沉淀,再出发:python中的pandas包
沉淀,再出发:python中的pandas包
一、前言
python中有很多的包,正是因为这些包工具才使得python能够如此强大,无论是在数据处理还是在web开发,python都发挥着重要的作用,下面我们看一下python用于数据处理的pandas包以及相应的用法。
二、pandas的使用
2.1、pandas简介
Numpy、Matplotlib,Pandas是Python科学计算的支柱。
NumPy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。Numpy内部解除了Python的PIL(全局解释器锁),运算效率极好,是大量机器学习框架的基础库!
全局解释器锁(Global Interpreter Lock)是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻仅有一个线程在执行。
1、Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
2、Pandas 是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)
和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
3、数据结构:
Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。
Time-Series:以时间为索引的Series。
DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
Panel :三维的数组,可以理解为DataFrame的容器。
Pandas 有两种自己独有的基本数据结构。读者应该注意的是,它固然有着两种数据结构,因为它依然是 Python 的一个库,所以,Python 中有的数据类型在这里依然适用,也同样还可以使用类自己定义数据类型。只不过,Pandas 里面又定义了两种数据类型:Series 和 DataFrame,它们让数据操作更简单了。
2.2、pandas的安装
首先还是使用pip这个包管理工具来下载并自动安装pandas:

Pandas基于两种数据类型:Series与dataframe。
一个series是一个一维的数据类型,其中每一个元素都有一个标签。如果阅读过关于Numpy的文章,就可以发现series类似于Numpy中元素带标签的数组。其中,标签可以是数字或者字符串。
一个dataframe是一个二维的表结构。Pandas的dataframe可以存储许多种不同的数据类型,并且每一个坐标轴都有自己的标签。你可以把它想象成一个series的字典项。
2.3、Series
之后我们打开python命令行来测试一下:导入pandas模块并使用别名,以及导入Series模块,以下使用基于本次导入。
from pandas import Series
import pandas as pd
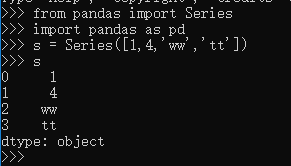
Series 就如同列表一样,一系列数据,每个数据对应一个索引值。Series 就是“竖起来”的 list,这里,我们实质上创建了一个 Series 对象,这个对象当然就有其属性和方法了。比如,下面的两个属性依次可以显示 Series 对象的数据值和索引:

列表的索引只能是从 0 开始的整数,Series 数据类型在默认情况下,其索引也是如此。不过,区别于列表的是,Series 可以自定义索引:
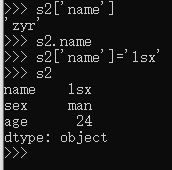
每个元素都有了索引,就可以根据索引操作元素了。Series 中,根据索引查看其值和修改其值:
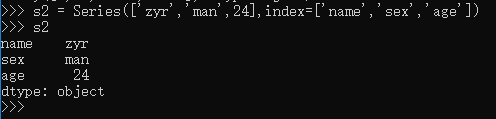
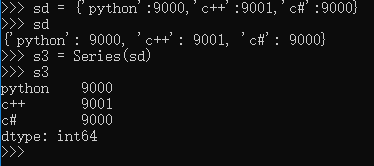
前面定义 Series 对象的时候,用的是列表,即 Series() 方法的参数中,第一个列表就是其数据值,如果需要定义 index,放在后面,依然是一个列表。除了这种方法之外,还可以用下面的方法定义 Series 对象:
这时候,索引依然可以组装成新的对象,Pandas 的优势在这里体现出来,如果自定义了索引,自定的索引会自动寻找原来的索引,如果一样的,就取原来索引对应的值,这个可以简称为“自动对齐”,在 Pandas 中,如果没有值,都对齐赋给 NaN。
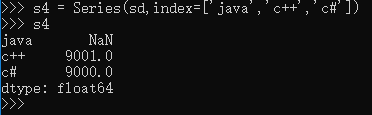
pandas有判断是否为空的方法,此外,Series 对象也有同样的方法:

其实,对索引的名字,是可以重新定义的:
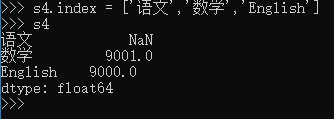
对于 Series 数据,也可以做类似下面的运算:

2.4、DataFrame
DataFrame 是一种二维的数据结构,非常接近于电子表格或者类似 mysql 数据库的形式。它的竖行称之为 columns,横行跟前面的 Series 一样,称之为 index,也就是说可以通过 columns 和 index 来确定一个主句的位置。
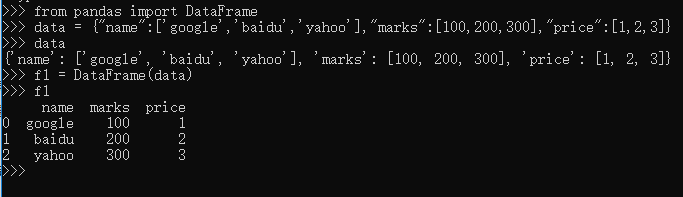
使用 dict是定义一个 DataFrame 对象的常用方法。字典的“键”("name","marks","price")就是 DataFrame 的 columns 的值(名称),字典中每个“键”的“值”是一个列表,它们就是那一竖列中的具体填充数据。上面的定义中没有确定索引,所以,按照惯例(Series 中已经形成的惯例)就是从 0 开始的整数。从上面的结果中很明显表示出来,这就是一个二维的数据结构。
DataFrame 数据的索引也能够自定义,定义 DataFrame 的方法,除了上面的之外,还可以使用“字典套字典”的方式。


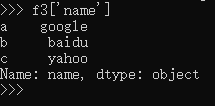
给同一列赋值:
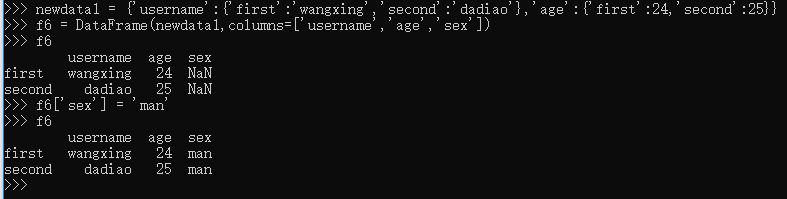
也可以单独的赋值,除了能够统一赋值之外,还能够“点对点”添加数值,结合前面的 Series,既然 DataFrame 对象的每竖列都是一个 Series 对象,那么可以先定义一个 Series 对象,然后把它放到 DataFrame 对象中。如下:

还可以更精准的修改数据,完全仿照字典的操作:
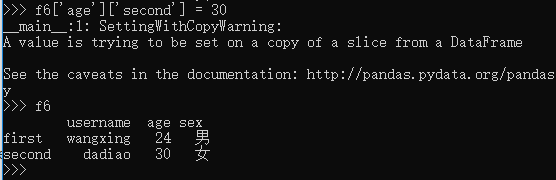
上面的所有操作:


>>> from pandas import Series >>> import pandas as pd >>> s = Series([1,4,'ww','tt']) >>> s 0 1 1 4 2 ww 3 tt dtype: object >>> s.index RangeIndex(start=0, stop=4, step=1) >>> s.values array([1, 4, 'ww', 'tt'], dtype=object) >>> s2 = Series(['zyr','man',24],index=['name','sex','age']) >>> s2 name zyr sex man age 24 dtype: object >>> s2['name'] 'zyr' >>> s2.name >>> s2['name']='lsx' >>> s2 name lsx sex man age 24 dtype: object >>> sd = {'python':9000,'c++':9001,'c#':9000} >>> sd {'python': 9000, 'c++': 9001, 'c#': 9000} >>> s3 = Series(sd) >>> s3 python 9000 c++ 9001 c# 9000 dtype: int64 >>> s4 = Series(sd,index=['java','c++','c#']) >>> s4 java NaN c++ 9001.0 c# 9000.0 dtype: float64 >>> pd.isnull(s4) java True c++ False c# False dtype: bool >>> s4.isnull() java True c++ False c# False dtype: bool >>> s4.index = ['语文','数学','English'] >>> s4 语文 NaN 数学 9001.0 English 9000.0 dtype: float64 >>> s4*2 语文 NaN 数学 18002.0 English 18000.0 dtype: float64 >>> s4[s4 > 9000] 数学 9001.0 dtype: float64 >>> from pandas import DataFrame >>> data = {"name":['google','baidu','yahoo'],"marks":[100,200,300],"price":[1,2,3]} >>> data {'name': ['google', 'baidu', 'yahoo'], 'marks': [100, 200, 300], 'price': [1, 2, 3]} >>> f1 = DataFrame(data) >>> f1 name marks price 0 google 100 1 1 baidu 200 2 2 yahoo 300 3 >>> f3 = DataFrame(data,columns=['name','marks','price'],index=['a','b','c']) >>> f3 name marks price a google 100 1 b baidu 200 2 c yahoo 300 3 >>> newdata = {'lang':{'first':'python','second':'java'},'price':{'first':5000,'second':2000}} >>> f4=DataFrame(newdata) >>> f4 lang price first python 5000 second java 2000 >>> newdata = {"lang":{"firstline":"python","secondline":"java"}, "price":{"firstline":8000}} >>> f4 = DataFrame(newdata) >>> f4 lang price firstline python 8000.0 secondline java NaN >>> f3['name'] a google b baidu c yahoo Name: name, dtype: object >>> newdata1 = {'username':{'first':'wangxing','second':'dadiao'},'age':{'first':24,'second':25}} >>> f6 = DataFrame(newdata1,columns=['username','age','sex']) >>> f6 username age sex first wangxing 24 NaN second dadiao 25 NaN >>> f6['sex'] = 'man' >>> f6 username age sex first wangxing 24 man second dadiao 25 man >>> ssex = Series(['男','女'],index=['first','second']) >>> ssex first 男 second 女 dtype: object >>> f6['sex'] = ssex >>> f6 username age sex first wangxing 24 男 second dadiao 25 女 >>> f6['age']['second'] = 30 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy >>> f6 username age sex first wangxing 24 男 second dadiao 30 女
三、pandas的综合应用
3.1、读取文件
pandas更强大的是对文件(.xlsx,csv)的读取(可以从本地和远程读取)和使用:
注意:这里读取.xlsx需要使用pd.read_excel(文件名),安装依赖xlrd。

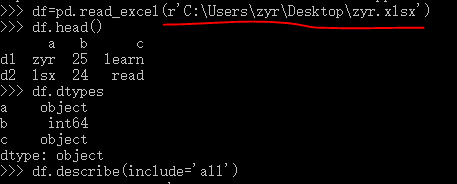
1 >>> import pandas as pd 2 >>> import numpy as np 3 >>> data_url = "https://raw.githubusercontent.com/alstat/Analysis-with-Programming/master/2014/Python/Numerical-Descriptions-of-the-Data/data.csv" 4 >>> df = pd.read_csv(data_url)
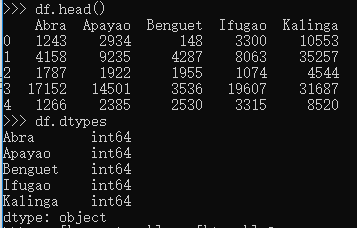

csv和xlsx分别用read_csv和read_xlsx
查看数据df.head() :默认出5行,括号里可以填其他数据
查看数据类型:df.dtypes
查看基本统计量:
df.describe(include='all')

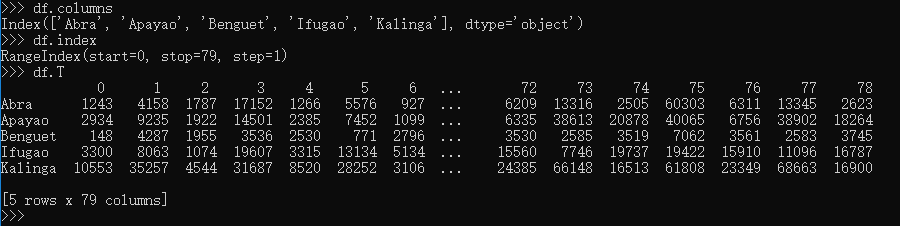
打印行列,以及数据转置:
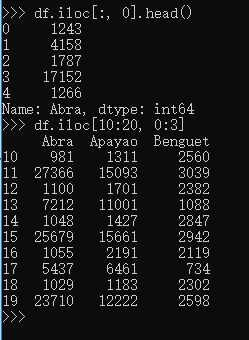
定位以及取出部分数据:
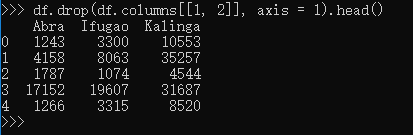
舍弃某些列,axis 参数告诉函数到底舍弃列还是行。如果axis等于0,那么就舍弃行。

3.2、可视化

1 >>> import numpy as np 2 >>> import matplotlib.pyplot as plt 3 >>> x = np.array([1,2,3,4,5,6,7,8]) 4 >>> x 5 array([1, 2, 3, 4, 5, 6, 7, 8]) 6 >>> y = np.array([3,5,7,6,2,6,10,15]) 7 >>> y 8 array([ 3, 5, 7, 6, 2, 6, 10, 15]) 9 >>> plt.plot(x,y,'r') 10 [<matplotlib.lines.Line2D object at 0x000001B31E98EC50>] 11 >>> plt.plot(x,y,'g',lw=10) 12 [<matplotlib.lines.Line2D object at 0x000001B31BD642B0>] 13 >>> plt.bar(x,y,0.2,alpha=1,color='b') 14 <BarContainer object of 8 artists> 15 >>> plt.show()
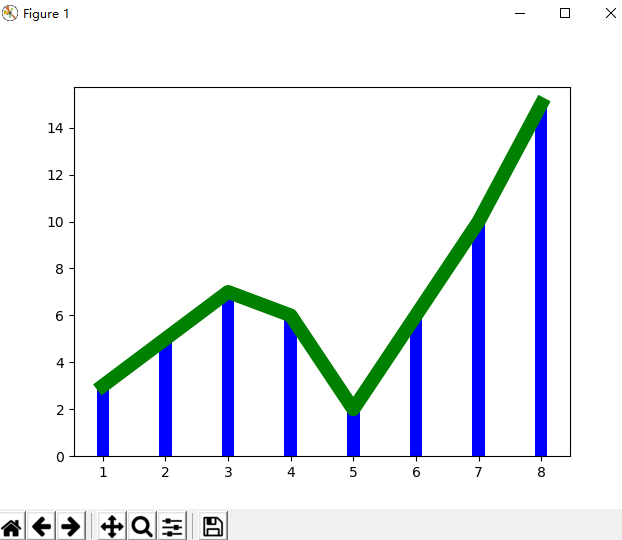
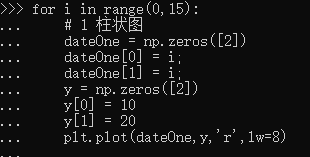

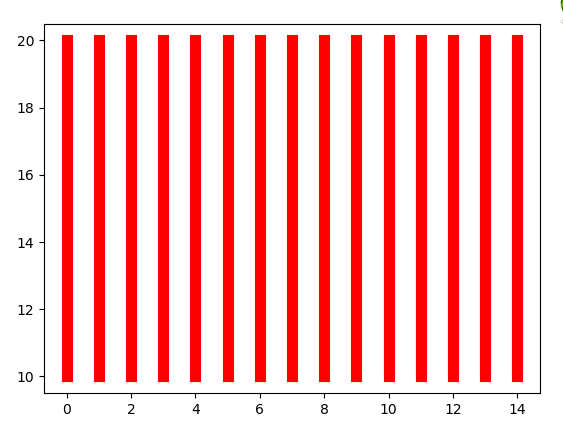
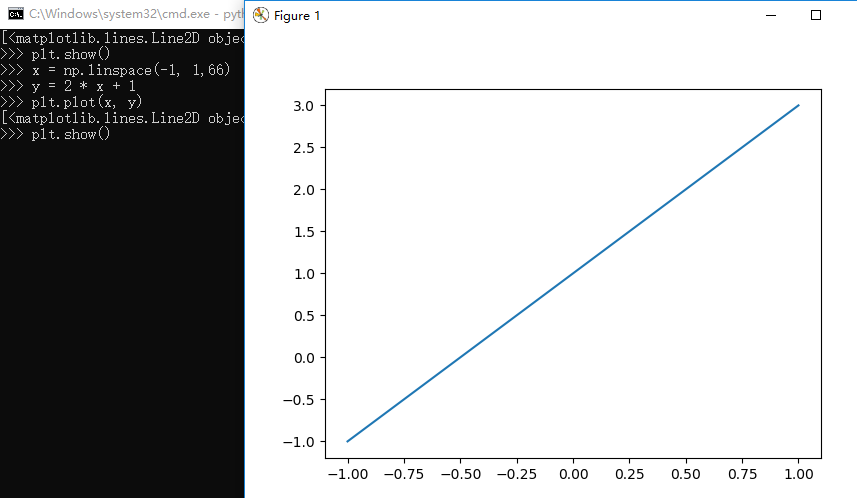
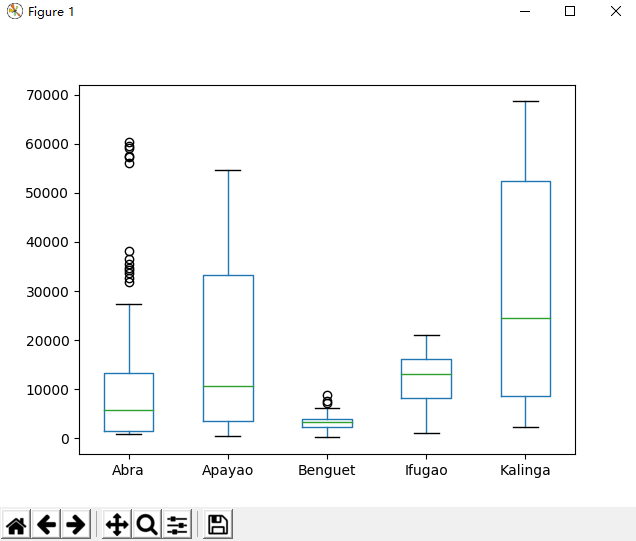
1 >>> import pandas as pd 2 >>> data_url = "https://raw.githubusercontent.com/alstat/Analysis-with-Programming/master/2014/Python/Numerical-Descriptions-of-the-Data/data.csv" 3 >>> df = pd.read_csv(data_url) 4 >>> import matplotlib.pyplot as plt 5 >>> df.plot(kind = 'box') 6 <matplotlib.axes._subplots.AxesSubplot object at 0x000001D6AE0849B0> 7 >>> plt.show(df.plot(kind = 'box'))
四、几种python的解释器
Python解释器或Python虚拟机有很多种实现,有CPython、PyPy、Jython以及IronPython等。CPython是最主流的实现。CPython同时也是别的虚拟机实现的参考解释器。PyPy是用Python实现的Python解释器,Jython是用Java实现运行在JVM上的解释器,IronPython是用Microsoft.NET CLR实现的解释器。除非解释器的选择非常非常重要,我们一般都用CPython。
CPython是用C语言实现Pyhon,是目前应用最广泛的解释器。Python最新的语言特性都是在这个上面先实现,Linux,OS X等自带的也是这个版本,包括Anaconda里面用的也是CPython。CPython是官方版本加上对于C/Python API的全面支持,基本包含了所有第三方库支持,例如Numpy,Scipy等。但是CPython有几个缺陷,一是全局锁使Python在多线程效能上表现不佳,二是CPython无法支持JIT(即时编译),导致其执行速度不及Java和Javascipt等语言。于是出现了Pypy。
Pypy是用Python自身实现的解释器。针对CPython的缺点进行了各方面的改良,性能得到很大的提升。最重要的一点就是Pypy集成了JIT。但是,Pypy无法支持官方的C/Python API,导致无法使用例如Numpy,Scipy等重要的第三方库,这也是现在Pypy没有被广泛使用的原因。
五、总结
通过对pandas的学习,我们知道了很多的常用工具,基本语法,数据结构,绘图工具以及使用方法。
参考文献:https://www.cnblogs.com/misswangxing/p/7903595.html
参考文献:https://blog.csdn.net/qq_26591517/article/details/80041296

