如何在Ubuntu的idea上运行Hadoop程序
如何在Ubuntu的idea上运行Hadoop程序
一、前言
在idea上运行Hadoop程序,需要使用Hadoop的相关库,Ubuntu为Hadoop的运行提供了良好的支持。
二、操作方法
首先我们需要创建一个maven项目,然后在pom.xml中进行设置,导入必要的包,最后写出mapreduce程序即可。
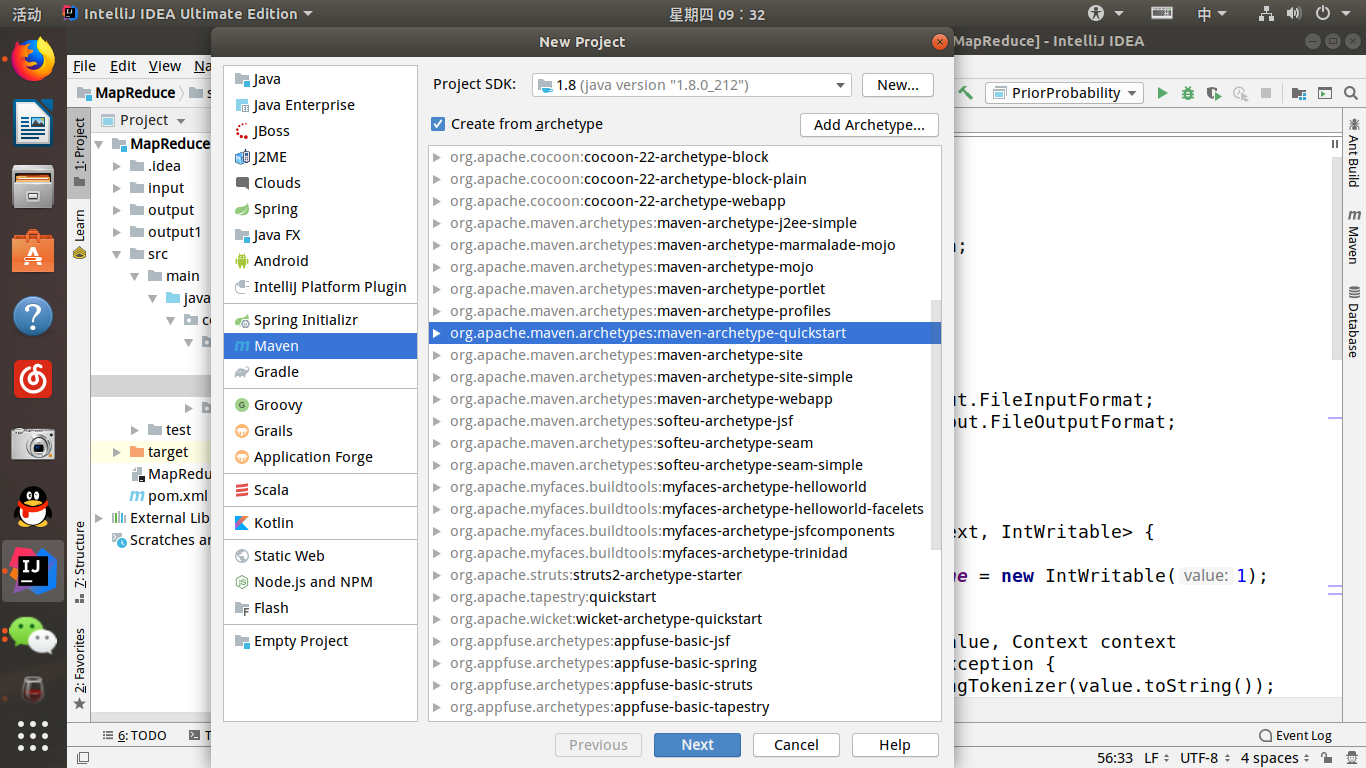
其中pom.xml文件如下:
1 <?xml version="1.0" encoding="UTF-8"?> 2 3 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 5 <modelVersion>4.0.0</modelVersion> 6 7 <groupId>com.zyr.bigdata</groupId> 8 <artifactId>MapReduce</artifactId> 9 <version>1.0-SNAPSHOT</version> 10 11 <name>MapReduce</name> 12 <!-- FIXME change it to the project's website --> 13 <url>http://www.example.com</url> 14 15 <properties> 16 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> 17 <maven.compiler.source>1.7</maven.compiler.source> 18 <maven.compiler.target>1.7</maven.compiler.target> 19 </properties> 20 21 <dependencies> 22 <dependency> 23 <groupId>junit</groupId> 24 <artifactId>junit</artifactId> 25 <version>4.11</version> 26 <scope>test</scope> 27 </dependency> 28 29 <dependency> 30 <groupId>org.apache.hadoop</groupId> 31 <artifactId>hadoop-core</artifactId> 32 <version>1.2.1</version> 33 </dependency> 34 35 <dependency> 36 <groupId>org.apache.hadoop</groupId> 37 <artifactId>hadoop-common</artifactId> 38 <version>2.9.0</version> 39 </dependency> 40 41 </dependencies> 42 43 <build> 44 <pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) --> 45 <plugins> 46 <!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle --> 47 <plugin> 48 <artifactId>maven-clean-plugin</artifactId> 49 <version>3.1.0</version> 50 </plugin> 51 <!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging --> 52 <plugin> 53 <artifactId>maven-resources-plugin</artifactId> 54 <version>3.0.2</version> 55 </plugin> 56 <plugin> 57 <artifactId>maven-compiler-plugin</artifactId> 58 <version>3.8.0</version> 59 </plugin> 60 <plugin> 61 <artifactId>maven-surefire-plugin</artifactId> 62 <version>2.22.1</version> 63 </plugin> 64 <plugin> 65 <artifactId>maven-jar-plugin</artifactId> 66 <version>3.0.2</version> 67 </plugin> 68 <plugin> 69 <artifactId>maven-install-plugin</artifactId> 70 <version>2.5.2</version> 71 </plugin> 72 <plugin> 73 <artifactId>maven-deploy-plugin</artifactId> 74 <version>2.8.2</version> 75 </plugin> 76 <!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle --> 77 <plugin> 78 <artifactId>maven-site-plugin</artifactId> 79 <version>3.7.1</version> 80 </plugin> 81 <plugin> 82 <artifactId>maven-project-info-reports-plugin</artifactId> 83 <version>3.0.0</version> 84 </plugin> 85 </plugins> 86 </pluginManagement> 87 </build> 88 </project>
然后是编写代码:
package com.zyr.bigdata; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
因为是mapreduce的词频统计,因此需要读入文件,在src同级创建input文件夹,里面放入文档即可。
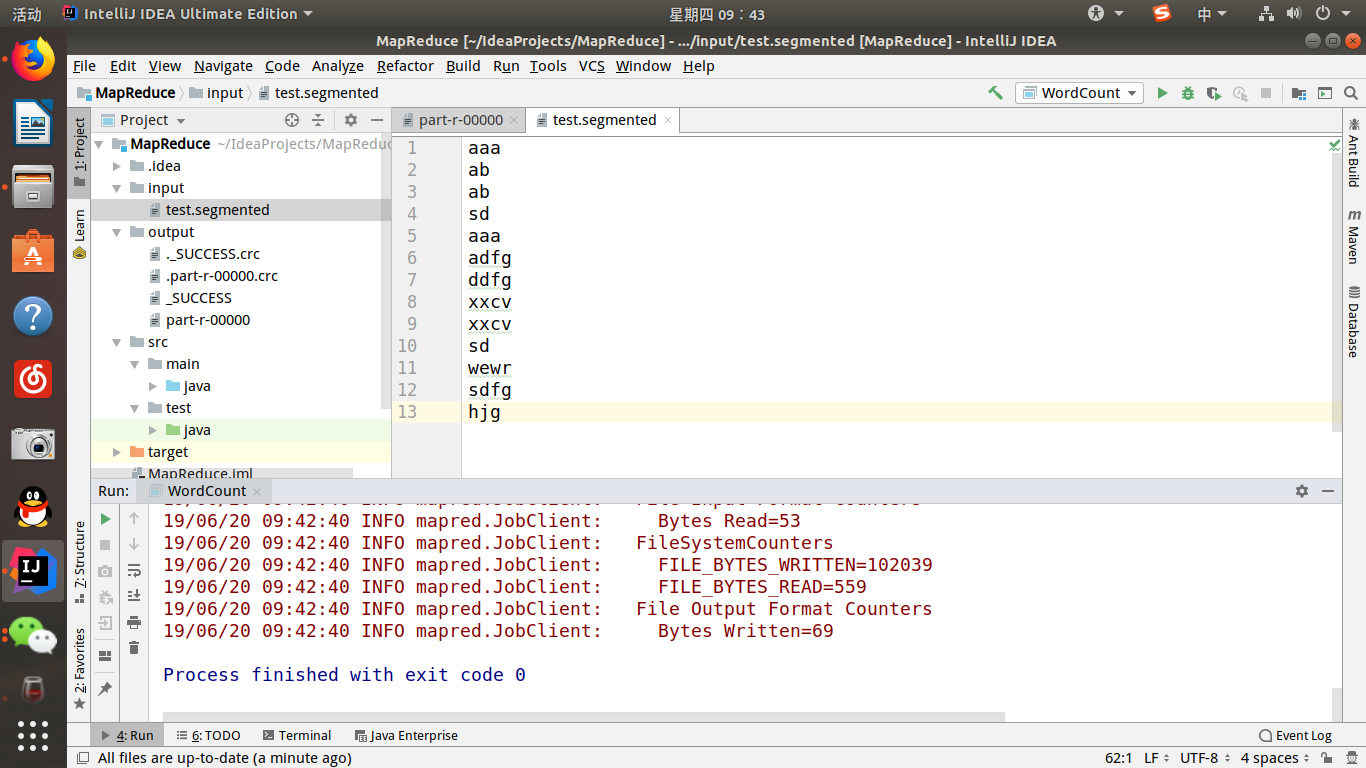
最后需要配置执行程序的设置(在run->edit configure中新建application即可):
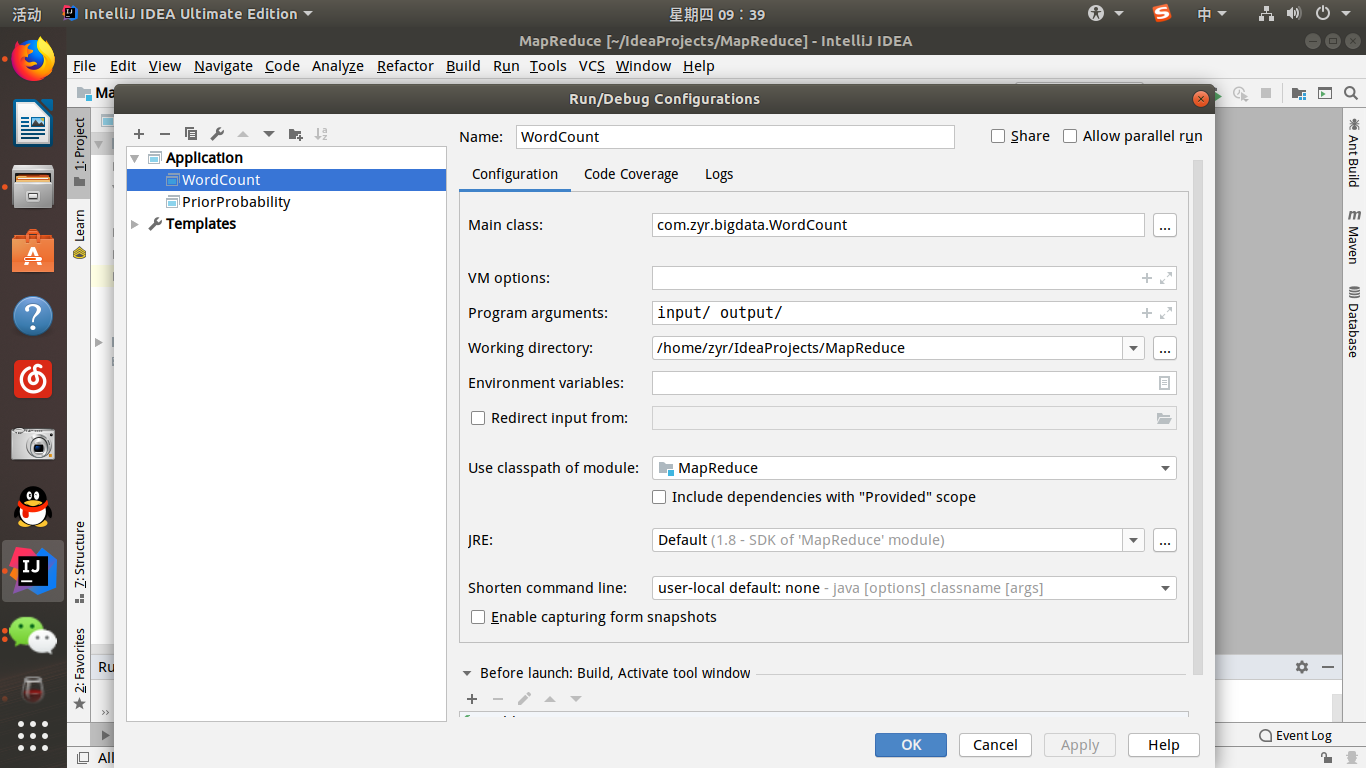
然后运行程序,会生成相应的output文件夹,打开即可查看结果。 
至此,最简单的mapreduce程序就完成了,需要注意的是使用maven我们没有在ubuntu上安装相应的Hadoop,因为这是最简单的单机环境,使用的是本地文件系统,但是如果使用分布式的时候就必须需要本地安装Hadoop来提供访问服务了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号