
PV-PVS
PersistentVolume(PV)
是由管理员设置的存储,它是群集的一部分。就像节点是集群中的资源一样,PV 也是集群中的资源。 PV 是Volume 之类的卷插件,但具有独立于使用 PV 的 Pod 的生命周期。此 API 对象包含存储实现的细节,即 NFS、iSCSI 或特定于云供应商的存储系统
PersistentVolumeClaim (PVC)
是用户存储的请求。它与 Pod 相似。Pod 消耗节点资源,PVC 消耗 PV 资源。Pod 可以请求特定级别的资源(CPU 和内存)。声明可以请求特定的大小和访问模式(例如,可以以读/写一次或 只读多次模式挂载)
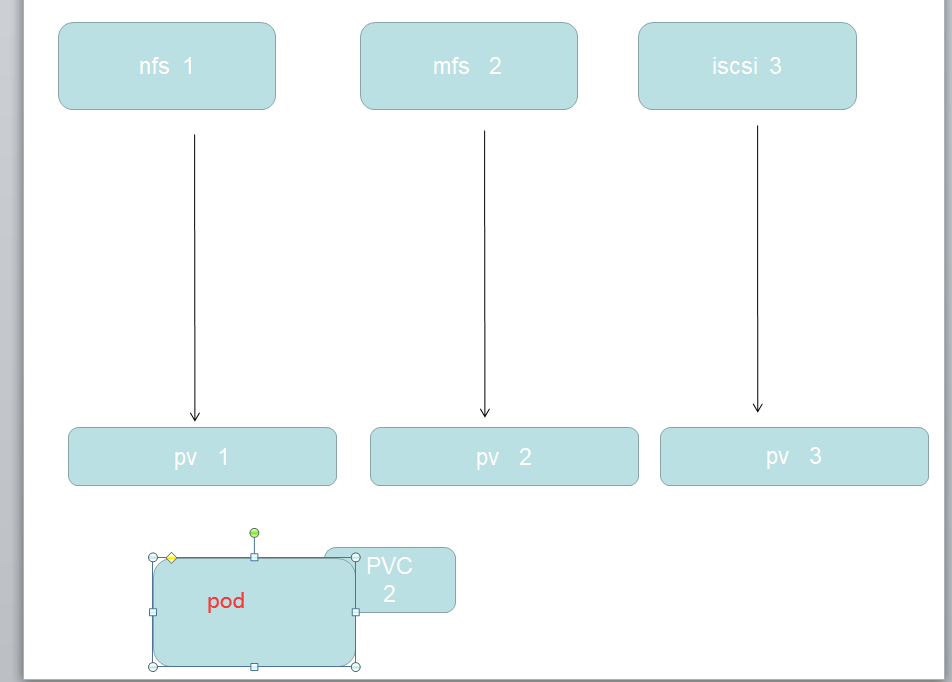
静态 pv
集群管理员创建一些 PV。它们带有可供群集用户使用的实际存储的细节。它们存在于 Kubernetes API 中,可用于消费
动态(了解)
当管理员创建的静态 PV 都不匹配用户的 PersistentVolumeClaim 时,集群可能会尝试动态地为 PVC 创建卷。此配置基于 StorageClasses :PVC 必须请求 [存储类],并且管理员必须创建并配置该类才能进行动态创建。声明该类为 "" 可以有效地禁用其动态配置
要启用基于存储级别的动态存储配置,集群管理员需要启用 API server 上的 DefaultStorageClass [准入控制器]。例如,通过确保 DefaultStorageClass 位于 API server 组件的 --admission-control 标志,使用逗号分隔的有序值列表中,可以完成此操作
绑定
master 中的控制环路监视新的 PVC,寻找匹配的 PV(如果可能),并将它们绑定在一起。如果为新的 PVC 动态调配 PV,则该环路将始终将该 PV 绑定到 PVC。否则,用户总会得到他们所请求的存储,但是容量可能超出要求的数量。一旦 PV 和 PVC 绑定后, PersistentVolumeClaim 绑定是排他性的,不管它们是如何绑定的。 PVC 跟PV 绑定是一对一的映射
持久化卷声明的保护
PVC 保护的目的是确保由 pod 正在使用的 PVC 不会从系统中移除,因为如果被移除的话可能会导致数据丢失
当启用PVC 保护 alpha 功能时,如果用户删除了一个 pod 正在使用的 PVC,则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 pod 使用
注意:当pod状态为Pending并且pod已经分配给节点或pod为Running状态时,pvc处于活动状态
持久化卷类型
PersistentVolume 类型以插件形式实现。Kubernetes 目前支持以下插件类型:
-
GCEPersistentDisk AWSElasticBlockStore AzureFile AzureDisk FC (Fibre Channel)
-
FlexVolume Flocker NFS iSCSI RBD (Ceph Block Device) CephFS
-
Cinder (OpenStack block storage) Glusterfs VsphereVolume Quobyte Volumes
-
HostPath VMware Photon Portworx Volumes ScaleIO Volumes StorageOS
持久卷演示代码
apiVersion
PV 访问模式
PersistentVolume 可以以资源提供者支持的任何方式挂载到主机上。如下表所示,供应商具有不同的功能,每个PV 的访问模式都将被设置为该卷支持的特定模式。例如,NFS 可以支持多个读/写客户端,但特定的 NFS PV 可能以只读方式导出到服务器上。每个 PV 都有一套自己的用来描述特定功能的访问模式
-
ReadWriteOnce——该卷可以被单个节点以读/写模式挂载
-
ReadOnlyMany——该卷可以被多个节点以只读模式挂载
-
ReadWriteMany——该卷可以被多个节点以读/写模式挂载
在命令行中,访问模式缩写为:
-
RWO - ReadWriteOnce
-
ROX - ReadOnlyMany
-
RWX - ReadWriteMany
一个卷一次只能使用一种访问模式挂载,即使它支持很多访问模式。例如,GCEPersistentDisk可以由单个节点作为ReadwriteOnce模式挂载,或由多个节点以ReadonlyMany模式挂载,但不能同时挂载
| Volume 插件 | ReadWriteOnce | ReadWriteOnce | ReadWriteMany |
|---|---|---|---|
| AWSElasticBlockStoreAWSElasticBlockStore | ✓ | - | - |
| AzureFile | ✓ | ✓ | ✓ |
| AzureDisk | ✓ | ✓ | - |
| CephFS | ✓ | ✓ | ✓ |
| Cinder | ✓ | - | - |
| FC | ✓ | ✓ | - |
| FlexVolume | ✓ | ✓ | - |
| Flocker | ✓ | - | - |
| GCEPersistentDisk | ✓ | ✓ | - |
| Glusterfs | ✓ | ✓ | ✓ |
| HostPath | ✓ | - | - |
| iSCSI | ✓ | ✓ | - |
| PhotonPersistentDisk | ✓ | - | - |
| Quobyte | ✓ | ✓ | ✓ |
| NFS | ✓ | ✓ | ✓ |
| RBD | ✓ | ✓ | - |
| VsphereVolume | ✓ | - | -(当pod并列时有效) |
| PortworxVolume | ✓ | - | ✓ |
| ScaleIO | ✓ | ✓ | - |
| StorageOS | ✓ | - | - |
回收策略
-
Retain(保留)——手动回收
-
Recycle(回收)——基本擦除( rm -rf /thevolume/* )
-
Delete(删除)——关联的存储资产(例如 AWS EBS、GCE PD、Azure Disk 和 OpenStack Cinder 卷)
将被删除
当前,只有 NFS 和 HostPath 支持回收策略。AWS EBS、GCE PD、Azure Disk 和 Cinder 卷支持删除策略
状态
卷可以处于以下的某种状态:
-
Available(可用)——一块空闲资源还没有被任何声明绑定
-
Bound(已绑定)——卷已经被声明绑定
-
Released(已释放)——声明被删除,但是资源还未被集群重新声明
-
Failed(失败)——该卷的自动回收失败
命令行会显示绑定到 PV 的 PVC 的名称
持久化演示说明 - NFS
安装 NFS 服务器
yum install -y nfs-common nfs-utils rpcbind(这个命令所有的节点都要执行!)
mkdir /nfsdata
chmod 666 /nfsdata
chown nfsnobody /nfsdata
cat /etc/exports
/nfsdata *(rw,no_root_squash,no_all_squash,sync)
systemctl start rpcbind
systemctl start nfs
安装到master主机上
[root@k8s-master01 ~]# yum install -y nfs-common nfs-utils rpcbind
[root@k8s-master01 ~]# mkdir /nfs
[root@k8s-master01 ~]# chmod 777 /nfs/
[root@k8s-master01 ~]# chown nfsnobody /nfs/
[root@k8s-master01 ~]# vim /etc/exports
[root@k8s-master01 ~]# cat /etc/exports
/nfs *(rw,no_root_squash,no_all_squash,sync)
[root@k8s-master01 ~]# systemctl start nfs
[root@k8s-master01 ~]#
部署 PV
apiVersion
[root@k8s-master01 ~]# mkdir pv
[root@k8s-master01 ~]# cd pv/
[root@k8s-master01 pv]# ls
[root@k8s-master01 pv]# vim pv.yaml
[root@k8s-master01 pv]# kubectl create -f pv.yaml
persistentvolume/nfspv1 created
[root@k8s-master01 pv]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfspv1 10Gi RWO Retain Available nfs 11s
[root@k8s-master01 pv]#
我们多创建几个pv
[root@k8s-master01 ~]# vim /etc/exports
[root@k8s-master01 ~]# cat /etc/exports
/nfs *(rw,no_root_squash,no_all_squash,sync)
/nfs1 *(rw,no_root_squash,no_all_squash,sync)
/nfs2 *(rw,no_root_squash,no_all_squash,sync)
/nfs3 *(rw,no_root_squash,no_all_squash,sync)
[root@k8s-master01 ~]# cd /
[root@k8s-master01 /]# ls
bin boot data dev etc home lib lib64 lost+found media mnt nfs opt proc root run sbin srv sys tmp usr var
[root@k8s-master01 /]# mkdir nfs{1..3}
[root@k8s-master01 /]# ls
bin boot data dev etc home lib lib64 lost+found media mnt nfs nfs1 nfs2 nfs3 opt proc root run sbin srv sys tmp usr var
[root@k8s-master01 /]# chmod 777 nfs1/ nfs2/ nfs3/
[root@k8s-master01 /]# chown nfsnobody nfs1/ nfs2/ nfs3/
[root@k8s-master01 /]# systemctl restart rpcbind
[root@k8s-master01 /]# systemctl restart nfs
[root@k8s-master01 /]#
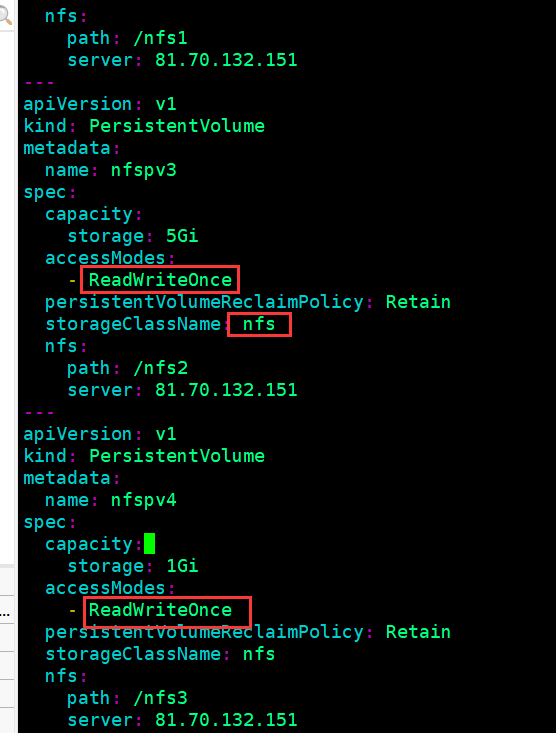
[root@k8s-master01 ~]# vim pv/pv.yaml
[root@k8s-master01 ~]# cat pv/pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv2
spec:
capacity:
storage: 5Gi
accessModes:
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfs1
server: 81.70.132.151
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv3
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: slow
nfs:
path: /nfs2
server: 81.70.132.151
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv4
spec:
capacity:
storage: 1Gi
accessModes:
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: /nfs3
server: 81.70.132.151
[root@k8s-master01 pv]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfspv1 10Gi RWO Retain Available nfs 22m
nfspv2 5Gi ROX Retain Available nfs 2m35s
nfspv3 5Gi RWX Retain Available slow 11s
nfspv4 1Gi ROX Retain Available nfs 2m35s
[root@k8s-master01 pv]#
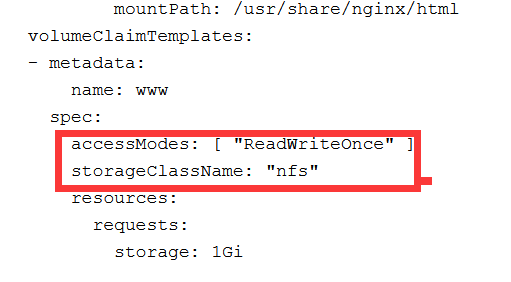
创建服务并使用 PVC
apiVersion
[root@k8s-master01 pv]# kubectl apply -f pod.yaml
service/nginx unchanged
statefulset.apps/web configured
[root@k8s-master01 pv]# kubectl get pod
NAME READY STATUS RESTARTS AGE
test-pd 1/1 Running 1 (36h ago) 36h
web-0 1/1 Running 0 56s
web-1 0/1 Pending 0 55s
[root@k8s-master01 pv]# kubectl describe pod web-1

[root@k8s-master01 pv]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfspv1 10Gi RWO Retain Bound default/www-web-0 nfs 126m
nfspv2 5Gi ROX Retain Available nfs 106m
nfspv3 5Gi RWX Retain Available slow 104m
nfspv4 1Gi ROX Retain Available nfs 106m
[root@k8s-master01 pv]#
我们看一下需求,这两个都要满足,所以我们发现只有nfspv1可以被满足,其他的不行
[root@k8s-master01 pv]# vim pv.yaml
[root@k8s-master01 pv]# kubectl create -f pv.yaml
[root@k8s-master01 pv]# kubectl get pv(我们发现,已经全部绑定了!)
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfspv1 10Gi RWO Retain Bound default/www-web-0 nfs 137m
nfspv2 5Gi ROX Retain Available nfs 117m
nfspv3 5Gi RWO Retain Bound default/www-web-1 nfs 3m32s
nfspv4 1Gi RWO Retain Bound default/www-web-2 nfs 50s
[root@k8s-master01 pv]#
[root@k8s-master01 pv]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound nfspv1 10Gi RWO nfs 112m
www-web-1 Bound nfspv3 5Gi RWO nfs 19m
www-web-2 Bound nfspv4 1Gi RWO nfs 5m20s
[root@k8s-master01 pv]#
[root@k8s-master01 pv]# kubectl describe pv nfspv1
Name: nfspv1
Labels: <none>
Annotations: pv.kubernetes.io/bound-by-controller: yes
Finalizers: [kubernetes.io/pv-protection]
StorageClass: nfs
Status: Bound
Claim: default/www-web-0
Reclaim Policy: Retain
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 10Gi
Node Affinity: <none>
Message:
Source:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: 81.70.132.151
Path: /nfs
ReadOnly: false
Events: <none>
[root@k8s-master01 pv]# cd /nfs
[root@k8s-master01 nfs]# ls
[root@k8s-master01 nfs]# vim index.html
[root@k8s-master01 nfs]# cat index.html
aaaaaaaaaa
[root@k8s-master01 nfs]# chmod 777 index.html
[root@k8s-master01 nfs]# cd -
/root/pv
[root@k8s-master01 pv]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 1 (36h ago) 36h 10.244.2.71 k8s-node02 <none> <none>
web-0 1/1 Running 0 21m 10.244.1.70 k8s-node01 <none> <none>
web-1 1/1 Running 0 21m 10.244.2.72 k8s-node02 <none> <none>
web-2 1/1 Running 0 7m45s 10.244.1.71 k8s-node01 <none> <none>
[root@k8s-master01 pv]# curl 10.244.1.70
aaaaaaaaaa
[root@k8s-master01 pv]#
同样,我们去查看下web-1
[root@k8s-master01 pv]# kubectl describe pv nfspv3
Name: nfspv3
Labels: <none>
Annotations: pv.kubernetes.io/bound-by-controller: yes
Finalizers: [kubernetes.io/pv-protection]
StorageClass: nfs
Status: Bound
Claim: default/www-web-1
Reclaim Policy: Retain
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 5Gi
Node Affinity: <none>
Message:
Source:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: 81.70.132.151
Path: /nfs2
ReadOnly: false
Events: <none>
[root@k8s-master01 pv]# cd /nfs2
[root@k8s-master01 nfs2]# echo bbbbbbb > index.html
[root@k8s-master01 nfs2]# cd -
/root/pv
[root@k8s-master01 pv]# curl 10.244.2.72
bbbbbbb
[root@k8s-master01 pv]#
同理,web-2也是如此
[root@k8s-master01 pv]# cd /nfs3/
[root@k8s-master01 nfs3]# echo cccccccc > index.html
[root@k8s-master01 nfs3]# cd -
/root/pv
[root@k8s-master01 pv]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 1 (36h ago) 36h 10.244.2.71 k8s-node02 <none> <none>
web-0 1/1 Running 0 32m 10.244.1.70 k8s-node01 <none> <none>
web-1 1/1 Running 0 32m 10.244.2.72 k8s-node02 <none> <none>
web-2 1/1 Running 0 18m 10.244.1.71 k8s-node01 <none> <none>
[root@k8s-master01 pv]# curl 10.244.1.71
cccccccc
我们删除一个pod,再次查看,发现pod又重新启动且地址改变了,但是,数据是不会消失的,这也是StatefulSet的特性!
[root@k8s-master01 pv]# kubectl delete pod web-0
pod "web-0" deleted
[root@k8s-master01 pv]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-pd 1/1 Running 1 (36h ago) 36h 10.244.2.71 k8s-node02 <none> <none>
web-0 1/1 Running 0 26s 10.244.1.72 k8s-node01 <none> <none>
web-1 1/1 Running 0 35m 10.244.2.72 k8s-node02 <none> <none>
web-2 1/1 Running 0 20m 10.244.1.71 k8s-node01 <none> <none>
[root@k8s-master01 pv]# curl 10.244.1.72
aaaaaaaaaa
[root@k8s-master01 pv]#
-
匹配 Pod name ( 网络标识 ) 的模式为:名称(序号),比如上面的示例:web-0,web-1,
web-2
-
StatefulSet 为每个 Pod 副本创建了一个 DNS 域名,这个域名的格式为: $(podname).(headless servername),也就意味着服务间是通过Pod域名来通信而非 Pod IP,因为当Pod所在Node发生故障时, Pod 会被飘移到其它 Node 上,Pod IP 会发生变化,但是 Pod 域名不会有变化
[root@k8s-master01 pv]# kubectl exec test-pd -it -- /bin/bash
root@test-pd:/# ping web-0.nginx
bash: ping: command not found
root@test-pd:/#
(我这里是容器的问题,正常来说都是可以ping通的)
-
StatefulSet 使用 Headless 服务来控制 Pod 的域名,这个域名的 FQDN 为:$(servicename).$(namespace).svc.cluster.local,其中,“cluster.local” 指的是集群的域名
[root@k8s-master01 pv]# kubectl get pod -o wide -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-6d8c4cb4d-dqwn8 1/1 Running 11 (37h ago) 13d 10.244.0.24 k8s-master01 <none> <none>
coredns-6d8c4cb4d-lx9c6 1/1 Running 11 (37h ago) 13d 10.244.0.25 k8s-master01 <none> <none>
etcd-k8s-master01 1/1 Running 12 (37h ago) 13d 172.21.0.6 k8s-master01 <none> <none>
kube-apiserver-k8s-master01 1/1 Running 11 (37h ago) 13d 172.21.0.6 k8s-master01 <none> <none>
kube-controller-manager-k8s-master01 1/1 Running 11 (37h ago) 13d 172.21.0.6 k8s-master01 <none> <none>
kube-flannel-ds-78zh6 1/1 Running 10 (37h ago) 13d 172.21.0.9 k8s-node02 <none> <none>
kube-flannel-ds-gcfpm 1/1 Running 11 (3h17m ago) 13d 172.21.0.6 k8s-master01 <none> <none>
kube-flannel-ds-gwv5h 1/1 Running 10 (37h ago) 13d 172.21.0.13 k8s-node01 <none> <none>
kube-proxy-ht4bl 1/1 Running 10 (37h ago) 13d 172.21.0.13 k8s-node01 <none> <none>
kube-proxy-scjvz 1/1 Running 11 (37h ago) 13d 172.21.0.6 k8s-master01 <none> <none>
kube-proxy-t68wn 1/1 Running 10 (37h ago) 13d 172.21.0.9 k8s-node02 <none> <none>
kube-scheduler-k8s-master01 1/1 Running 11 (37h ago) 13d 172.21.0.6 k8s-master01 <none> <none>
[root@k8s-master01 pv]# dig -t A nginx.default.svc.cluster.local. @10.244.0.24
; <<>> DiG 9.11.4-P2-RedHat-9.11.4-26.P2.el7_9.9 <<>> -t A nginx.default.svc.cluster.local. @10.244.0.24
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 7200
;; flags: qr aa rd; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;nginx.default.svc.cluster.local. IN A
;; ANSWER SECTION:
nginx.default.svc.cluster.local. 18 IN A 10.244.1.72
nginx.default.svc.cluster.local. 18 IN A 10.244.2.72
nginx.default.svc.cluster.local. 18 IN A 10.244.1.71
;; Query time: 0 msec
;; SERVER: 10.244.0.24#53(10.244.0.24)
;; WHEN: Sat Jul 16 12:40:58 CST 2022
;; MSG SIZE rcvd: 201
[root@k8s-master01 pv]#
-
根据 volumeClaimTemplates,为每个 Pod 创建一个 pvc,pvc 的命名规则匹配模式:
(volumeClaimTemplates.name)-(pod_name),比如上面的 volumeMounts.name=www, Podname=web-[0-2],因此创建出来的 PVC 是 www-web-0、www-web-1、www-web-2
-
删除 Pod 不会删除其 pvc,手动删除 pvc 将自动释放 pv
Statefulset的启停顺序:
-
有序部署:部署StatefulSet时,如果有多个Pod副本,它们会被顺序地创建(从0到N-1)并且,在下一个
Pod运行之前所有之前的Pod必须都是Running和Ready状态。
-
有序删除:当Pod被删除时,它们被终止的顺序是从N-1到0。
我们新开一个终端,执行删除命令
[root@k8s-master01 ~]# kubectl delete statefulset --all
statefulset.apps "web" deleted
[root@k8s-master01 ~]#
[root@k8s-master01 pv]# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
test-pd 1/1 Running 1 (37h ago) 37h
web-0 1/1 Running 0 46s
web-1 1/1 Running 0 29s
web-2 1/1 Running 0 12s
web-1 1/1 Terminating 0 33s
web-0 1/1 Terminating 0 50s
web-2 1/1 Terminating 0 16s
web-1 0/1 Terminating 0 34s
web-0 0/1 Terminating 0 51s
web-2 0/1 Terminating 0 17s
web-0 0/1 Terminating 0 51s
web-0 0/1 Terminating 0 51s
web-1 0/1 Terminating 0 34s
web-1 0/1 Terminating 0 34s
web-2 0/1 Terminating 0 17s
web-2 0/1 Terminating 0 17s
这里好像也不是有序删除吧……可能是我不会看。不过有序删除肯定是没有问题的!
-
有序扩展:当对Pod执行扩展操作时,与部署一样,它前面的Pod必须都处于Running和Ready状态。
-
稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现。
-
稳定的网络标识符,即 Pod 重新调度后其 PodName 和 HostName 不变。(并不是ip地址)
-
有序部署,有序扩展,基于 init containers 来实现。
-
有序收缩。
删除集群以及数据
^C[root@k8s-master01 pv]# kubectl delete -f pod.yaml (删除yaml文件,pod也会随之删除)
service "nginx" deleted
Error from server (NotFound): error when deleting "pod.yaml": statefulsets.apps "web" not found
[root@k8s-master01 pv]# kubectl get pod(pod没有了)
NAME READY STATUS RESTARTS AGE
test-pd 1/1 Running 1 (37h ago) 37h
[root@k8s-master01 pv]# kubectl get statefulset(statefulset服务也没有了)
No resources found in default namespace.
[root@k8s-master01 pv]# kubectl get svc(svc也没有了)
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
[root@k8s-master01 pv]# kubectl get pvc(但是这些pvc还存在)
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound nfspv1 10Gi RWO nfs 169m
www-web-1 Bound nfspv3 5Gi RWO nfs 76m
www-web-2 Bound nfspv4 1Gi RWO nfs 62m
[root@k8s-master01 pv]#
[root@k8s-master01 pv]# kubectl delete pvc --all(PVC需要手动删除)
persistentvolumeclaim "www-web-0" deleted
persistentvolumeclaim "www-web-1" deleted
persistentvolumeclaim "www-web-2" deleted
[root@k8s-master01 pv]# kubectl get pv(资源虽然被回收了,但是还是需要我们去手动释放资源)
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfspv1 10Gi RWO Retain Released default/www-web-0 nfs 3h19m
nfspv2 5Gi ROX Retain Available nfs 3h
nfspv3 5Gi RWO Retain Released default/www-web-1 nfs 66m
nfspv4 1Gi RWO Retain Released default/www-web-2 nfs 63m
[root@k8s-master01 pv]#
[root@k8s-master01 pv]# rm -rf /nfs
[root@k8s-master01 pv]# rm -rf /nfs1/*
[root@k8s-master01 pv]# rm -rf /nfs2/*
[root@k8s-master01 pv]# kubectl get pv(虽然文件都删除了,但是仍然存在。nfs不会看这些文件 ,它只知道在它的描述数据里,依然还有连接)
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfspv1 10Gi RWO Retain Released default/www-web-0 nfs 3h24m
nfspv2 5Gi ROX Retain Available nfs 3h4m
nfspv3 5Gi RWO Retain Released default/www-web-1 nfs 70m
nfspv4 1Gi RWO Retain Released default/www-web-2 nfs 67m
[root@k8s-master01 pv]#
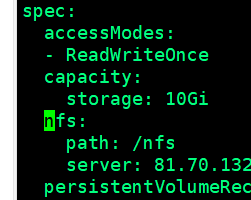
[root@k8s-master01 pv]# kubectl get pv nfspv1 -o yaml
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/bound-by-controller: "yes"
creationTimestamp: "2022-07-16T01:43:51Z"
finalizers:
- kubernetes.io/pv-protection
name: nfspv1
resourceVersion: "93894"
uid: f3cad667-24b0-4fae-bc04-795d6a965824
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: www-web-0
namespace: default
resourceVersion: "78708"
uid: 1a95c09c-be4f-4f63-b3dc-a9ee33f84bec
nfs:
path: /nfs
server: 81.70.132.151
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
volumeMode: Filesystem
status:
phase: Released
[root@k8s-master01 pv]#
(只有当 pv 的 Spec.ClaimRef 的值为空的时候,才说明当前 pv 未被使用)
[root@k8s-master01 pv]# kubectl edit pv nfspv1(我们进入删除ClaimRef的内容)
persistentvolume/nfspv1 edited
[root@k8s-master01 pv]# kubectl get pv(这时发现nfspv1没有了!)
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfspv1 10Gi RWO Retain Available nfs 3h30m
nfspv2 5Gi ROX Retain Available nfs 3h11m
nfspv3 5Gi RWO Retain Released default/www-web-1 nfs 77m
nfspv4 1Gi RWO Retain Released default/www-web-2 nfs 74m
[root@k8s-master01 pv]#
[root@k8s-master01 pv]# kubectl get pv(我们把所有的资源回收一下)
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfspv1 10Gi RWO Retain Available nfs 3h33m
nfspv2 5Gi ROX Retain Available nfs 3h14m
nfspv3 5Gi RWO Retain Available nfs 79m
nfspv4 1Gi RWO Retain Available nfs 77m
[root@k8s-master01 pv]#
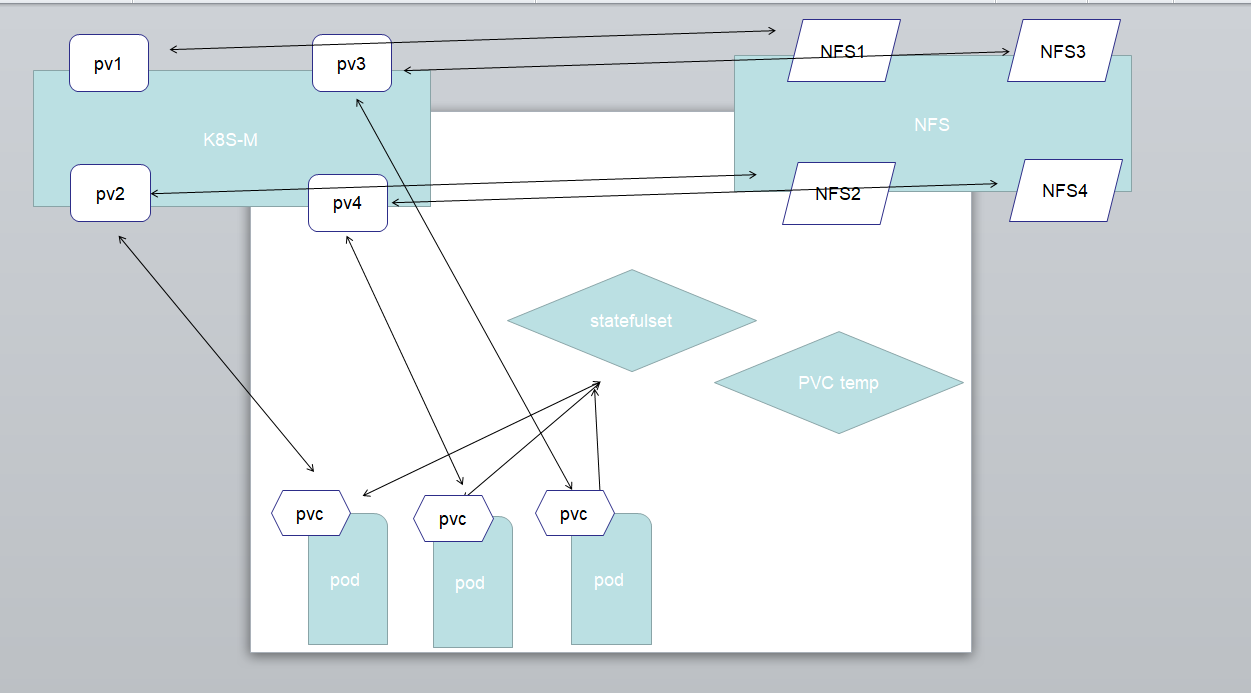
以上实验的总结理解:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律