沉淀,再出发:python爬虫的再次思考
沉淀,再出发:python爬虫的再次思考
一、前言
之前笔者就写过python爬虫的相关文档,不过当时因为知识所限,理解和掌握的东西都非常的少,并且使用更多的是python2.x的版本的功能,现在基本上都在向python3转移了,很多新的框架也不断的产生和使用,从一些新的视角,比如beautifulsoup,selenium,phantomjs等工具的使用,可以使得我们对网页的解析和模拟更加的成熟和方便。
二、python3爬虫
在网上有很多值得我们去爬取的资源,这些资源大体可以分为文档、图片、音频、视频、其他格式的资源这几类,我们用的最多的或许就是前面的两种了,特别是我们爬取文档,这是我们经常使用的一种资源,比如爬取一些影评,网络小说等等,另外我们还可以将文档存储到Excel的表格之中这样就更加的清晰了。
2.1、爬取糗事百科

这里面有很多的文档资源,我们可以通过page之后的页码将内容爬取出来,并且根据页面的格式进行解析和存储。
让我们查看元素,看一下需要爬取的内容对应的标签和格式:
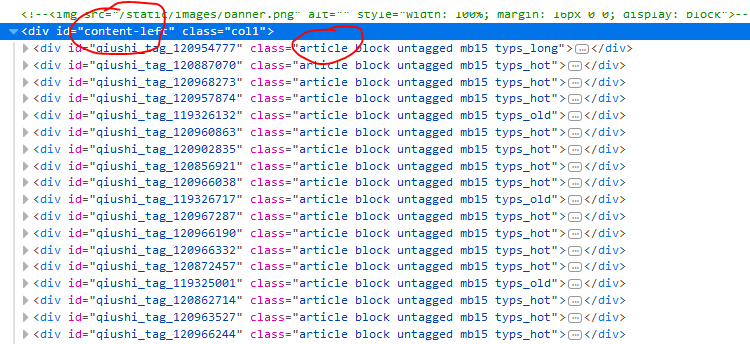
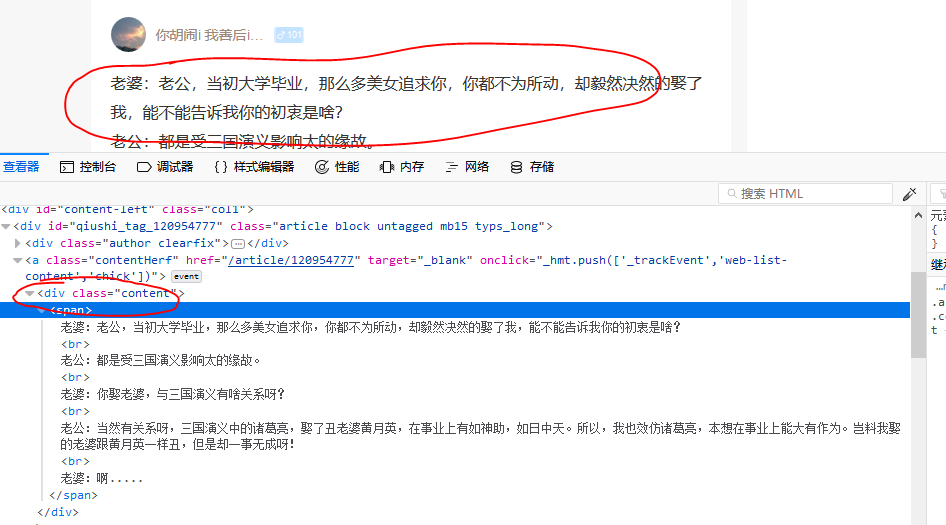
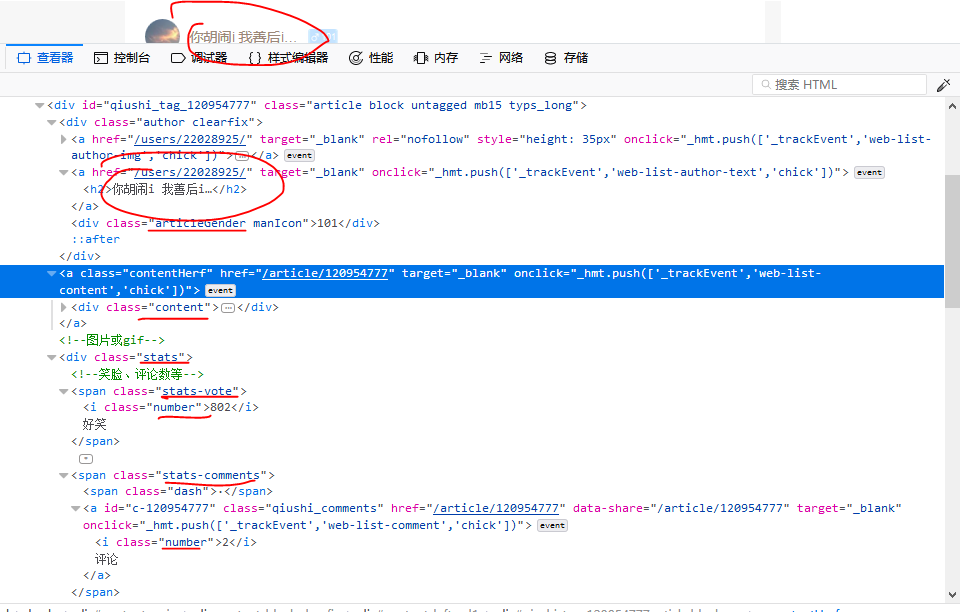
理解了url的编码规律和页面元素的DOM关系,我们就可以写程序了:
1 import requests 2 from bs4 import BeautifulSoup 3 4 5 def download_page(url): 6 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"} 7 r = requests.get(url, headers=headers) 8 return r.text 9 10 11 def get_content(html, page): 12 output = """第{}页 作者:{} 性别:{} 年龄:{} 点赞:{} 评论:{}\n{}\n------------\n""" 13 soup = BeautifulSoup(html, 'html.parser') 14 con = soup.find(id='content-left') 15 con_list = con.find_all('div', class_="article") 16 for i in con_list: 17 author = i.find('h2').string # 获取作者名字 18 content = i.find('div', class_='content').find('span').get_text() # 获取内容 19 stats = i.find('div', class_='stats') 20 vote = stats.find('span', class_='stats-vote').find('i', class_='number').string 21 comment = stats.find('span', class_='stats-comments').find('i', class_='number').string 22 author_info = i.find('div', class_='articleGender') # 获取作者 年龄,性别 23 if author_info is not None: # 非匿名用户 24 class_list = author_info['class'] 25 if "womenIcon" in class_list: 26 gender = '女' 27 elif "manIcon" in class_list: 28 gender = '男' 29 else: 30 gender = '' 31 age = author_info.string # 获取年龄 32 else: # 匿名用户 33 gender = '' 34 age = '' 35 36 save_txt(output.format(page, author, gender, age, vote, comment, content)) 37 38 39 def save_txt(*args): 40 for i in args: 41 with open('E:qiubai.txt', 'a', encoding='utf-8') as f: 42 f.write(i) 43 44 45 def main(): 46 # 我们点击下面链接,在页面下方可以看到共有13页,可以构造如下 url, 47 # 当然我们最好是用 Beautiful Soup找到页面底部有多少页。 48 for i in range(1, 14): 49 url = 'https://qiushibaike.com/text/page/{}'.format(i) 50 html = download_page(url) 51 get_content(html, i) 52 53 if __name__ == '__main__': 54 main()
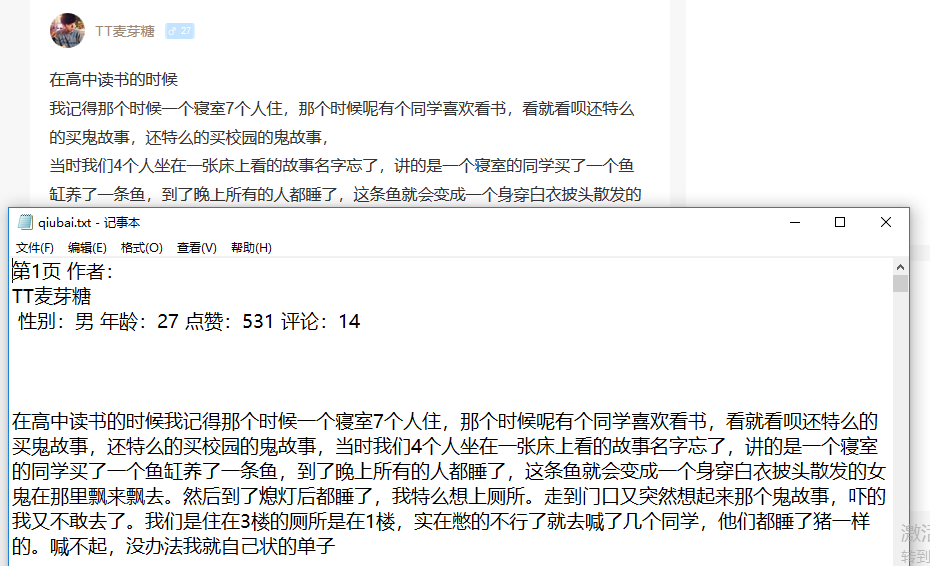
运行结果:
2.2、爬取文本并保存成Excel文件
在这里如果没有mysql数据库的话,我们已经将连接数据库并保存到数据库的功能给注释掉了。爬取拉钩网的网站信息,并且记录到Excel中。
1 import random 2 import time 3 4 import requests 5 from openpyxl import Workbook 6 import pymysql.cursors 7 8 9 def get_conn(): 10 '''建立数据库连接''' 11 conn = pymysql.connect(host='localhost', 12 user='root', 13 password='root', 14 db='python', 15 charset='utf8mb4', 16 cursorclass=pymysql.cursors.DictCursor) 17 return conn 18 19 20 def insert(conn, info): 21 '''数据写入数据库''' 22 with conn.cursor() as cursor: 23 sql = "INSERT INTO `python` (`shortname`, `fullname`, `industryfield`, `companySize`, `salary`, `city`, `education`) VALUES (%s, %s, %s, %s, %s, %s, %s)" 24 cursor.execute(sql, info) 25 conn.commit() 26 27 28 def get_json(url, page, lang_name): 29 '''返回当前页面的信息列表''' 30 headers = { 31 'Host': 'www.lagou.com', 32 'Connection': 'keep-alive', 33 'Content-Length': '23', 34 'Origin': 'https://www.lagou.com', 35 'X-Anit-Forge-Code': '0', 36 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0', 37 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 38 'Accept': 'application/json, text/javascript, */*; q=0.01', 39 'X-Requested-With': 'XMLHttpRequest', 40 'X-Anit-Forge-Token': 'None', 41 'Referer': 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=', 42 'Accept-Encoding': 'gzip, deflate, br', 43 'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7' 44 } 45 data = {'first': 'false', 'pn': page, 'kd': lang_name} 46 json = requests.post(url, data, headers=headers).json() 47 list_con = json['content']['positionResult']['result'] 48 info_list = [] 49 for i in list_con: 50 info = [] 51 info.append(i.get('companyShortName', '无')) 52 info.append(i.get('companyFullName', '无')) 53 info.append(i.get('industryField', '无')) 54 info.append(i.get('companySize', '无')) 55 info.append(i.get('salary', '无')) 56 info.append(i.get('city', '无')) 57 info.append(i.get('education', '无')) 58 info_list.append(info) 59 return info_list 60 61 62 def main(): 63 lang_name = 'python' 64 wb = Workbook() # 打开 excel 工作簿 65 # conn = get_conn() # 建立数据库连接 不存数据库 注释此行 66 for i in ['北京', '上海', '广州', '深圳', '杭州']: # 五个城市 67 page = 1 68 ws1 = wb.active 69 ws1.title = lang_name 70 url = 'https://www.lagou.com/jobs/positionAjax.json?city={}&needAddtionalResult=false'.format(i) 71 while page < 31: # 每个城市30页信息 72 info = get_json(url, page, lang_name) 73 page += 1 74 print(i, 'page', page) 75 time.sleep(random.randint(10, 20)) 76 for row in info: 77 # insert(conn, tuple(row)) # 插入数据库,若不想存入 注释此行 78 ws1.append(row) 79 # conn.close() # 关闭数据库连接,不存数据库 注释此行 80 wb.save('E:{}职位信息.xlsx'.format(lang_name)) 81 82 if __name__ == '__main__': 83 main()
运行结果:
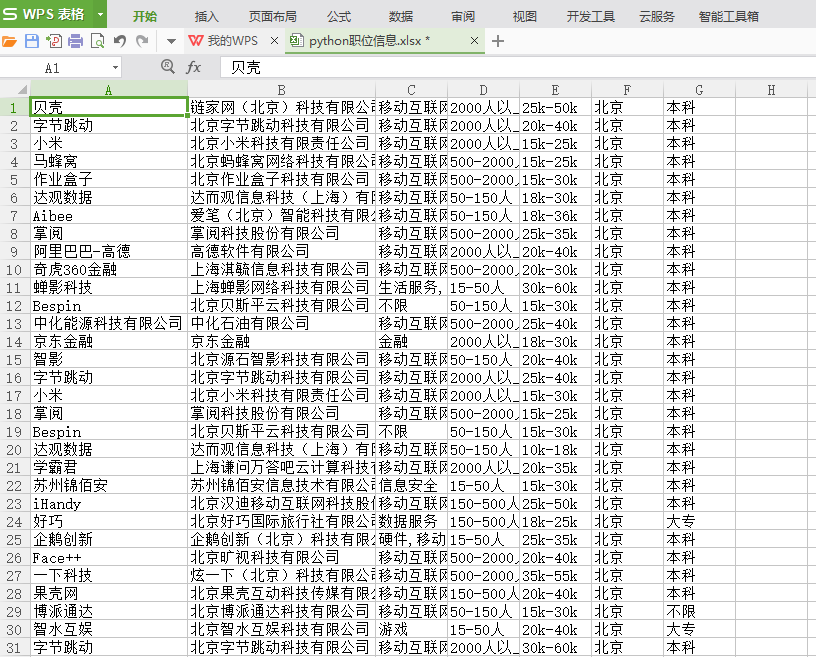
2.3、爬取图片并保存
这里我们使用一个图片比较多的网站(http://meizitu.com)为例来展示:
1 import requests 2 import os 3 import time 4 import threading 5 from bs4 import BeautifulSoup 6 7 8 def download_page(url): 9 ''' 10 用于下载页面 11 ''' 12 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"} 13 r = requests.get(url, headers=headers) 14 r.encoding = 'gb2312' 15 return r.text 16 17 18 def get_pic_list(html): 19 ''' 20 获取每个页面的套图列表,之后循环调用get_pic函数获取图片 21 ''' 22 soup = BeautifulSoup(html, 'html.parser') 23 pic_list = soup.find_all('li', class_='wp-item') 24 for i in pic_list: 25 a_tag = i.find('h3', class_='tit').find('a') 26 link = a_tag.get('href') 27 text = a_tag.get_text() 28 get_pic(link, text) 29 30 31 def get_pic(link, text): 32 ''' 33 获取当前页面的图片,并保存 34 ''' 35 html = download_page(link) # 下载界面 36 soup = BeautifulSoup(html, 'html.parser') 37 pic_list = soup.find('div', id="picture").find_all('img') # 找到界面所有图片 38 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"} 39 create_dir('pic/{}'.format(text)) 40 for i in pic_list: 41 pic_link = i.get('src') # 拿到图片的具体 url 42 r = requests.get(pic_link, headers=headers) # 下载图片,之后保存到文件 43 with open('pic/{}/{}'.format(text, pic_link.split('/')[-1]), 'wb') as f: 44 f.write(r.content) 45 time.sleep(1) # 休息一下,不要给网站太大压力,避免被封 46 47 48 def create_dir(name): 49 if not os.path.exists(name): 50 os.makedirs(name) 51 52 53 def execute(url): 54 page_html = download_page(url) 55 get_pic_list(page_html) 56 57 58 def main(): 59 create_dir('pic') 60 queue = [i for i in range(1, 72)] # 构造 url 链接 页码。 61 threads = [] 62 while len(queue) > 0: 63 for thread in threads: 64 if not thread.is_alive(): 65 threads.remove(thread) 66 while len(threads) < 5 and len(queue) > 0: # 最大线程数设置为 5 67 cur_page = queue.pop(0) 68 url = 'http://meizitu.com/a/more_{}.html'.format(cur_page) 69 thread = threading.Thread(target=execute, args=(url,)) 70 thread.setDaemon(True) 71 thread.start() 72 print('{}正在下载{}页'.format(threading.current_thread().name, cur_page)) 73 threads.append(thread) 74 75 76 if __name__ == '__main__': 77 main()
2.4、爬取豆瓣书籍
1 from bs4 import BeautifulSoup 2 import requests 3 from openpyxl import Workbook 4 excel_name = "书籍.xlsx" 5 wb = Workbook() 6 ws1 = wb.active 7 ws1.title='书籍' 8 9 10 def get_html(url): 11 header = { 12 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0'} 13 html = requests.get(url, headers=header).content 14 return html 15 16 17 def get_con(html): 18 soup = BeautifulSoup(html,'html.parser') 19 book_list = soup.find('div', attrs={'class': 'article'}) 20 page = soup.find('div', attrs={'class': 'paginator'}) 21 next_page = page.find('span', attrs={'class': 'next'}).find('a') 22 name = [] 23 for i in book_list.find_all('table'): 24 book_name = i.find('div', attrs={'class': 'pl2'}) 25 m = list(book_name.find('a').stripped_strings) 26 if len(m)>1: 27 x = m[0]+m[1] 28 else: 29 x = m[0] 30 #print(x) 31 name.append(x) 32 if next_page: 33 return name, next_page.get('href') 34 else: 35 return name, None 36 37 38 def main(): 39 url = 'https://book.douban.com/top250' 40 name_list=[] 41 while url: 42 html = get_html(url) 43 name, url = get_con(html) 44 name_list = name_list + name 45 for i in name_list: 46 location = 'A%s'%(name_list.index(i)+1) 47 print(i) 48 print(location) 49 ws1[location]=i 50 wb.save(filename=excel_name) 51 52 53 if __name__ == '__main__': 54 main()

2.5、爬取豆瓣电影影评并保存到Excel中
1 #!/usr/bin/env python 2 # encoding=utf-8 3 import requests 4 import re 5 import codecs 6 from bs4 import BeautifulSoup 7 from openpyxl import Workbook 8 wb = Workbook() 9 dest_filename = '电影.xlsx' 10 ws1 = wb.active 11 ws1.title = "电影top250" 12 13 DOWNLOAD_URL = 'http://movie.douban.com/top250/' 14 15 16 def download_page(url): 17 """获取url地址页面内容""" 18 headers = { 19 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36' 20 } 21 data = requests.get(url, headers=headers).content 22 return data 23 24 25 def get_li(doc): 26 soup = BeautifulSoup(doc, 'html.parser') 27 ol = soup.find('ol', class_='grid_view') 28 name = [] # 名字 29 star_con = [] # 评价人数 30 score = [] # 评分 31 info_list = [] # 短评 32 for i in ol.find_all('li'): 33 detail = i.find('div', attrs={'class': 'hd'}) 34 movie_name = detail.find( 35 'span', attrs={'class': 'title'}).get_text() # 电影名字 36 level_star = i.find( 37 'span', attrs={'class': 'rating_num'}).get_text() # 评分 38 star = i.find('div', attrs={'class': 'star'}) 39 star_num = star.find(text=re.compile('评价')) # 评价 40 41 info = i.find('span', attrs={'class': 'inq'}) # 短评 42 if info: # 判断是否有短评 43 info_list.append(info.get_text()) 44 else: 45 info_list.append('无') 46 score.append(level_star) 47 48 name.append(movie_name) 49 star_con.append(star_num) 50 page = soup.find('span', attrs={'class': 'next'}).find('a') # 获取下一页 51 if page: 52 return name, star_con, score, info_list, DOWNLOAD_URL + page['href'] 53 return name, star_con, score, info_list, None 54 55 56 def main(): 57 url = DOWNLOAD_URL 58 name = [] 59 star_con = [] 60 score = [] 61 info = [] 62 while url: 63 doc = download_page(url) 64 movie, star, level_num, info_list, url = get_li(doc) 65 name = name + movie 66 star_con = star_con + star 67 score = score + level_num 68 info = info + info_list 69 for (i, m, o, p) in zip(name, star_con, score, info): 70 col_A = 'A%s' % (name.index(i) + 1) 71 col_B = 'B%s' % (name.index(i) + 1) 72 col_C = 'C%s' % (name.index(i) + 1) 73 col_D = 'D%s' % (name.index(i) + 1) 74 ws1[col_A] = i 75 ws1[col_B] = m 76 ws1[col_C] = o 77 ws1[col_D] = p 78 wb.save(filename=dest_filename) 79 80 81 if __name__ == '__main__': 82 main()
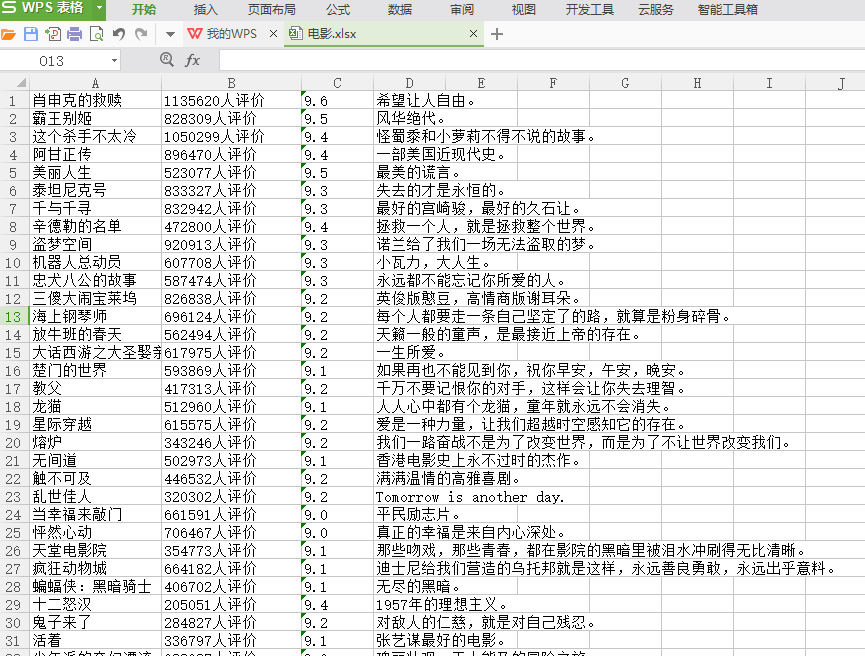
当然还可以爬取小说等其他资源。
三、使用selenium模拟真人操作
在编写程序之前,我们需要为python的运行环境之中加入selenium这个元素,因此我们使用pip来安装即可,pip是我们在安装python的时候一起安装的,当我们在环境变量中将python暴露出来的时候,pip也就出来了。

之后我们进入关于python的selenium官网,可以看到如何在不同的浏览器中配置和安装相应的驱动。
在这里我们下载了Firefox浏览器的驱动器之后将其放入python的安装目录中,这样既方便查找,又方便设为环境变量:

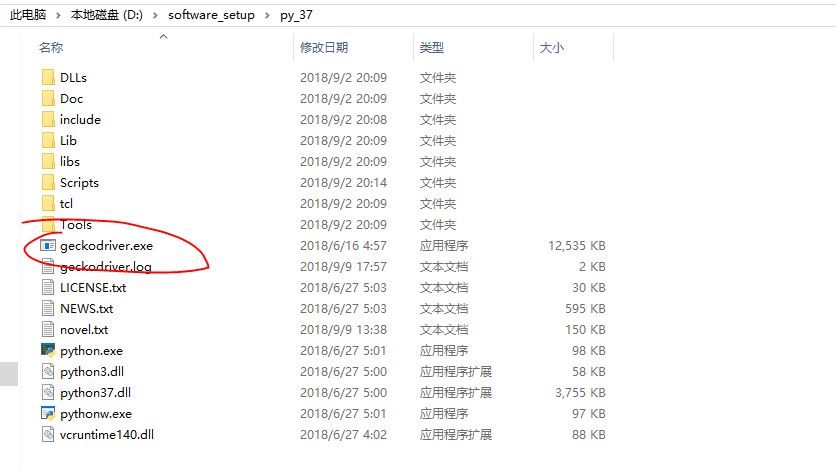
之后我们来模拟人工访问淘宝网站并抓取信息:
1 from selenium import webdriver 2 import time 3 class TB(object): 4 def __init__(self,keyword): 5 self.keyword = keyword 6 def start_taobao(self): 7 8 driver =webdriver.Firefox() 9 10 driver.get('http://www.taobao.com') 11 12 search_input = driver.find_element_by_id('q') 13 14 search_input.send_keys(self.keyword) 15 16 search_btn = driver.find_element_by_class_name('btn-search') 17 18 search_btn.click() 19 time.sleep(2) 20 21 file_handle = open('E:%s.txt'%self.keyword,'w',encoding='utf-8') 22 for x in range(1,2): 23 print('获取第%s页的数据'%x) 24 25 for x in range(1,11,2): 26 time.sleep(1) 27 28 j = x/10 29 30 js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight * %f'%j 31 driver.execute_script(js) 32 33 34 shops = driver.find_elements_by_class_name('info-cont') 35 36 if len(shops) ==0: 37 shops = driver.find_elements_by_class_name('J_MouserOnverReq') 38 39 for shop in shops: 40 41 file_handle.write(shop.text) 42 file_handle.write('\n') 43 44 next_li = driver.find_element_by_class_name('next') 45 next_li.click() 46 47 file_handle.close() 48 49 driver.quit() 50 51 print(__name__) 52 53 if __name__ == '__main__': 54 keyword = input('输入关键词:') 55 tb =TB(keyword) 56 tb.start_taobao()
可以看到selenium的强大之处在于能按照我们的需要像人类一样的打开浏览器输入内容,点击按钮,抓取网页,最后关闭网页,非常的方便和强大。当然selenium也有很多的命令,获取网页,解析元素,点击按钮,执行js等,非常的有用,当然selenium还可以破解验证码,滑动条等机制。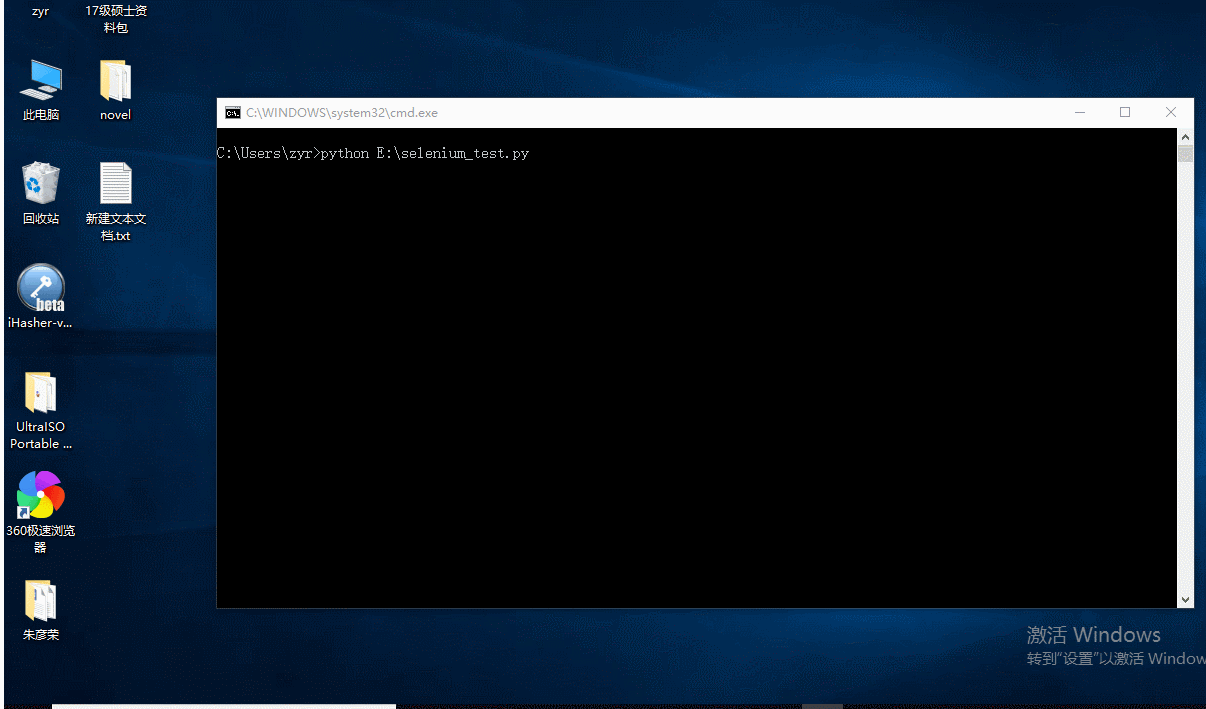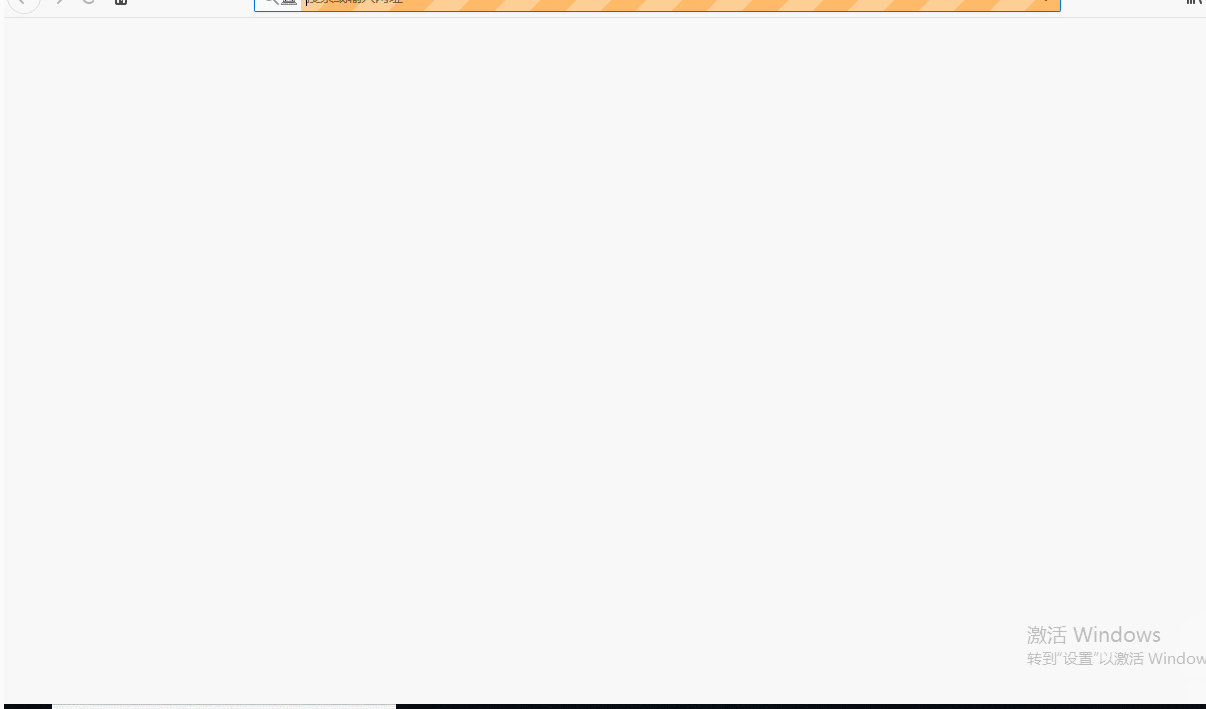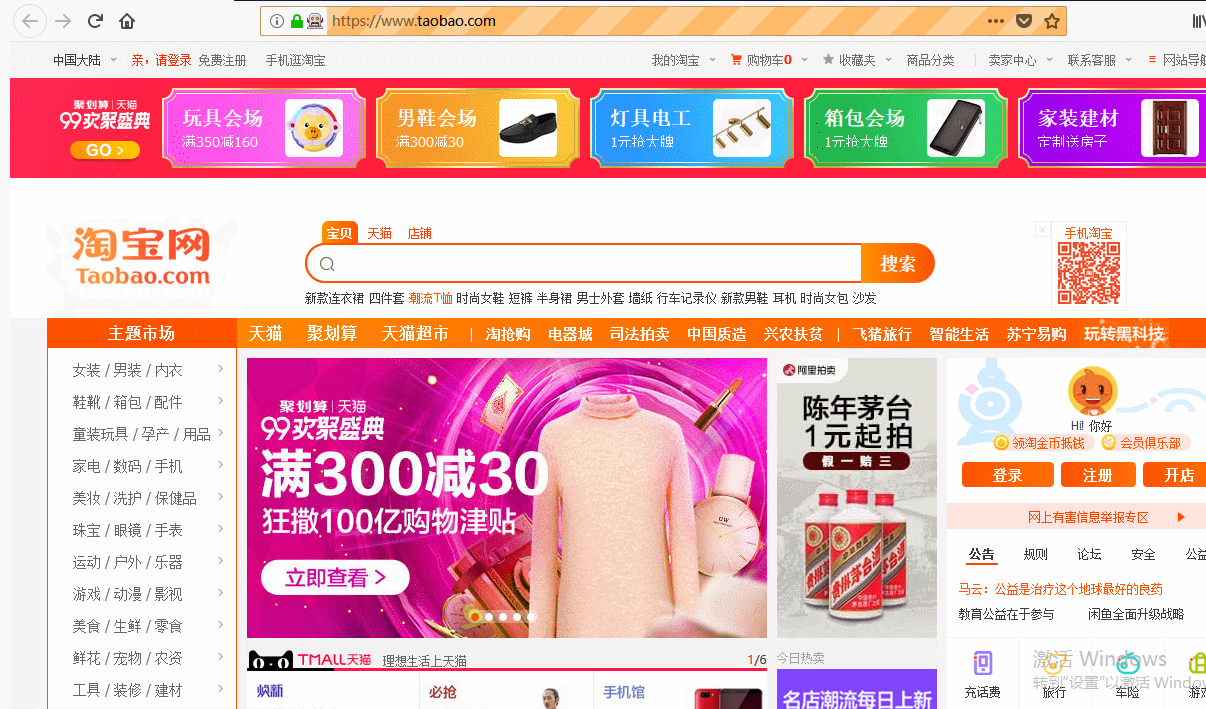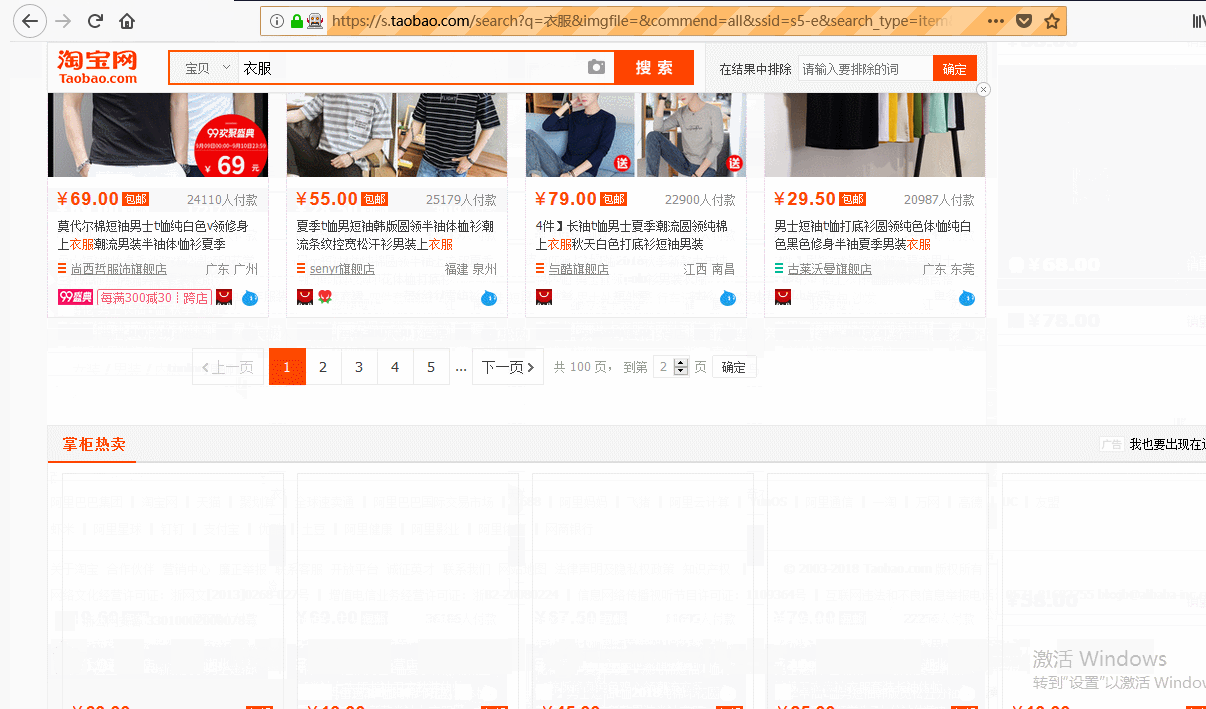
四、phantomjs的使用
既然我们能够使用selenium模拟真人自动打开网页抓取响应信息,点击按钮,输入文字了,为什么还需要phantomjs呢?那是因为phantomjs是一个无头的浏览器,什么叫做‘无头’,其实就是没有图形界面的浏览器,基于webkit内核,只有命令行的界面,这样的话就能自然的通过设置规避一些图片以及音视频等,并且无需像我们之前使用selenium操作Firefox那样的打开浏览器了,这是非常方便的,因此业界一直都是使用selenium+phantomjs来配合抓取网页和分析网页的,可惜的是当Firefox和Chrome等浏览器也相应地推出了无头浏览器的版本之后,作为小厂的创意的phantomjs瞬间就没有立足之地了,市场就是这样的残酷,下面让我们看一下安装和使用吧:
在官网上下载相应版本:

下载之后我们解压并将phantomjs.exe暴露到环境变量之中,之后我们就可以在cmd中对phantomjs操作了。
首先让我们看一个简单的只使用phantomjs的例子:
1 var webPage = require('webpage'); 2 var page = webPage.create(); 3 4 page.open("http://www.baidu.com", function start(status) { 5 page.render('E:baidu.jpg'); 6 phantom.exit(); 7 });

我们可以看到在没有打开网页,也没有截图的情况下,我们使用phantomjs已经抓去了百度的页面并且对其截图放到了我们规定的目录下面,这是多么的神奇呀,如果再配合上selenium,那么这样的设计模拟真人并且不用再次打开浏览器的GUI就可以神不知鬼不觉的完成爬虫的工作了。
我们使用selenium和phantomjs来抓取网页并打印出来:
1 from selenium import webdriver 2 url = "https://www.taobao.com" 3 driver = webdriver.PhantomJS() 4 driver.get(url) 5 print (driver.page_source)

可以看到我们确实成功了,但是也出现了警告信息,意思是selenium使用phantomjs已经过时了,请使用Firefox或者Chrome的无头版本浏览器来代替,因此这个用js写的phantomjs的存在就变得举步维艰了。
可以看出selenium和phantomjs的出现其实更大成分是为了应付动态网页的相关技术,比如ajax,在不刷新网页的情况下,将数据通过json等方式传递回来,这样我们使用普通的爬虫是抓取不到的(除非找到相应的js文件再次请求一下,非常的耗时和复杂),但是使用selenium通过模拟真人操作是非常容易的,再加上无头浏览器phantomjs之后,提供了更强大的功能。因此一切技术的产生都是为了解决某种特定的问题,问题是永恒的,而解决问题的方法却是在不断地变化着和优化着,道高一尺魔高一丈,计算机科学就是在这样的压力之下不断地完善和发展的。
五、总结
Selenium是一个用于Web应用程序测试的工具。selenium的功能比较齐全,不只是获取动态网页, 比如数据的提取都可以完成, 但是不建议直接使用selenium来提取数据, 因为速度慢。 Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。 支持的浏览器包括IE,Mozilla和Firefox,还有无界面的phantomjs浏览器等,我们可以通过selenium直接操作浏览器。但是启动firefox毕竟是图形化的界面, 肯定是会消耗大量内存和cpu ,phantomjs正是一款没有界面的浏览器但是还是同样能完成浏览器的渲染,这样如果我们的操作系统是没有界面的linux服务器上,phantomjs就大有用途了,并且phantomjs提供的设置项多, 比如可以设置忽略images的请求减少网络请求数。既然phantomjs只是一款浏览器, selenium就当然能像操作firefox一样很简单的操作phantomjs了。
PhantomJS是一个基于webkit的JavaScript API。它使用QtWebKit作为它核心浏览器的功能,使用webkit来编译解释执行JavaScript代码。任何可以在基于webkit浏览器做的事情,它都能做到。它不仅是个隐形的浏览器,提供了诸如CSS选择器、支持Web标准、DOM操作、JSON、HTML5、Canvas、SVG等,同时也提供了处理文件I/O的操作,从而使得可以向操作系统读写文件等。PhantomJS的用处可谓非常广泛,诸如网络监测、网页截屏、无需浏览器的 Web 测试、页面访问自动化等。
通过在python中加入多线程、beautifulsoup和selenium之后,我们可以看到使用python抓取网页是如此的便捷,并且还能保存成各种类型的文档,还能存储到数据库之中,这样的爬虫加以改进之后已经能够用于工业生产了。

