataFrame(l, columns=['man_id', 'women_id', 'range']) 35 36 for r in range(0, len(man_choose)): 37 relationship = man_choose[man_choose.index == r] 38 m = [i for i in relationship['man_id']][0] 39 w = [i for i in relationship['women_id']][0] 40 find = women[women.index == w].unstack().reset_index() 41 find.columns = ['level', 'women_id', 'man_id'] 42 find = int([i for i in find[find['man_id'] == m]['level']][0].split('level')[1]) 43 o_love_level = [i for i in women_ismapping[women_ismapping.index == w]['love_level']][0] 44 rg = [i for i in relationship['range']][0] 45 if o_love_level == 0: 46 women_ismapping.loc[w, 'love_level'] = find 47 women_ismapping.loc[w, 'target'] = m 48 women_ismapping.loc[w, 'range'] = level_num 49 man_ismapping.loc[m, 'love_level'] = rg 50 man_ismapping.loc[m, 'target'] = w 51 man_ismapping.loc[m, 'range'] = rg 52 elif o_love_level > find: 53 m_o = women_ismapping.loc[w, 'target'] 54 man_ismapping.loc[m_o, 'love_level'] = 0 55 man_ismapping.loc[m_o, 'target'] = 'n' 56 man_ismapping.loc[m, 'love_level'] = rg 57 man_ismapping.loc[m, 'target'] = w 58 man_ismapping.loc[m, 'range'] = rg 59 women_ismapping.loc[w, 'love_level'] = find 60 women_ismapping.loc[w, 'target'] = m 61 women_ismapping.loc[w, 'range'] = level_num 62 else: 63 man_ismapping.loc[m, 'range'] = rg 64 pass 65 66 print('==============================婚姻配对完成==============================') 67 print('共进行了{}次牵线搭桥,在第{}天举办集体婚礼。'.format(level_num, level_num + 1)) 68 69 print('==============================导出配对明细表==============================') 70 man_love_level_mean = man_ismapping.love_level.mean() 71 women_love_level_mean = women_ismapping.love_level.mean() 72 detail = [[level_num,level_num,man_love_level_mean,women_love_level_mean]] 73 pd.DataFrame(detail,columns=['match_range','party_time','man_love_level_mean','women_love_level_mean'])\ 74 .to_csv(path+'/'+'test_detail.csv', index=0) 75 man_ismapping.reset_index().to_csv(path+'/'+'man_match_table.csv', index=0) 76 women_ismapping.reset_index().to_csv(path+'/'+'woman_match_table.csv', index=0) 77 print('==============================导出完毕==============================') 78 79 if __name__ == '__main__': 80 calculation()
2.11、绘制图表
1 import pandas as pd 2 from configuration import TEST_NUM 3 from pyecharts import Bar 4 import matplotlib.pyplot as plt 5 import warnings 6 warnings.filterwarnings("ignore") 7 8 def drawing(): 9 test_num = TEST_NUM 10 l_table = [] 11 for i in range(1,test_num+1): 12 path = './data/test' + str(i) 13 man_match_table = pd.read_csv(path + '/' + 'man_match_table.csv').set_index('man_id') 14 woman_match_table = pd.read_csv(path + '/' + 'woman_match_table.csv').set_index('women_id') 15 16 man_match_table = man_match_table.groupby('love_level').count()['range'].sort_values(ascending=False) 17 woman_match_table = woman_match_table.groupby('love_level').count()['range'].sort_values(ascending=False) 18 19 man_attr = man_match_table.index.tolist() 20 man_v = man_match_table.values.tolist() 21 bar_man = Bar('男生匹配对象喜爱程度分布',width=900,height=500) 22 bar_man.add('频数',man_attr,man_v,mark_line=["max"],label_color = ['#9932CC']) 23 bar_man.render(path + '/' + '男生匹配对象喜爱程度分布.html') 24 25 women_attr = woman_match_table.index.tolist() 26 women_v = woman_match_table.values.tolist() 27 bar_women = Bar('女生匹配对象喜爱程度分布',width=900,height=500) 28 bar_women.add('频数',women_attr,women_v,mark_line=["max"],label_color = ['#FF3030']) 29 bar_women.render(path + '/' + '女生匹配对象喜爱程度分布.html') 30 31 detail = pd.read_csv(path + '/' + 'test_detail.csv') 32 l_table.append(detail) 33 detail_table = pd.concat(l_table) 34 s_match_range = detail_table['match_range'] 35 s_man_love_level_mean = detail_table['man_love_level_mean'] 36 women_love_level_mean = detail_table['women_love_level_mean'] 37 fig = plt.figure(figsize=(10, 6), facecolor='gray') 38 ax1 = fig.add_subplot(2, 2, 1) 39 ax1.hist(s_match_range,bins = 20, 40 histtype = 'bar', 41 align = 'mid', 42 orientation = 'vertical', 43 alpha=0.5, 44 normed =False 45 ) 46 plt.grid(True) 47 ax2 = fig.add_subplot(2, 2, 2) 48 ax2.hist(s_man_love_level_mean, bins=20, 49 histtype='bar', 50 align='mid', 51 orientation='vertical', 52 alpha=0.5, 53 normed=False 54 ) 55 plt.grid(True) 56 ax3 = fig.add_subplot(2, 2, 3) 57 ax3.hist(women_love_level_mean, bins=20, 58 histtype='bar', 59 align='mid', 60 orientation='vertical', 61 alpha=0.5, 62 normed=False 63 ) 64 plt.grid(True) 65 plt.savefig('./data/detail_graph.png',dpi=400) 66 plt.show() 67 print('==========================制图完成==========================')
2.12、配置文件和程序入口
1 #基本参数配置 2 3 #MAN_NUM:男生样本数量 4 #WOMAN_NUM:女生样本数量 5 #TEST_NUM:测试次数 6 7 8 MAN_NUM = 100 9 WOMAN_NUM = 100 10 TEST_NUM = 50
1 from scr.loop_script import loop_script 2 from scr.calculation import calculation 3 from scr.drawing import drawing 4 5 if __name__ == '__main__': 6 loop_script() 7 calculation() 8 drawing() 9 print('========================================任务结束========================================')
三、总结
通过一个案例,我们更好的理解了python的相关语法和应用,以及结合其他工具的强大的绘图能力和表达能力,对语言的高度浓缩和精炼等等。

