
pyspark集成访问hive数据踩坑记录
当前环境anaconda3、python3.9.13、jupyter
需要安装的pyspark、py4j
pyspark和py4j的离线安装包地址Links for pyspark (tsinghua.edu.cn) 和 Links for py4j (tsinghua.edu.cn)
一开我自己没有仔细的对应版本,找了一个pyspark3.4.1的包正常安装上去了,通过pyspark进入shell可以正常连接查询hive的数据,但是通过python shell和jupyter执行代码异常,报py4j下一个类加载不到,当时还挺纳闷的,pyspark正常,这个应该也是没问题才对,后面查了一下spark的版本,用的spark3.1.1,然后重新安装了这pyspark3.1.1后,可以正常的创建sparkssesion对象了,但是执行spark.sql("show databases").show() 报错了,报了认证的错误,hive这边配置了Kerberos认证。
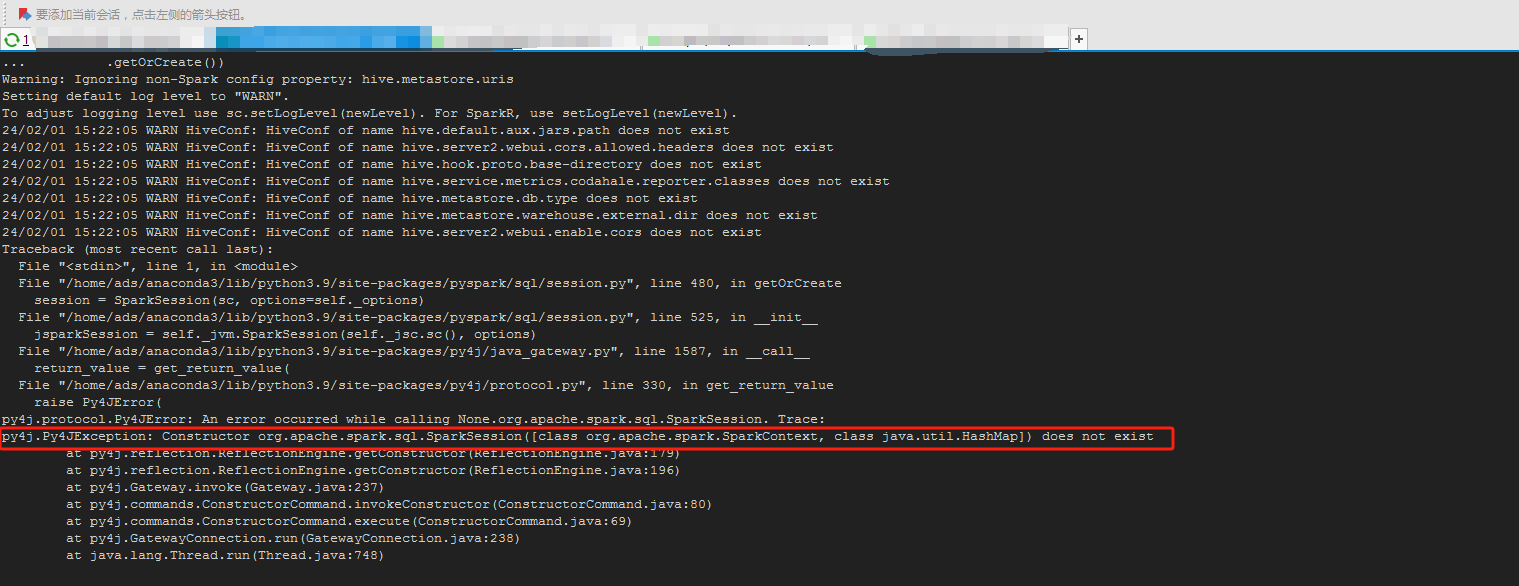
这个是一开始用的代码,这个时候是没有加认证参数,后面加了认证参数还是一样的问题
import os
import sys
os.environ['SPARK_HOME'] = "/usr/local/spark3"
sys.path.append("/usr/local/spark3/python")
sys.path.append("/usr/local/spark3/python/lib/py4j-0.9-src.zip")
try:
from pyspark import SparkContext
from pyspark import SparkConf
print ("success")
except ImportError as e:
print ("error importing spark modules", e)
sys.exit(1)
from pyspark.sql import SparkSession
spark = (SparkSession
.builder.master('yarn')
.appName('test')
.config("spark.sql.warehouse.dir", "hdfs://path")
.config("spark.kerberos.krb5Conf", "/etc/krb5.conf")
.config("spark.kerberos.keytab", "/tmp/keytab/xxx.keytab")
.config("spark.kerberos.principal", "xxxxx/域名@xxxxx")
.config("hive.metastore.uris", "thrift://ip:9083,thrift://ip:9083,thrift://ip:9083")
.enableHiveSupport()
.getOrCreate())
spark.sql('show databases').show()
spark.stop()然后报了这个问题,认证出问题
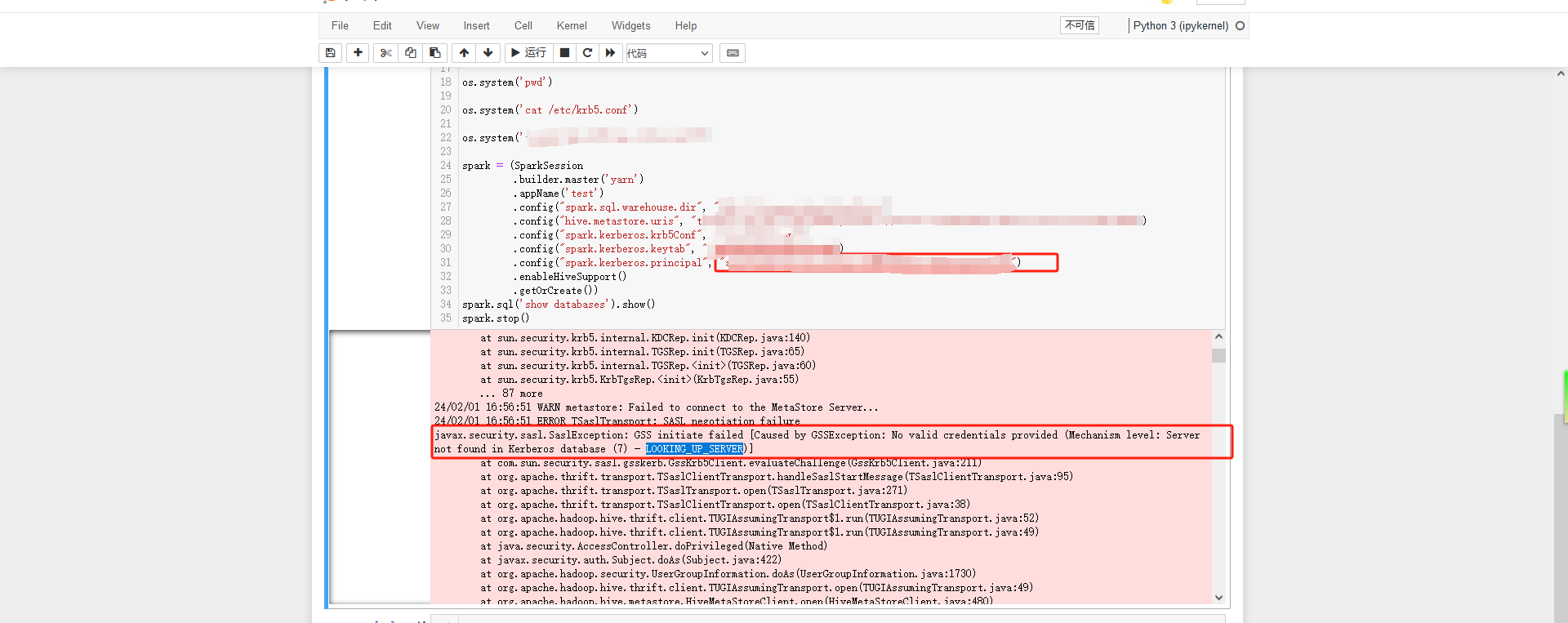
后面网上找了一个下这个LOOKING_UP_SERVER的认证报错,说是没有对应的规制,但是这个我直接上测试换kinit的,正常可以用没问题,其实这个情况已经就差最后一步就成功了,然后就去扒拉kdc认证的日志,然后就发现了问题,连hivemetastore的时候使用了xxx/ip@xxxxx,问题就在这里了,kdc规制都是用域名的xxx/域名@xxxxx,所以报了规制不存在,将metastore改成thrift://域名:9083,thrift://域名:9083,thrift://域名:9083,重新连接就正常了
