沉淀,再出发:Java基础知识汇总
沉淀,再出发:Java基础知识汇总
一、前言
不管走得多远,基础知识是最重要的,这些知识就是建造一座座高楼大厦的基石和钢筋水泥。对于Java这门包含了编程方方面面的语言,有着太多的基础知识了,从最初的语法,对象的定义,类、接口、继承、静态、动态、重载、覆盖这些基本的概念和使用方法,到稍微高级一点的多线程,文件读写,网络编程,GUI使用,再到之后的反射机制、序列化、与数据库的结合等高级一点的用法,最后将设计模式应用其中,产生了一个个新的概念,比如Spring、Spring MVC、Hibernate等产品以及AOP(面向切面编程)、IOC(控制反转)、ID(依赖注入)、容器等概念,最后再加上强大的Tomcat等服务器充分将这些概念应用其中,产生了多种多样的编程方式以及用法,因为Android系统编程的兴起,最初就是使用Java来完成的(现在也可以使用kotlin了),从而又产生了新的编程概念,就这样java语言像滚雪球一样的不断地扩展,深入到生活的方方面面,比如大数据的hadoop,可以说我们在不知不觉之中已经过分的充分的依靠java这门语言了,同时也在不断地改善着java的能力和功能,比如后来的lambda表达式等等。再回过来仔细看看java这门语言,确实是有着很多的优点,比如GC垃圾回收机制,比如对多种平台的适应性,比如java虚拟机的概念,可以说正是因为设计思想的独到和通用性才使得java这么快的风靡世界,今天我们就来稍微整理一下Java的基础知识,将一些自己不确定的东西变得更加真实和坚实一点。
二、Java基础知识
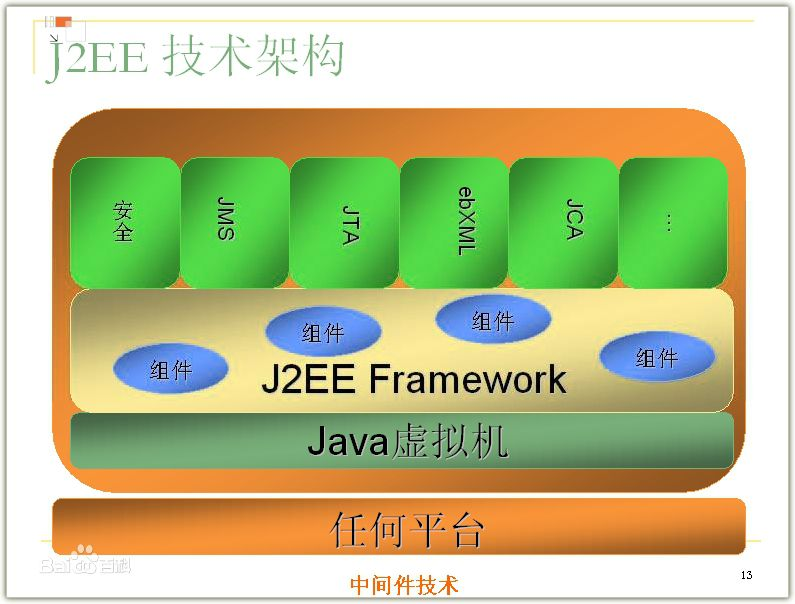
2.1、J2EE是什么?
J2EE本身是一个标准,一个为企业分布式应用的开发提供的标准平台。J2EE也是一个框架,包括JDBC、JNDI、RMI、JMS、EJB、JTA等技术。J2EE是一套全然不同于传统应用开发的技术架构,包含许多组件,主要可简化且规范应用系统的开发与部署,进而提高可移植性、安全与再用价值。J2EE核心是一组技术规范与指南,其中所包含的各类组件、服务架构及技术层次,均有共同的标准及规格,让各种依循J2EE架构的不同平台之间,存在良好的兼容性,解决过去企业后端使用的信息产品彼此之间无法兼容,企业内部或外部难以互通的窘境。J2EE组件和“标准的” Java类的不同点在于:它被装配在一个J2EE应用中,具有固定的格式并遵守J2EE规范,由J2EE服务器对其进行管理。J2EE规范是这样定义J2EE组件的:客户端应用程序和applet是运行在客户端的组件;Java Servlet和Java Server Pages (JSP) 是运行在服务器端的Web组件;Enterprise Java Bean (EJB )组件是运行在服务器端的业务组件。
Enterprise Java Bean 相当于DCOM,即分布式组件。它是基于Java的远程方法调用(RMI)技术的,所以EJB可以被远程访问 (跨进程、跨计算机) 。但EJB必须被布署在诸如Webspere、WebLogic这样的容器中,EJB客户从不直接访问真正的EJB组件,而是通过其容器访问。EJB容器是EJB组件的代理,EJB组件由容器所创建和管理。客户通过容器来访问真正的EJB组件。Enterprise java bean 容器。更具有行业领域特色。他提供给运行在其中的组件EJB各种管理功能。只要满足J2EE规范的EJB放入该容器,马上就会被容器进行高效率的管理。并且可以通过现成的接口来获得系统级别的服务。例如邮件服务、事务管理。
EJB与JAVA BEAN是SUN的不同组件规范,EJB是在容器中运行的,分步式的,而JAVA BEAN主要是一种可利用的组件,主要在客户端UI表现上。Java Bean 是可复用的组件,对Java Bean并没有严格的规范,理论上讲,任何一个Java类都可以是一个Bean。但通常情况下,由于Java Bean是被容器所创建(如Tomcat)的,所以Java Bean应具有一个无参的构造器,另外,通常Java Bean还要实现Serializable接口用于实现Bean的持久性。Java Bean实际上相当于微软COM模型中的本地进程内COM组件,它是不能被跨进程访问的。Enterprise Java Bean 相当于DCOM,即分布式组件。它是基于Java的远程方法调用(RMI)技术的,所以EJB可以被远程访问(跨进程、跨计算机)。但EJB必须被布署在诸如Webspere、WebLogic这样的容器中,EJB客户从不直接访问真正的EJB组件,而是通过其容器访问。EJB容器是EJB组件的代理,EJB组件由容器所创建和管理。客户通过容器来访问真正的EJB组件。
EJB容器提供的服务:主要提供声明周期管理、代码产生、持续性管理、安全、事务管理、锁和并发行管理等服务。
EJB的角色和三个对象:EJB角色主要包括Bean开发者、应用组装者、部署者、系统管理员、EJB容器提供者、EJB服务器提供者;三个对象是Remote(Local)接口、Home(LocalHome)接口,Bean类。
EJB的几种类型:会话(Session)Bean、实体(Entity)Bean、消息驱动(Message Driven)Bean;会话Bean又可分为有状态(Stateful)和无状态(Stateless)两种;实体Bean可分为Bean管理的持续性(BMP)和容器管理的持续性(CMP)两种。
EJB(包括SessionBean,EntityBean)的生命周期和管理事务的方法:
SessionBean:Stateless Session Bean 的生命周期是由容器决定的,当客户机发出请求要建立一个Bean的实例时,EJB容器不一定要创建一个新的Bean的实例供客户机调用,而是随便找一个现有的实例提供给客户机。当客户机第一次调用一个Stateful Session Bean 时,容器必须立即在服务器中创建一个新的Bean实例,并关联到客户机上,以后此客户机调用Stateful Session Bean 的方法时容器会把调用分派到与此客户机相关联的Bean实例。
EntityBean:Entity Beans能存活相对较长的时间,并且状态是持续的。只要数据库中的数据存在,Entity beans就一直存活。而不是按照应用程序或者服务进程来说的。即使EJB容器崩溃了,Entity beans也是存活的。Entity Beans生命周期能够被容器或者 Beans自己管理。
EJB通过以下技术管理实务:对象管理组织(OMG)的对象实务服务(OTS),Sun Microsystems的Transaction Service(JTS)、Java Transaction API(JTA),开发组(X/Open)的XA接口。
Bean 实例的生命周期:对于Stateless Session Bean、Entity Bean、Message Driven Bean一般存在缓冲池管理,而对于Entity Bean和Statefull Session Bean存在Cache管理,通常包含创建实例,设置上下文、创建EJB Object(create)、业务方法调用、remove等过程;对于存在缓冲池管理的Bean,在create之后实例并不从内存清除,而是采用缓冲 池调度机制不断重用实例,而对于存在Cache管理的Bean则通过激活和去激活机制保持Bean的状态并限制内存中实例数量。
激活机制:以Statefull Session Bean 为例,其Cache大小决定了内存中可以同时存在的Bean实例的数量,根据MRU或NRU算法,实例在激活和去激活状态之间迁移,激活机制是当客户端调用某个EJB实例业务方法时,如果对应EJB Object发现自己没有绑定对应的Bean实例则从其去激活Bean存储中(通过序列化机制存储实例)回复(激活)此实例。状态变迁前会调用对应的ejbActive和ejbPassivate方法。
remote接口和home接口主要作用:remote接口定义了业务方法,用于EJB客户端调用业务方法;home接口是EJB工厂用于创建和移除查找EJB实例。
客服端调用EJB对象的几个基本步骤:设置JNDI服务工厂以及JNDI服务地址系统属性;查找Home接口;从Home接口调用Create方法创建Remote接口;通过Remote接口调用其业务方法。
有状态session bean与无状态session bean的区别:stateful session bean维护客户端会话状态.它们必须属于一个且只属于一个客户端.激活/钝化,开销大.stateless session不维护一个客户端的会话状态它们被放入实例池中,因此可被多个用户共用,开销小,效率高。
本地视图与远程视图的区别:远程视图中远程调用将在两台不同JVM之间执行,远程调用这些操作使得相关网络开销会更高与对象的位置无关,也不会在乎是否在一个JVM。
本地视图是本地调用将在相同的JVM中执行,没有网络开销,操作效率更高,因为客户端使用本地对象调用bean上的服务,限制在本地实现中,而且不需要做到与位置无关。
实体Bean的三个状态:no-state,Bean实例还没有创建;pooled,Bean实例被创建,但还没有和一个EJB Object关联;ready,与EJB Object相关联,若断开关联则回到pooled。
Jar、War、EAR、在文件结构上,三者并没有什么不同,它们都采用zip或jar档案文件压缩格式。但是它们的使用目的有所区别:
Jar文件(扩展名为.jar,Java Application Archive)包含Java类的普通库、资源(resources)、辅助文件(auxiliary files)等
War文件(扩展名为.war,Web Application Archive)包含全部Web应用程序。在这种情形下,一个Web应用程序被定义为单独的一组文件、类和资源,用户可以对jar文件进行封装,并把它作为小型服务程序(servlet)来访问。
Ear文件(扩展名为.ear,Enterprise Application Archive)包含全部企业应用程序。在这种情形下,一个企业应用程序被定义为多个jar文件、资源、类和Web应用程序的集合。
每一种文件(.jar, .war, .ear)只能由应用服务器(application servers)、小型服务程序容器(servlet containers)、EJB容器(EJB containers)等进行处理。
EAR文件包括整个项目,内含多个ejb module(jar文件)和web module(war文件);EAR文件的生成可以使用winrar zip压缩方式或者jar命令。
2.2、JAVA解析xml的五种方式比较:
(1)DOM解析
DOM是html和xml的应用程序接口(API),以层次结构(类似于树型)来组织节点和信息片段,映射XML文档的结构,允许获取和操作文档的任意部分,是W3C的官方标准。
优点:允许应用程序对数据和结构做出更改;访问是双向的,可以在任何时候在树中上下导航,获取和操作任意部分的数据。
缺点:通常需要加载整个XML文档来构造层次结构,消耗资源大。
①构建Document对象:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); DocumentBuilder db = bdf.newDocumentBuilder(); InputStream is = Thread.currentThread().getContextClassLoader().getResourceAsStream(xml文件); Document doc = bd.parse(is);
②遍历DOM对象
Document: XML文档对象,由解析器获取
NodeList: 节点数组
Node: 节点(包括element、#text)
Element: 元素,可用于获取属性参数
(2)SAX(Simple API for XML)解析
流模型中的"推"模型分析方式。通过事件驱动,每发现一个节点就引发一个事件,事件推给事件处理器,通过回调方法完成解析工作,解析XML文档的逻辑需要应用程序完成。
优点:不需要等待所有数据都被处理,分析就能立即开始;只在读取数据时检查数据,不需要保存在内存中;可以在某个条件得到满足时停止解析,不必解析整个文档;效率和性能较高,能解析大于系统内存的文档。
缺点:需要应用程序自己负责TAG的处理逻辑(例如维护父/子关系等),文档越复杂程序就越复杂;单向导航,无法定位文档层次,很难同时访问同一文档的不同部分数据,不支持XPath。
原理:简单的说就是对文档进行顺序扫描,当扫描到文档(document)开始与结束、元素(element)开始与结束时通知事件处理函数(回调函数),进行相应处理,直到文档结束。
事件处理器类型:①访问XML DTD:DTDHandler ②低级访问解析错误:ErrorHandler ③访问文档内容:ContextHandler
DefaultHandler类:SAX事件处理程序的默认基类,实现了DTDHandler、ErrorHandler、ContextHandler和EntityResolver接口,通常做法是,继承该基类,重写需要的方法,如startDocument()
创建SAX解析器:
SAXParserFactory saxf = SAXParserFactory.newInstance();
SAXParser sax = saxf.newSAXParser();
注:关于遍历:深度优先遍历、广度优先遍历
(3)JDOM(Java-based Document Object Model)
Java特定的文档对象模型。自身不包含解析器,使用SAX。
优点:使用具体类而不是接口,简化了DOM的API;大量使用了Java集合类,方便Java开发人员。
缺点:没有较好的灵活性;性能较差。
(4)DOM4J(Document Object Model for Java)
简单易用,采用Java集合框架,并完全支持DOM、SAX和JAXP
优点:大量使用了Java集合类,方便Java开发人员,同时提供一些提高性能的替代方法;支持XPath;有很好的性能。
缺点:大量使用了接口,API较为复杂。
(5)StAX(Streaming API for XML)
StAX API的实现是使用了Java Web服务开发(JWSDP)1.6,并结合了Sun Java流式XML分析器(SJSXP)-它位于javax.xml.stream包中。XMLStreamReader接口用于分析一个XML文档,而XMLStreamWriter接口用于生成一个XML文档。XMLEventReader负责使用一个对象事件迭代子分析XML事件-这与XMLStreamReader所使用的光标机制形成对照。流模型中的拉模型分析方式提供基于指针和基于迭代器两种方式的支持,JDK1.6新特性。
和推式解析相比的优点:在拉式解析中,事件是由解析应用产生的,因此拉式解析中向客户端提供的是解析规则,而不是解析器;同推式解析相比,拉式解析的代码更简单,而且不用那么多库;拉式解析客户端能够一次读取多个XML文件;拉式解析允许你过滤XML文件和跳过解析事件。
2.3、介绍JAVA中的Collection FrameWork?
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)
Map提供key到value的映射
Collection FrameWork如下:
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set
Map
├Hashtable
├HashMap
└WeakHashMap
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector由于使用了synchronized方法(线程安全),通常性能上较ArrayList差,而LinkedList使用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable.
就ArrayList与Vector主要从二方面来说:同步性,Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步的;数据增长,当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半。
就HashMap与HashTable主要从三方面来说:历史原因,Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现;同步性,Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的;值,只有HashMap可以将空值作为一个表的条目的key或value。
对List进行排序:使用java.util.Collections的sort静态方法。一种方法是传入一个Comparator对象,另一种方法是List中的对象实现Comparable。
2.4、运行时异常与一般异常有何异同?
异常表示程序运行过程中可能出现的非正常状态,运行时异常表示虚拟机的通常操作中可能遇到的异常,是一种常见运行错误。java编译器要求方法必须声明抛出可能发生的非运行时异常,但是并不要求必须声明抛出未被捕获的运行时异常。
error表示恢复不是不可能但很困难的情况下的一种严重问题。比如说内存溢出。不可能指望程序能处理这样的情况。
exception表示一种设计或实现问题,也就是说,它表示如果程序运行正常,从不会发生的情况。
2.5、基础常识
String与StringBuffer的区别:String的长度是不可变的,StringBuffer的长度是可变的。如果你对字符串中的内容经常进行操作,特别是内容要修改时,那么使用StringBuffer,如果最后需要String,那么使用StringBuffer的toString()方法。
char型变量中能够定义成为一个中文,因为java中以unicode编码,一个char占16个字节,所以放一个中文是没问题的。
Anonymous Inner Class (匿名内部类) 可以继承其他类或完成其他接口,在swing编程中常用此方式。
Static Nested Class 和 Inner Class的不同:Static Nested Class是被声明为静态(static)的内部类,它可以不依赖于外部类实例被实例化;而通常的内部类需要在外部类实例化后才能实例化。
静态内部类可以有静态成员,而非静态内部类则不能有静态成员;静态内部类的非静态成员方法可以访问外部类的静态变量,而不可访问外部类的非静态变量;非静态内部类的非静态成员可以访问外部类的非静态变量。
Collection 和 Collections的区别:Collection是集合类的上级接口,继承与他的接口主要有Set 和List。Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
什么时候用assert:用于测试boolean表达式状态,可用于调试程序。使用方法 assert <boolean表达式>,表示如果表达式为真(true),则下面的语句执行,否则抛出AssertionError。另外的使用方式assert < boolean表达式>:<other表达式>,表示如果表达式为真,后面的表达式忽略,否则后面表达式的值用于AssertionError的构建参数。
基础中的基础:
String类是final类故不可以继承。
String s = new String(“xyz”);创建了两个String Object;
round方法返回与参数最接近的长整数,参数加1/2后求其floor:Math.round(11.5)==12;Math.round(-11.5)==-11
short s1 = 1; s1 = s1 + 1; (错误,s1+1运算结果是int型,需要强制转换类型)
short s1 = 1; s1 += 1;(可以正确编译)
float型 float f=3.4 不正确,因为精度不准确,应该用强制类型转换,float f=(float)3.4 或float f = 3.4f。在java里面,没小数点的默认是int,有小数点的默认是 double; int转成long系统自动作没有问题,因为后者精度更高;double转成float就不能自动做了,所以后面的加上个f;
一个".java"源文件中可以包括多个类(不是内部类)但是必须只有一个类名与文件名相同。
Java没有goto机制,java确实提供了goto语句,并且它是保留的关键字,但是JVM并没有给它提供任何的实现,或许是java并没打算放开使用这种机制。
数组没有length()这个方法,有length的属性;String有length()这个方法。
switch可作用于char byte short int;
switch可作用于char byte short int对应的包装类;
switch不可作用于long double float boolean,包括他们的包装类;
switch中可以是字符串类型,String(jdk1.7之后才可以作用在string上);
switch中可以是枚举类型;
final, finally, finalize的区别:
final用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
finally是异常处理语句结构的一部分,无论是否异常该部分代码总是执行。
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法。
Overload和Override的区别:方法的重写Overriding和重载Overloading是Java多态性的不同表现。重写Overriding是父类与子类之间多态性的一种表现,重载Overloading是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding),子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被“屏蔽”了。如果在一个类中定义了多个同名的方法,它们或有不同的参数个数或有不同的参数类型,则称为方法的重载(Overloading)。Overloaded的方法是可以改变返回值的类型。
接口可以继承接口,抽象类可以实现(implements)接口,抽象类可以继承实体类,因为抽象类中不仅可以有抽象方法,也可以有非抽象方法,抽象类继承了实体类则即包括自己的抽象方法也包括了继承来的非抽象方法,但是和实体类的继承一样,也要求父类拥有子类可访问到的构造器,这个构造器必须是公共的 ,可以供抽象类调用 。
try{}里有一个return语句,那么紧跟在这个try后的finally{}里的code会被执行,在return前执行。
最常见到的runtime exception:
ArithmeticException, ArrayStoreException, BufferOverflowException, BufferUnderflowException, CannotRedoException,
CannotUndoException, ClassCastException, CMMException, ConcurrentModificationException, DOMException, EmptyStackException,
IllegalArgumentException, IllegalMonitorStateException, IllegalPathStateException, IllegalStateException,
ImagingOpException, IndexOutOfBoundsException, MissingResourceException, NegativeArraySizeException, NoSuchElementException,
NullPointerException, ProfileDataException, ProviderException, RasterFormatException, SecurityException, SystemException,
UndeclaredThrowableException, UnmodifiableSetException, UnsupportedOperationException
sleep() 和 wait() 的区别:sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复,调用sleep不会释放对象锁。wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
synchronized和java.util.concurrent.locks.Lock的异同:两者功能类似,都是用来控制线程同步。Lock能完成synchronized所实现的所有功能。Lock需要在finally代码中释放锁,synchronized会自动释放锁。
启动一个线程是调用start()方法,使线程所代表的虚拟处理机处于就绪状态,以后可以由JVM调度并执行,但是并不意味着线程就会立即运行,一个线程必须关联一些具体的执行代码,run()方法是该线程所关联的执行代码,run()方法也可以产生必须退出的标志来停止一个线程。
多线程有两种实现方法,分别是继承Thread类与实现Runnable接口;
同步的实现方面有两种,分别是synchronized,wait与notify;
当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?
当一个线程进入一个对象的synchronized()方法后,其他线程是否可以进入此对象的其他方法取决于方法本身,如果该方法是非synchronized()方法,那么是可以访问的;如果是synchronized()方法,那么不能访问,因为上一个方法使用了对象锁;如果其他方法是静态的方法,它用的同步锁是当前类的字节码,因此静态方法可以被调用。
当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,这里是值传递,Java 编程语言只由值传递参数,当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用,对象的内容可以在被调用的方法中改变,但对象的引用是永远不会改变的。
Class.forName()返回一个以字符串指定类名的类的对象;
什么是java序列化,如何实现java序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。
序列化的实现:将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
2.6、abstract的method是否可同时是static、native或synchronized的?
- abstract修饰的方法是抽象的方法,只有声明而没有实现,他的实现要放入声明该类的子类中实现。
- static是静态的,是一种属于类而不属于对象的方法或者属性。
- synchronized 是同步,是一种相对线程的锁。
- native 本地方法,这种方法和抽象方法及其类似,它也只有方法声明,没有方法实现,但是与抽象方法不同的是,它把具体实现移交给了本地系统的函数库,而没有通过虚拟机,可以说是Java与其它语言通讯的一种机制。
首先abstract与static,声明static说明可以直接用类名调用该方法,声明abstract说明需要子类重写该方法,如果同时声明static和abstract,用类名调用一个抽象方法是不行的。因为抽象方法是不能被调用的,原因就是抽象方法没有方法体。但是,在一个类中定义了一个抽象方法,在这个类或其子类中是可以调用的。因为,具有抽象方法的类,一定是一个抽象类,而抽象类在被继承的时候,必须重写这个抽象类的抽象方法,而且,抽象类不能实例化,在使用这个抽象类的时候,使用的一定是这个抽象类的子类。因此在抽象类或其子类中可以使用这个抽象方法,是因为当真正实例化去使用的时候,使用的是子类重写后的实例方法。
synchronized 是同步,然而同步是需要有具体操作才能同步的,如果像abstract只有方法声明,那么就不知道同步什么代码了,当然抽象方法在被子类继承以后,可以添加同步。
native 这个东西本身就和abstract冲突,他们都是方法的声明,只是一个把方法实现移交给子类,另一个是移交给本地操作系统。如果同时出现,就相当于即把实现移交给子类,又把实现移交给本地操作系统,那到底谁来实现具体方法呢
另附:不能放在一起的修饰符:final和abstract,private和abstract,static和abstract,因为abstract修饰的方法是必须在其子类中实现,才能以多态方式调用,以上修饰符在修饰方法时期子类都覆盖不了这个方法,final是不可以覆盖,private是不能够继承到子类,所以也就不能覆盖,static是可以覆盖的,但是在调用时会调用编译时类型的方法,因为调用的是父类的方法,而父类的方法又是抽象的方法,又不能够调用,所以上的修饰符不能放在一起。
2.7、静态变量、静态方法、静态代码块
类的生命周期分为装载、连接、初始化、使用和卸载的五个过程。其中静态代码在类的初始化阶段被初始化,而非静态代码则在类的使用阶段(也就是实例化一个类的时候)才会被初始化。
静态变量:可以将静态变量理解为类变量(与对象无关),而实例变量则属于一个特定的对象。
静态变量有两种情况:
静态变量是基本数据类型,这种情况下在类的外部不必创建该类的实例就可以直接使用;
静态变量是一个引用。这种情况比较特殊,主要问题是由于静态变量是一个对象的引用,那么必须初始化这个对象之后才能将引用指向它。因此如果要把一个引用定义成static的,就必须在定义的时候就对其对象进行初始化。
静态方法:与类变量不同,方法(静态方法与实例方法)在内存中只有一份,无论该类有多少个实例,都共用一个方法。
静态方法与实例方法的不同主要有:
静态方法可以直接使用,而实例方法必须在类实例化之后通过对象来调用。
在外部调用静态方法时,可以使用“类名.方法名”或者“对象名.方法名”的形式,实例方法只能使用后面这种方式。
静态方法只允许访问静态成员。而实例方法中可以访问静态成员和实例成员。
静态方法中不能使用this(因为this是与实例相关的)。
静态代码块:在java类中,可以将某一块代码声明为静态的。静态代码块主要用于类的初始化,它只执行一次。
静态代码块的特点主要有:
静态代码块会在类被加载时自动执行。
静态代码块只能定义在类里面,不能定义在方法里面。
静态代码块里的变量都是局部变量,只在块内有效。
一个类中可以定义多个静态代码块,按顺序执行。
静态代码块只能访问类的静态成员,而不允许访问实例成员。
下面看一段代码:
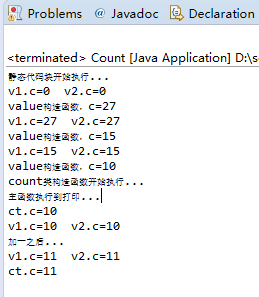
1 package com.zyr.world; 2 3 class Value { 4 static int c = 0; 5 6 Value() { 7 c = 100; 8 } 9 10 Value(int i) { 11 c = i; 12 System.out.println("value构造函数,c="+i); 13 } 14 15 static void inc() { 16 c++; 17 } 18 } 19 20 class Count { 21 22 public Count(){ 23 prt("count类构造函数开始执行..."); 24 } 25 26 public static void prt(String s) { 27 System.out.println(s); 28 } 29 30 //在构造函数之前执行 31 Value v = new Value(10); 32 33 //在静态代码块执行完之后执行 34 static Value v1, v2; 35 36 //类加载的时候执行 37 static { 38 prt("静态代码块开始执行..."); 39 prt("v1.c=" + v1.c + " v2.c=" + v2.c); 40 v1 = new Value(27); 41 prt("v1.c=" + v1.c + " v2.c=" + v2.c); 42 v2 = new Value(15); 43 prt("v1.c=" + v1.c + " v2.c=" + v2.c); 44 } 45 46 public static void main(String[] args) { 47 Count ct = new Count(); 48 prt("主函数执行到打印..."); 49 prt("ct.c=" + ct.v.c); 50 prt("v1.c=" + v1.c + " v2.c=" + v2.c); 51 v1.inc(); 52 prt("加一之后..."); 53 prt("v1.c=" + v1.c + " v2.c=" + v2.c); 54 prt("ct.c=" + ct.v.c); 55 } 56 }
从上面的代码中我们可以理解静态代码块、静态变量、构造函数的初始化顺序,如果再加上继承关系我们更能深刻理解这些组成之间的关系了,另一方面我们在类中只定义了一个变量,并且是静态的,因此在所有的操作之中,其实只有这一个变量(静态变量)来作为对象的组成部分,也就是只有一个对象的内存再使用,我们可以理解为这些引用其实都是指向同一块内存的,根据不同的执行顺序进行修改,从而得到不同的结果。
2.8、JSP基础知识
JSP共有以下9种基本内置组件:
request:用户端请求,此请求会包含来自GET/POST请求的参数
response:网页传回用户端的回应
pageContext:网页的属性是在这里管理
session:与请求有关的会话期
application:servlet正在执行的内容
out:用来传送回应的输出
config:servlet的构架部件
page:JSP网页本身
exception:针对错误网页,未捕捉的例外
JSP共有以下6种基本动作:
jsp:include:在页面被请求的时候引入一个文件。
jsp:useBean:寻找或者实例化一个JavaBean。
jsp:setProperty:设置JavaBean的属性。
jsp:getProperty:输出某个JavaBean的属性。
jsp:forward:把请求转到一个新的页面。
jsp:plugin:根据浏览器类型为Java插件生成OBJECT或EMBED标记。
JSP中动态include用jsp:include动作实现,它总是会检查所含文件中的变化,适合用于包含动态页面,并且可以带参数;静态include用include伪码实现,不会检查所含文件的变化,适用于包含静态页面。
JSP四大属性范围:
pageContext:作用域是当前页面。
request:作用域是一次请求。
session:作用域是一个客户端会话。
application:作用域是整个应用,所有用户共享。
JSP两种include有什么区别?
include指令:<%@include file=”MyJsp.jsp” %>
可以引用各种文本文件,包括jsp文件,只是单纯的将文件合并,生成Servlet。file是只文件路径,必须是实实在在的文件。
jsp:include标签:<jsp:include page=”MyJsp.jsp” flush=”true”></jsp:include>
不是简单的文本合并,而是两个独立的页面。可以理解为将这个页面的运行结果引用进来。page是页面地址,例如可以是Servlet,所以不一定是一个存在的文件,而是一个可以访问的地址。它当然还能带参数,但是include指令不能。
redirect和forward的区别:
redirect是服务器发给客户端一个状态码为3XX的响应,由客户端负责跳转,所以浏览器地址栏显示的是跳转后的地址。
forward又叫转发,是服务器内部的跳转,客户端是不知道的,所以浏览器地址栏显示的是跳转前的地址。
2.9、HTTP、Servlet
GET和POST有什么区别:GET请求参数会在地址栏显示,POST不会。POST提交的数据可以比GET更大,类型更多,例如上传文件需要用POST。POST更安全。本质的区别是,GET请求一般没有请求body,参数直接写在URL中,POST请求参数在请求body中。
Session和Cookie区别:Cookie保存在客户端,而Session保存在服务器上;Session一般是通过Cookie中添加一项sessionid来实现功能,但是如果客户端禁用Cookie的话,也可以将sessionid写在url中;Session一般关闭浏览器后再打开就无效了,实际上是因为Cookie中的Sessionid失效而不是服务器保存的Session失效;Session可以用来做登陆后保持登陆状态,Cookie可以做例如一个月自动登陆这样的功能。
Servlet生命周期:
init初始化,整个生命周期只调用一次。
service处理请求,每次请求调用一次。
destroy销毁, 整个生命周期只调用一次。
JSP和Servlet的相同和不同:
相同:JSP本质上是Servlet,最后会转换成servlet执行。
不同:用法不同,在MVC模式中,Servlet用来做控制器,用于处理用户请求和业务逻辑,再跳转到相应的JSP,JSP一般用来做页面显示。
2.10、java中的堆和栈
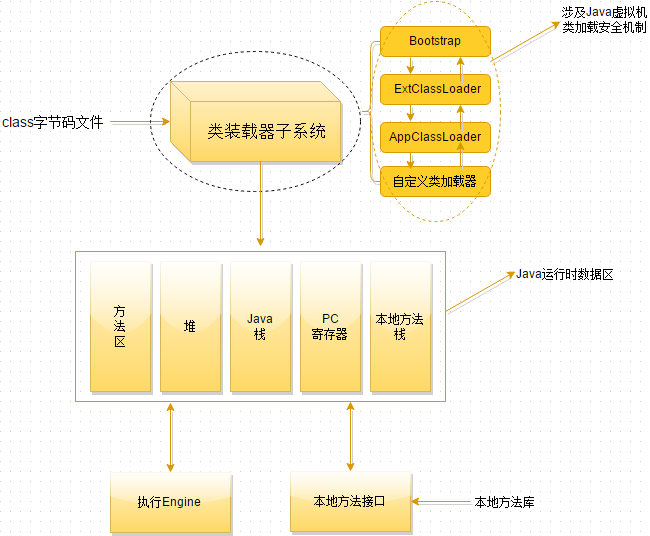
Java中对象都是分配在heap(堆)中,从heap中分配内存所消耗的时间远远大于从stack产生存储空间所需的时间。
(1)每个应用程序运行时,都有属于自己的一段内存空间,用于存放临时变量、参数传递、函数调用时的PC值的保存。这叫stack。
(2)所有的应用可以从一个系统共用的空间中申请供自己使用的内存,这个共用的空间叫heap。
(3)stack中的对象或变量只要定义好就可使用了,应用程序结束时会自动释放。
(4)而要使用heap中申请的变量或对象只能定义变量指针,并要求在运行过程中通过new来动态分配内存空间,而且必须显式地free申请过的内存,不过Java的垃圾回收机解决了这个问题,它会释放这部分内存。
(5)stack中变量的大小和个数会影响exe的文件大小,但速度快。堆中的变量大小与exe大小关系不大,但分配和释放需要耗费的时间远大于stack中分配内存所需的时间。
栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。
栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性,栈数据可以共享。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据,但缺点是,由于要在运行时动态分配内存,存取速度较慢。
int a = 3; //放在栈中 int b = 3;//栈中已有,直接指向 a = 4;//栈中没有,再次创建并指向
对于基本类型是存放在栈中的,对于a,b在栈中其实是共享内存的,特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与 b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
每个JVM的线程都有自己的私有的栈空间,随线程创建而创建,java的stack存放的是frames ,java的stack和c的不同,只是存放本地变量,返回值和调用方法,不允许直接push和pop frames ,因为frames 可能是有heap分配的,所以java的stack分配的内存不需要是连续的。java的heap是所有线程共享的,堆存放所有 runtime data ,里面是所有的对象实例和数组,heap是JVM启动时创建。
String str1 = "abc";//放在栈中 String str2 = "abc";//栈中已有,直接指向 System.out.println(str1==str2); //true String str1 = new String("abc");//放入堆中 String str2 = "abc"; //放入栈中 System.out.println(str1==str2); //false
只要是用new()来新建对象的,都会在堆中创建,即使与栈中的数据相同,也不会与栈中的数据共享。
当比较包装类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用== 。
两个对象值相同(x.equals(y) == true),但却可有不同的hashcode,这句话也对,也不对。
如果此对象重写了equals方法,那么可能出现这两个对象的equals相同,而hashcode不同。
如果此对象继承Object,没有重写equals方法,那么就使用Object的equals方法,Object对象的equals方法默认是用==实现的,那么如果equals相同,hashcode一定相同。String重写了equals方法,只要两个引用所指向的对象是两块含有一样字样的字符串的话,那么就返回true。
三、总结
写了这么多基础的知识,有很多都是我们容易混淆的,也是面试的时候喜欢问到的,当然除了这些之外还有编写代码的能力,这些代码一般涉及到了数据库、设计模式、多线程、文件读写、数据结构等知识,需要我们多练习,多思考,多记忆。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号