

Helm及其他功能性组件
在没使用 helm 之前,向 kubernetes 部署应用,我们要依次部署 deployment、svc 等,步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂。helm 通过打包的方式,支持发布的版本管理和控制,很大程度上简化了 Kubernetes 应用的部署和管理
Helm 本质就是让 K8s 的应用管理(Deployment,Service 等 ) 可配置,能动态生成。通过动态生成 K8s 资源清单文件(deployment.yaml,service.yaml)。然后调用 Kubectl 自动执行 K8s 资源部署
Helm 是官方提供的类似于 YUM 的包管理器,是部署环境的流程封装。Helm 有两个重要的概念:chart 和release
-
chart 是创建一个应用的信息集合,包括各种 Kubernetes 对象的配置模板、参数定义、依赖关系、文档说
明等。chart 是应用部署的自包含逻辑单元。可以将 chart 想象成 apt、yum 中的软件安装包
-
release 是 chart 的运行实例,代表了一个正在运行的应用。当 chart 被安装到 Kubernetes 集群,就生成
一个 release。chart 能够多次安装到同一个集群,每次安装都是一个 release
Helm 包含两个组件:Helm 客户端和 Tiller 服务器,如下图所示
在没使用 helm 之前,向 kubernetes 部署应用,我们要依次部署 deployment、svc 等,步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂。helm 通过打包的方式,支持发布的版本管理和控制,很大程度上简化了 Kubernetes 应用的部署和管理
Helm 本质就是让 K8s 的应用管理(Deployment,Service 等 ) 可配置,能动态生成。通过动态生成 K8s 资源清单文件(deployment.yaml,service.yaml)。然后调用 Kubectl 自动执行 K8s 资源部署
Helm 是官方提供的类似于 YUM 的包管理器,是部署环境的流程封装。Helm 有两个重要的概念:chart 和release
-
chart 是创建一个应用的信息集合,包括各种 Kubernetes 对象的配置模板、参数定义、依赖关系、文档说
明等。chart 是应用部署的自包含逻辑单元。可以将 chart 想象成 apt、yum 中的软件安装包
-
release 是 chart 的运行实例,代表了一个正在运行的应用。当 chart 被安装到 Kubernetes 集群,就生成
一个 release。chart 能够多次安装到同一个集群,每次安装都是一个 release
Helm 包含两个组件:Helm 客户端和 Tiller 服务器,如下图所示
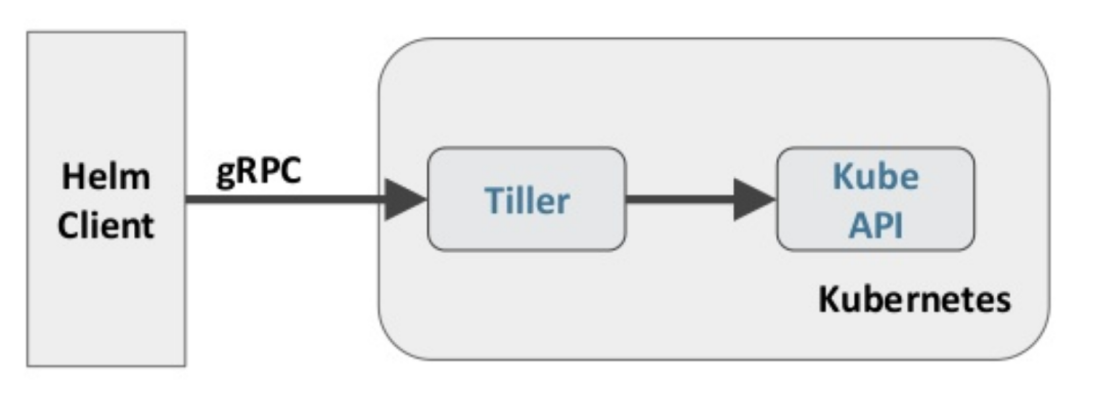
Helm 客户端负责 chart 和 release 的创建和管理以及和 Tiller 的交互。Tiller 服务器运行在 Kubernetes 集群中,它会处理 Helm 客户端的请求,与 Kubernetes API Server 交互
注意:在Helm3中没有了Tiller!
Helm 部署
越来越多的公司和团队开始使用 Helm 这个 Kubernetes 的包管理器,我们也将使用 Helm 安装 Kubernetes 的常用组件。 Helm 由客户端命 helm 令行工具和服务端 tiller 组成,Helm 的安装十分简单。 下载 helm 命令行工具到master 节点 node1 的 /usr/local/bin 下,这里下载的 2.13. 1版本:
ntpdate ntp1.aliyun.com
wget https://storage.googleapis.com/kubernetes-helm/helm-v2.13.1-linux-amd64.tar.gz
tar -zxvf helm-v2.13.1-linux-amd64.tar.gz
cd linux-amd64/
cp helm /usr/local/bin/
[root@k8s-master01 ~]# cd /usr/local/install-k8s/
[root@k8s-master01 install-k8s]# ls
cert core plugin
[root@k8s-master01 install-k8s]# mkdir helm
[root@k8s-master01 helm]# rz -E
rz waiting to receive.
[root@k8s-master01 helm]# ls
helm-v2.14.2-linux-amd64.tar.gz helm-v2.14.2-linux-amd64.tar.gz.0
[[root@k8s-master01 helm]# tar -zxvf helm-v2.14.2-linux-amd64.tar.gz
[root@k8s-master01 helm]# cp -a linux-amd64/helm /usr/local/bin/
[root@k8s-master01 helm]# chmod a+x /usr/local/bin/helm
[root@k8s-master01 helm]#
为了安装服务端 tiller,还需要在这台机器上配置好 kubectl 工具和 kubeconfig 文件,确保 kubectl 工具可以在这台机器上访问 apiserver 且正常使用。 这里的 node1 节点以及配置好了 kubectl
因为 Kubernetes APIServer 开启了 RBAC 访问控制,所以需要创建 tiller 使用的 service account: tiller 并分配合适的角色给它。 详细内容可以查看helm文档中的 Role-based Access Control。 这里简单起见直接分配cluster- admin 这个集群内置的 ClusterRole 给它。创建 rbac-config.yaml 文件:
apiVersion
kubectl create -f rbac-config.yaml
helm init --service-account tiller --skip-refresh
我们初始化时报错:
[root@k8s-master01 helm]# helm init --service-account tiller --skip-refresh
$HELM_HOME has been configured at /root/.helm.
Error: error installing: the server could not find the requested resource (post deployments.extensions)
参考此博客解决
(42条消息) kubenetes1.16.0 安装helm报错与解决办法_dz45693的博客-CSDN博客
[root@k8s-master01 helm]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6d8c4cb4d-dqwn8 1/1 Running 16 (12h ago) 17d
coredns-6d8c4cb4d-lx9c6 1/1 Running 16 (12h ago) 17d
etcd-k8s-master01 1/1 Running 17 (12h ago) 17d
kube-apiserver-k8s-master01 1/1 Running 16 (12h ago) 17d
kube-controller-manager-k8s-master01 1/1 Running 16 (12h ago) 17d
kube-flannel-ds-22h2x 1/1 Running 4 (12h ago) 2d
kube-flannel-ds-7c2gn 1/1 Running 3 (12h ago) 2d
kube-flannel-ds-gcfpm 1/1 Running 16 (12h ago) 17d
kube-proxy-ht4bl 1/1 Running 15 (12h ago) 17d
kube-proxy-scjvz 1/1 Running 16 (12h ago) 17d
kube-proxy-t68wn 1/1 Running 15 (12h ago) 17d
kube-scheduler-k8s-master01 1/1 Running 16 (12h ago) 17d
tiller-deploy-9c4c59f49-qlrw2 0/1 ImagePullBackOff 0 2m3s
发现镜像下载失败,在每个节点上执行这两条命令,之后pod就running了!
[root@k8s-node01 ~]# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.2
v2.14.2: Pulling from google_containers/tiller
e7c96db7181b: Pull complete
c0dd79d56e9d: Pull complete
38dd4ab305dd: Pull complete
cf4c7ece0931: Pull complete
Digest: sha256:be79aff05025bd736f027eaf4a1b2716ac1e09b88e0e9493c962642519f19d9c
Status: Downloaded newer image for registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.2
registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.2
[root@k8s-node01 ~]# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/tiller:v2.14.2 gcr.io/kubernetes-helm/tiller:v2.14.2
[root@k8s-node01 ~]#
tiller 默认被部署在 k8s 集群中的 kube-system 这个namespace 下
kubectl get pod -n kube-system -l app=helm
NAME READY STATUS RESTARTS AGE
tiller-deploy-c4fd4cd68-dwkhv 1/1 Running 0 83s
helm version
Client
[root@k8s-master01 helm]# kubectl get pod -n kube-system -l app=helm
NAME READY STATUS RESTARTS AGE
tiller-deploy-9c4c59f49-rbvbv 1/1 Running 0 59m
[root@k8s-master01 helm]#
[root@k8s-master01 helm]# helm version(可以看到helm版本信息)
Client: &version.Version{SemVer:"v2.14.2", GitCommit:"a8b13cc5ab6a7dbef0a58f5061bcc7c0c61598e7", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.14.2", GitCommit:"a8b13cc5ab6a7dbef0a58f5061bcc7c0c61598e7", GitTreeState:"clean"}
[root@k8s-master01 helm]#
Helm 自定义模板
# 创建文件夹
$ mkdir ./hello-world
$ cd ./hello-world
# 创建自描述文件 Chart.yaml , 这个文件必须有 name 和 version 定义
$ cat <<'EOF' > ./Chart.yaml
name
[root@k8s-master01 helm]# mkdir test
[root@k8s-master01 helm]# cd test/
[root@k8s-master01 test]# cat <<'EOF' > ./Chart.yaml
> name: hello-world
> version: 1.0.0
> EOF
[root@k8s-master01 test]#
# 创建模板文件, 用于生成 Kubernetes 资源清单(manifests)
$ mkdir ./templates
$ cat <<'EOF' > ./templates/deployment.yaml
apiVersion
# 使用命令 helm install RELATIVE_PATH_TO_CHART 创建一次Release
$ helm install
[root@k8s-master01 test]# helm install .
Error: no available release name found
这里会报错!
参考此博客
https://www.cnblogs.com/zypdbk/p/16500623.html
[root@k8s-master01 test]# helm install .(这时就可以看到描述信息了!)
NAME: muddled-wolverine
LAST DEPLOYED: Thu Jul 21 08:45:25 2022
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
hello-world 0/1 0 0 0s
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
hello-world-758f99dbc7-jnpzw 0/1 Pending 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world NodePort 10.106.182.159 <none> 80:32522/TCP 0s
# 列出已经部署的 Release
$ helm ls
# 查询一个特定的 Release 的状态
$ helm status RELEASE_NAME
# 移除所有与这个 Release 相关的 Kubernetes 资源
$ helm delete cautious-shrimp
# helm rollback RELEASE_NAME REVISION_NUMBER
$ helm rollback cautious-shrimp 1
# 使用 helm delete --purge RELEASE_NAME 移除所有与指定 Release 相关的 Kubernetes 资源和所有这个
Release 的记录
$ helm delete --purge cautious-shrimp
$ helm ls --deleted
[root@k8s-master01 test]# helm list
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
garish-kangaroo 1 Thu Jul 21 08:43:01 2022 FAILED hello-world-1.0.0 default
illmannered-gerbil 1 Thu Jul 21 08:40:29 2022 FAILED hello-world-1.0.0 default
invited-mule 1 Thu Jul 21 08:39:37 2022 FAILED hello-world-1.0.0 default
kindled-pronghorn 1 Thu Jul 21 08:35:44 2022 FAILED hello-world-1.0.0 default
muddled-wolverine 1 Thu Jul 21 08:45:25 2022 DEPLOYED hello-world-1.0.0 default
singed-salamander 1 Thu Jul 21 08:45:17 2022 FAILED hello-world-1.0.0 default
wrinkled-wombat 1 Thu Jul 21 08:42:47 2022 FAILED hello-world-1.0.0 default
[root@k8s-master01 test]# vim templates/deployment.yaml
[root@k8s-master01 test]#
修改下nginx的版本
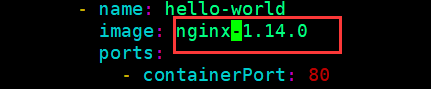
[root@k8s-master01 test]# helm upgrade muddled-wolverine .(更新一下)
Release "muddled-wolverine" has been upgraded.
LAST DEPLOYED: Thu Jul 21 09:05:26 2022
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
hello-world 1/1 1 1 20m
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
hello-world-758f99dbc7-jnpzw 1/1 Running 0 20m
hello-world-7cddc87856-ql8x6 0/1 ContainerCreating 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world NodePort 10.106.182.159 <none> 80:32522/TCP 20m
[root@k8s-master01 test]# helm list(版本已经更新)
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
garish-kangaroo 1 Thu Jul 21 08:43:01 2022 FAILED hello-world-1.0.0 default
illmannered-gerbil 1 Thu Jul 21 08:40:29 2022 FAILED hello-world-1.0.0 default
invited-mule 1 Thu Jul 21 08:39:37 2022 FAILED hello-world-1.0.0 default
kindled-pronghorn 1 Thu Jul 21 08:35:44 2022 FAILED hello-world-1.0.0 default
muddled-wolverine 2 Thu Jul 21 09:05:26 2022 DEPLOYED hello-world-1.0.0 default
singed-salamander 1 Thu Jul 21 08:45:17 2022 FAILED hello-world-1.0.0 default
wrinkled-wombat 1 Thu Jul 21 08:42:47 2022 FAILED hello-world-1.0.0 default
[root@k8s-master01 test]#
[root@k8s-master01 test]# helm history muddled-wolverine(查看历史版本信息)
REVISION UPDATED STATUS CHART DESCRIPTION
1 Thu Jul 21 08:45:25 2022 SUPERSEDED hello-world-1.0.0 Install complete
2 Thu Jul 21 09:05:26 2022 DEPLOYED hello-world-1.0.0 Upgrade complete
[root@k8s-master01 test]#
[root@k8s-master01 test]# helm status muddled-wolverine (查看下状态)
LAST DEPLOYED: Thu Jul 21 09:05:26 2022
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
hello-world 1/1 1 1 24m
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
hello-world-758f99dbc7-jnpzw 1/1 Running 0 24m
hello-world-7cddc87856-ql8x6 0/1 ErrImagePull 0 3m59s(我们可以看到,镜像拉取失败)
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world NodePort 10.106.182.159 <none> 80:32522/TCP 24m(可以通过ip+端口来访问)
理解:
在docker里,我们是把一个应用程序打包为一个镜像,部署应用程序时运行镜像即可;
而k8s里的helm,我们是把集群的部署方案写入到Chart里,然后通过Chart生成一个集群,也就是Release!
# 配置体现在配置文件 values.yaml
$ cat <<'EOF' > ./values.yaml
image
[root@k8s-master01 test]# cat <<'EOF' > ./values.yaml
> image:
> repository: nginx
> tag: ''
> EOF
[root@k8s-master01 test]# ls
Chart.yaml templates values.yaml
[root@k8s-master01 test]# vim templates/deployment.yaml
[root@k8s-master01 test]#

[root@k8s-master01 test]# helm upgrade muddled-wolverine .
[root@k8s-master01 test]# kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-world-6649c5dbfc-5pqf5 1/1 Running 0 72s
myweb1-595fcc486f-2tmjn 1/1 Running 5 (24h ago) 3d10h
myweb1-595fcc486f-59gj4 1/1 Running 5 (24h ago) 3d10h
myweb1-595fcc486f-75rng 1/1 Running 5 (24h ago) 3d10h
myweb1-595fcc486f-dqwzf 1/1 Running 5 (24h ago) 3d10h
myweb1-595fcc486f-khfb5 1/1 Running 5 (24h ago) 3d10h
myweb1-595fcc486f-s2c9f 1/1 Running 5 (17m ago) 3d10h
myweb1-595fcc486f-s5dqd 1/1 Running 5 (17m ago) 3d10h
myweb1-595fcc486f-vhc2t 1/1 Running 5 (24h ago) 3d10h
# 在 values.yaml 中的值可以被部署 release 时用到的参数 --values YAML_FILE_PATH 或 --set
key1=value1, key2=value2 覆盖掉
$ helm install --set image.tag='latest' .
# 升级版本
helm upgrade -f values.yaml test .
[root@k8s-master01 test]# helm upgrade muddled-wolverine --set image.tag='latest' .
Release "muddled-wolverine" has been upgraded.
LAST DEPLOYED: Fri Jul 22 10:21:09 2022
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
hello-world 1/1 0 1 25h
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
hello-world-6649c5dbfc-5pqf5 1/1 Running 0 8m53s
hello-world-7b647cdc98-qxr7j 0/1 ContainerCreating 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world NodePort 10.106.182.159 <none> 80:32522/TCP 25h
[root@k8s-master01 test]# helm delete muddled-wolverine(删除release)
release "muddled-wolverine" deleted
[root@k8s-master01 test]# helm install --name muddled-wolverine(重新下载不成功。报错,已经存在)
Error: This command needs 1 argument: chart name
[root@k8s-master01 test]# helm install --name muddled-wolverine .
Error: a release named muddled-wolverine already exists.
Run: helm ls --all muddled-wolverine; to check the status of the release
Or run: helm del --purge muddled-wolverine; to delete it
[root@k8s-master01 test]# helm list --deleted(其实这里还是有的)
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
muddled-wolverine 6 Fri Jul 22 10:21:09 2022 DELETED hello-world-1.0.0 default
[root@k8s-master01 test]# helm rollback muddled-wolverine 6(回滚)
Rollback was a success.
[root@k8s-master01 test]# helm list
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
muddled-wolverine 7 Fri Jul 22 10:30:35 2022 DEPLOYED hello-world-1.0.0 default
[root@k8s-master01 test]#
[root@k8s-master01 test]# helm status muddled-wolverine
LAST DEPLOYED: Fri Jul 22 10:30:35 2022
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
hello-world 1/1 1 1 2m14s
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
hello-world-7b647cdc98-nfs76 1/1 Running 0 2m14s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-world NodePort 10.105.177.56 <none> 80:30573/TCP 2m14s
[root@k8s-master01 test]# 
[root@k8s-master01 test]# helm delete --purge muddled-wolverine (彻底删除)
release "muddled-wolverine" deleted
[root@k8s-master01 test]# helm list --deleted(这里为空!)
[root@k8s-master01 test]#
Debug
# 使用模板动态生成K8s资源清单,非常需要能提前预览生成的结果。
# 使用--dry-run --debug 选项来打印出生成的清单文件内容,而不执行部署
helm install . --dry-run --debug --set image.tag=latest
[root@k8s-master01 test]# helm install --dry-run .(简单测试运行一下)
NAME: trendsetting-sponge
[root@k8s-master01 test]# helm list(实际上并没有)
[root@k8s-master01 test]#
kubernetes-dashboard.yaml:
image
helm install stable/kubernetes-dashboard \
-n kubernetes-dashboard \
--namespace kube-system \
-f kubernetes-dashboard.yaml
kubectl -n kube-system get secret | grep kubernetes-dashboard-token
[root@k8s-master01 dashboard]# helm fetch stable/kubernetes-dashboard(先下载一下)
Error: no cached repo found. (try 'helm repo update'). open /root/.helm/repository/cache/stable-index.yaml: no such file or directory(报错,需要更新仓库)
[root@k8s-master01 dashboard]# helm repo update(更新仓库)
Hang tight while we grab the latest from your chart repositories...
...Skip local chart repository
...Unable to get an update from the "stable" chart repository (https://kubernetes-charts.storage.googleapis.com):
Failed to fetch https://kubernetes-charts.storage.googleapis.com/index.yaml : 403 Forbidden
Update Complete.
[root@k8s-master01 dashboard]# helm fetch stable/kubernetes-dashboard(更新完之后还是不能下载)
Error: no cached repo found. (try 'helm repo update'). open /root/.helm/repository/cache/stable-index.yaml: no such file or directory
[root@k8s-master01 dashboard]# ls
[root@k8s-master01 dashboard]# helm repo add stable http://mirror.azure.cn/kubernetes/charts(执行这条命令)
"stable" has been added to your repositories
[root@k8s-master01 dashboard]# helm fetch stable/kubernetes-dashboard(这回就下载成功了)
[root@k8s-master01 dashboard]# ls
kubernetes-dashboard-1.11.1.tgz
[root@k8s-master01 dashboard]# tar -zxvf kubernetes-dashboard-1.11.1.tgz
[root@k8s-master01 dashboard]# ls
kubernetes-dashboard kubernetes-dashboard-1.11.1.tgz
[root@k8s-master01 dashboard]# cd kubernetes-dashboard/
[root@k8s-master01 kubernetes-dashboard]# ls
Chart.yaml README.md templates values.yaml
[root@k8s-master01 kubernetes-dashboard]#
以上是不成功方案,解放方案如下:
[root@k8s-master01 dashboard]# helm repo add k8s-dashboard https://kubernetes.github.io/dashboard
[root@k8s-master01 dashboard]# helm install k8s-dashboard/kubernetes-dashboard --version 2.6.0 -n k8s-dashboard --namespace kube-system
[root@k8s-master01 dashboard]# helm list
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
k8s-dashboard 1 Fri Jul 22 20:51:10 2022 DEPLOYED kubernetes-dashboard-2.6.0 2.0.3 kube-system
[root@k8s-master01 dashboard]#
[root@k8s-master01 dashboard]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
k8s-dashboard-kubernetes-dashboard-56d8995f77-64rrp 1/1 Running 0 4m5s
[root@k8s-master01 dashboard]#
[root@k8s-master01 dashboard]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
k8s-dashboard-kubernetes-dashboard ClusterIP 10.111.83.151 <none> 443/TCP 7m15s
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 19d
tiller-deploy ClusterIP 10.100.223.87 <none> 44134/TCP 45h
[root@k8s-master01 dashboard]#
[root@k8s-master01 dashboard]# kubectl edit svc k8s-dashboard-kubernetes-dashboard -n kube-system(修改一下type类型,方便我们访问)
service/k8s-dashboard-kubernetes-dashboard edited
[root@k8s-master01 dashboard]#
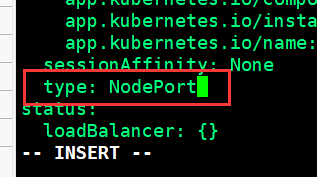
[root@k8s-master01 dashboard]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
k8s-dashboard-kubernetes-dashboard NodePort 10.111.83.151 <none> 443:31996/TCP 10m
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 19d
tiller-deploy ClusterIP 10.100.223.87 <none> 44134/TCP 45h
[root@k8s-master01 dashboard]#
我们输入ip地址:端口号访问一下:
(谷歌无法访问,使用火狐或者Edge浏览器访问!)
我们选择第一种访问:
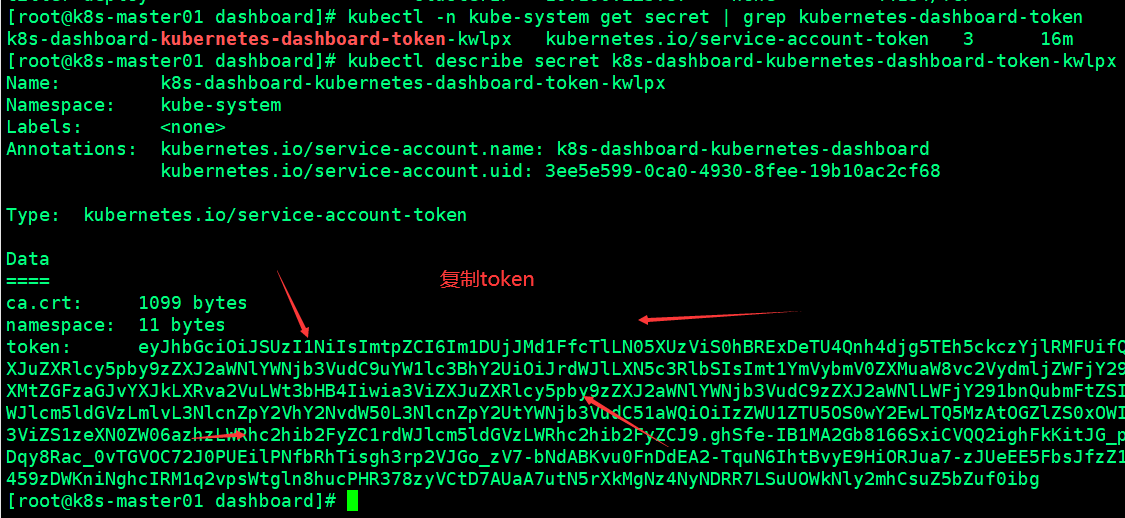
[root@k8s-master01 dashboard]# kubectl -n kube-system get secret | grep kubernetes-dashboard-token
k8s-dashboard-kubernetes-dashboard-token-kwlpx kubernetes.io/service-account-token 3 16m
[root@k8s-master01 dashboard]# kubectl describe secret k8s-dashboard-kubernetes-dashboard-token-kwlpx -n kube-system
我们进入后可以随意操作
使用Helm部署metrics-server
(由于 metrics-server已经包含在普罗米修斯里,所以这里我们不再部署了,直接关注普罗米修斯!)
从 Heapster 的 github 中可以看到已经,heapster 已经DEPRECATED。这里是 heapster的deprecation timeline。 可以看出 heapster 从 Kubernetes 1.12 开始将从 Kubernetes 各种安装脚本中移除。Kubernetes 推荐使用 metrics-server。我们这里也使用helm来部署metrics-server。
metrics-server.yaml:
args
helm install stable/metrics-server \
-n metrics-server \
--namespace kube-system \
-f metrics-server.yaml
使用下面的命令可以获取到关于集群节点基本的指标信息:
kubectl top node
kubectl top pod --all-namespaces
部署Prometheus
相关地址信息
Prometheus github 地址:https://github.com/coreos/kube-prometheus
组件说明
-
MetricServer:是kubernetes集群资源使用情况的聚合器,收集数据给kubernetes集群内使用,如
kubectl,hpa,scheduler等。
-
PrometheusOperator:是一个系统监测和警报工具箱,用来存储监控数据。
-
NodeExporter:用于各node的关键度量指标状态数据。
-
KubeStateMetrics:收集kubernetes集群内资源对象数
据,制定告警规则。
-
Prometheus:采用pull方式收集apiserver,scheduler,controller-manager,kubelet组件数
据,通过http协议传输。
-
Grafana:是可视化数据统计和监控平台。
构建记录
git clone https://github.com/coreos/kube-prometheus.git
cd /root/kube-prometheus/manifests
[root@k8s-master01 ~]# cd /usr/local/install-k8s/plugin/
[root@k8s-master01 plugin]# mkdir prometheus
[root@k8s-master01 plugin]# cd prometheus/
[root@k8s-master01 prometheus]# git clone https://github.com/coreos/kube-prometheus.git
[root@k8s-master01 prometheus]# ls
kube-prometheus
[root@k8s-master01 prometheus]# cd kube-prometheus/manifests/
[root@k8s-master01 manifests]#
修改 grafana-service.yaml 文件,使用 nodepode 方式访问 grafana:
vim grafana-service.yaml
apiVersion
修改 prometheus-service.yaml,改为 nodepode
vim prometheus-service.yaml
apiVersion
修改 alertmanager-service.yaml,改为 nodepode
vim alertmanager-service.yaml
apiVersion
[root@k8s-master01 manifests]# vim grafana-service.yaml
[root@k8s-master01 manifests]# vim prometheus-service.yaml
[root@k8s-master01 manifests]# vim alertmanager-service.yaml
[root@k8s-master01 prometheus]# pwd(把文件传输到此目录下)
/usr/local/install-k8s/plugin/prometheus
[root@k8s-master01 prometheus]# ls
kube-prometheus load-images.sh prometheus.tar.gz
kube-prometheus.git.tar.gz prometheus(解压出来的)
[root@k8s-master01 prometheus]# mv prometheus load-images.sh /root/(移到root目录下)
[root@k8s-master01 prometheus]# cd
[root@k8s-master01 ~]# chmod a+x load-images.sh
[root@k8s-master01 ~]# ./load-images.sh
把这两个文件传输到其他node节点上
[root@k8s-master01 ~]# scp -r prometheus/ load-images.sh root@k8s-node01:/root/
[root@k8s-master01 ~]# scp -r prometheus/ load-images.sh root@k8s-node02:/root/
[root@k8s-master01 manifests]# kubectl apply -f ../manifests/
执行完之后我们会发现报错,多执行几遍
[root@k8s-master01 manifests]# kubectl apply -f ../manifests/setup/
之后会发现一直报这个错误:
error: unable to recognize "../manifests/prometheus-prometheus.yaml": no matches for kind "Prometheus" in version "v1"
[root@k8s-master01 manifests]#
Horizontal Pod Autoscaling
Horizontal Pod Autoscaling 可以根据 CPU 利用率自动伸缩一个 Replication Controller、Deployment 或者Replica Set 中的 Pod 数量
kubectl run php-apache --image=gcr.io/google_containers/hpa-example --requests=cpu=200m --expose
--port=80
创建 HPA 控制器 -
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
增加负载,查看负载节点数目
$ kubectl run -i --tty load-generator --image=busybox /bin/sh
$ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
资源限制 - Pod
Kubernetes 对资源的限制实际上是通过 cgroup 来控制的,cgroup 是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup
默认情况下,Pod 运行没有 CPU 和内存的限额。 这意味着系统中的任何 Pod 将能够像执行该 Pod 所在的节点一样,消耗足够多的 CPU 和内存 。一般会针对某些应用的 pod 资源进行资源限制,这个资源限制是通过resources 的 requests 和 limits 来实现
spec
requests 要分分配的资源,limits 为最高请求的资源值。可以简单理解为初始值和最大值
资源限制 - 名称空间
计算资源配额
apiVersion
配置对象数量配额限制
apiVersion
配置 CPU 和 内存 LimitRange
apiVersion
-
default 即 limit 的值
-
defaultRequest 即 request 的值
访问 prometheus
prometheus 对应的 nodeport 端口为 30200,访问 http://MasterIP:30200
通过访问 http://MasterIP:30200/target 可以看到 prometheus 已经成功连接上了 k8s 的 apiserver
查看 service-discovery
Prometheus 自己的指标
prometheus 的 WEB 界面上提供了基本的查询 K8S 集群中每个 POD 的 CPU 使用情况,查询条件如下:
sum by (pod_name)( rate(container_cpu_usage_seconds_total
上述的查询有出现数据,说明 node-exporter 往 prometheus 中写入数据正常,接下来我们就可以部署grafana 组件,实现更友好的 webui 展示数据了
访问 grafana
查看 grafana 服务暴露的端口号:
kubectl get service -n monitoring | grep grafana
如上可以看到 grafana 的端口号是 30100,浏览器访问 http://MasterIP:30100 用户名密码默认 admin/admin
修改密码并登陆
添加数据源 grafana 默认已经添加了 Prometheus 数据源,grafana 支持多种时序数据源,每种数据源都有各自的查询编辑器
Prometheus 数据源的相关参数:
目前官方支持了如下几种数据源:
ELK是elasticsearch、logstatsh、kibana三种软件集成的日志搜集展示的框架,其中logstatsh是用于收集日志的软件,通常都会把它单放在其他服务器中,而elasticsearch与kibana可以放在一起,也可以分开放,elastivsearch是用来接受logstatsh传过来的日志文件,然后进行处理,处理完毕之后交给kibana进行一个网页的展示。
EFK是elasticsearch、logstatsh、kibana、zookeeper、kafka五种软件的集成,zookeeper、kafka使用来创建topic收集日志的仓库,当zookeeper、kafka配置好之后可以用创建好的topic用来收集想要的日志,zookeeper与kafka占用资源少、启动快、用起来方便、所以现在绝大多数公司都在使用EFK
我们这里用ELK,但是L我们用fluentd filebeat代替!
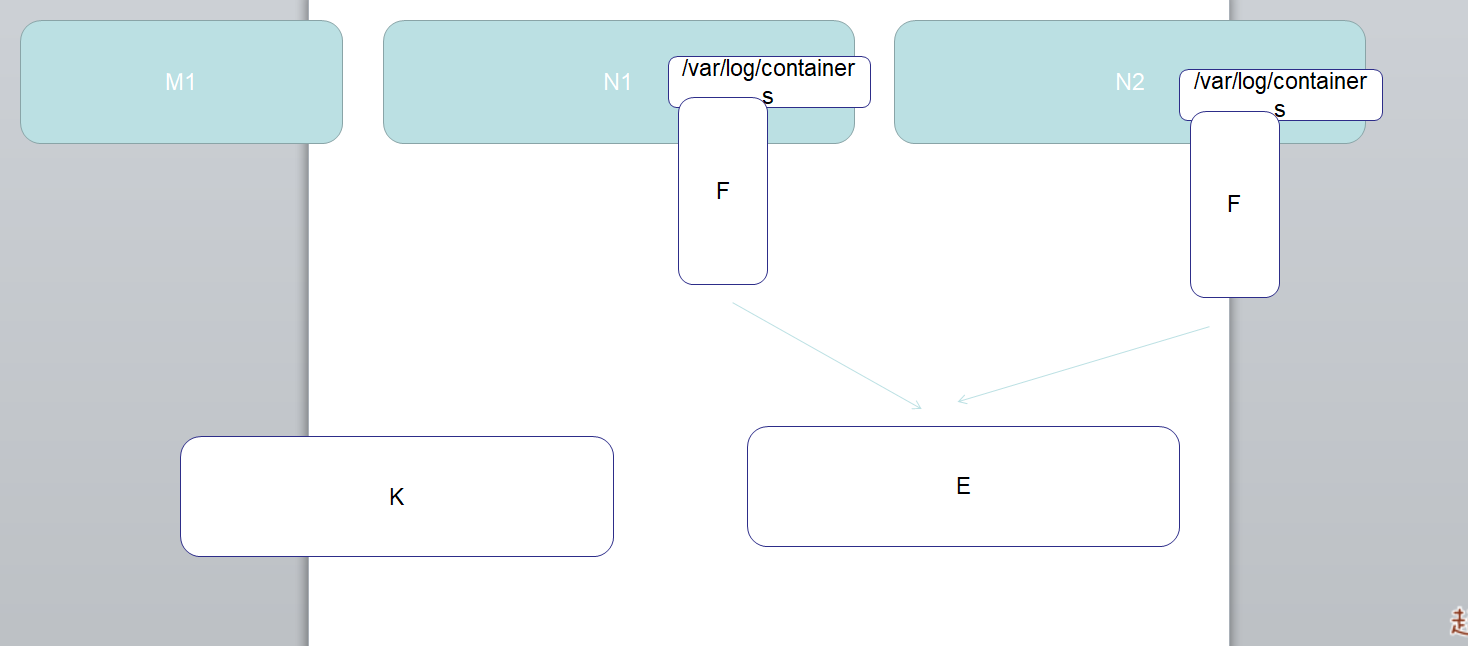
添加 Google incubator 仓库
helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
# 添加仓库
helm repo add incubator https://mirror.azure.cn/kubernetes/charts-incubator
部署 Elasticsearch
kubectl create namespace efk
helm fetch incubator/elasticsearch
helm install --name els1 --namespace=efk -f values.yaml
kubectl run cirror-$RANDOM --rm -it --image=cirros -- /bin/sh
curl Elasticsearch:Port/_cat/nodes
[root@k8s-master01 efk]# kubectl create namespace efk
namespace/efk created
[root@k8s-master01 efk]# rz -E
rz waiting to receive.
下载不了去这里手动下载,之后上传!
Index of /kubernetes/charts-incubator/ (azure.cn)
[root@k8s-master01 efk]# ls
elasticsearch-1.10.2.tgz
[root@k8s-master01 efk]# tar -zxvf elasticsearch-1.10.2.tgz
root@k8s-master01 efk]# cd elasticsearch/
[root@k8s-master01 elasticsearch]# ls
Chart.yaml ci README.md templates values.yaml
[root@k8s-master01 elasticsearch]# vim values.yaml (修改values.yaml文件)
[root@k8s-master01 elasticsearch]#
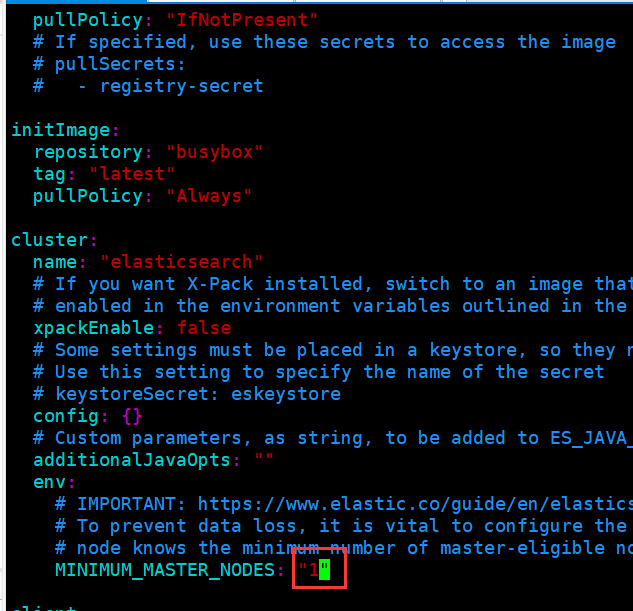
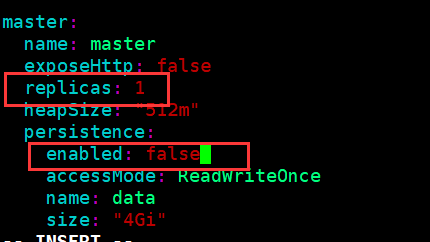
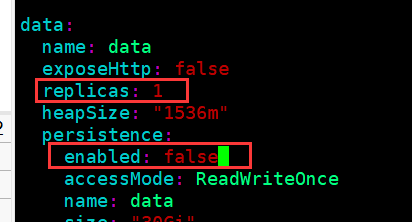
部署 Fluentd
helm fetch stable/fluentd-elasticsearch
vim values.yaml
# 更改其中 Elasticsearch 访问地址
helm install --name flu1 --namespace=efk -f values.yaml stable/fluentd-elasticsearch
部署 kibana
helm fetch stable/kibana --version 0.14.8
helm install --name kib1 --namespace=efk -f values.yaml stable/kibana --version 0.14.8



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· Qt个人项目总结 —— MySQL数据库查询与断言