Flume原理简介 + 组件
1.1 简介
Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制。flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。简单来讲,在组件中它的作用就是负责收集数据。
1.2 特性
1.Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
2.可以采集文件,socket数据包、文件、文件夹、kafka等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中。
3.操作简单,只需要通过配置项来控制source和sink
4.具备良好的自定义扩展能力,在数据采集中可优先考虑使用它
1.3 组件
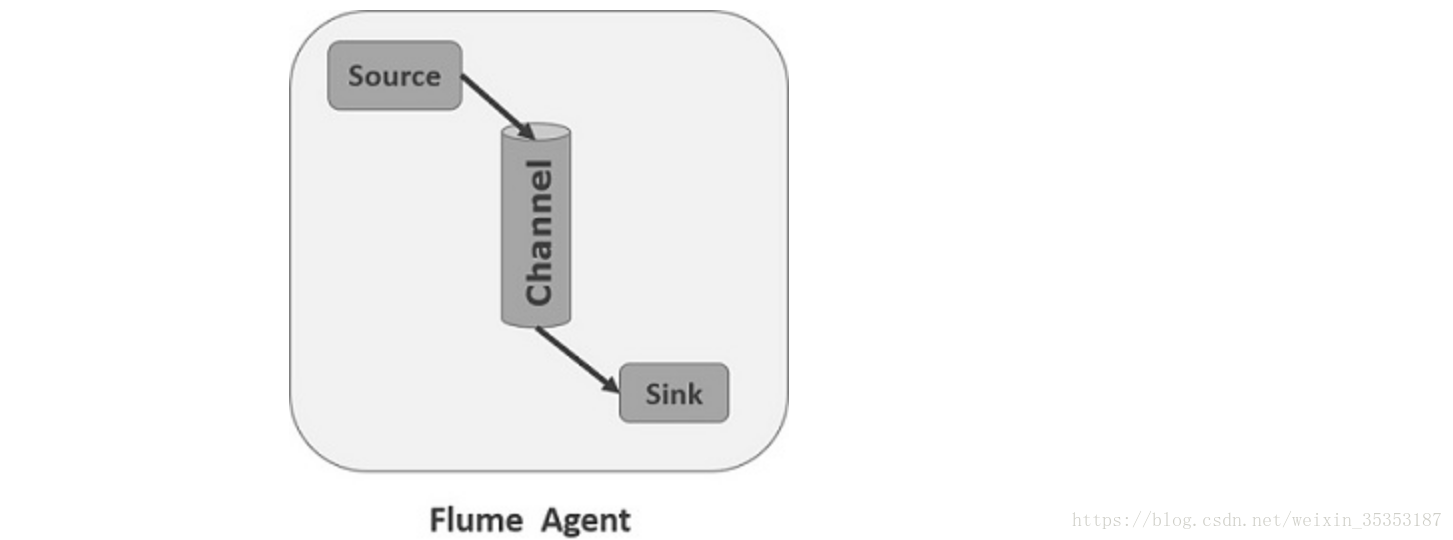
Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
每一个agent相当于一个数据(被封装成Event对象)传递员,内部有三个组件:
Source:采集组件,用于跟数据源对接,以获取数据。source 组件可以处理各种格式的日志数据,eg:avro Sources、thrift Sources、exec、jms、spooling directory、netcat、sequence generator、syslog、htp、legacy、自定义。
Source类型 说明
Avro Source 支持Avro协议(实际上是Avro RPC),内置支持|
Thrift Source 支持Thrift协议,内置支持
Exec Source 基于Unix的command在标准输出上生产数据
JMS Source 从JMS系统(消息、主题)中读取数据
Spooling Directory Source 监控指定目录内数据变更
Twitter 1% firehose Source 通过API持续下载Twitter数据,试验性质
Netcat Source 监控某个端口,将流经端口的每一个文本行数据作为Event输入
Sequence Generator Source 序列生成器数据源,生产序列数据
Syslog Sources 读取syslog数据,产生Event,支持UDP和TCP两种协议
HTP Source 基于HTP POST或GET方式的数据源,支持JSON、BLOB表示形式
Legacy Sources 兼容老的Flume OG中Source(0.9.x版本)
Channel:传输通道组件,用于从source将数据传递到sink,而且Channel中的数据直到写进sink才会被删除,若写入失败,可以自动重启,不会造成数据丢失。临时存放的数据可以存放在memory Channel、jdbc Channel、file Channel、自定义。
Channel类型 说明
Memory Channel Event数据存储在内存中
JDBC Channel Event数据存储在持久化存储中,当前Flume Channel内置支持Derby
File Channel Event数据存储在磁盘文件中
Spillable Memory Channel Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件
Pseudo Transaction Channel 测试用途
Custom Channel 自定义Channel实现
Sink:下沉组件,用于往下一级agent传递数据或者往最终存储系统传递数据,运行在一个独立的线程。
一行文本内容会被反序列化(流——>对象)成一个event。序列化是将对象状态转换为可保持或传输的格式的过程(对象——>流)。这两个过程结合起来,可以轻松地存储和传输数据),event的最大定义为2048字节,超过,则会切割,剩下的会被放到下一个event中,默认编码是UTF-8。
1.4 内容示例:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
## exec表示flume调用给的命令,然后从给的命令的结果中去拿数据
a1.sources.r1.type = exec
## 使用tail这个命令来读数据
a1.sources.r1.command = tail -F /home/hadoop/testdir/flumedata/test.log
a1.sources.r1.channels = c1
# Describe the sink
## 表示下沉到hdfs,类型决定了下面的参数
a1.sinks.k1.type = hdfs
## sinks.k1只能连接一个channel,source可以配置多个
a1.sinks.k1.channel = c1
## 下面的配置告诉用hdfs去写文件的时候写到什么位置,下面的表示不是写死的,而是可以动态的变化的。表示输出的目录名称是可变的
a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/tailout/%y-%m-%d/%H%M/
##表示最后的文件的前缀
a1.sinks.k1.hdfs.filePrefix = events-
## 表示到了需要触发的时间时,是否要更新文件夹,true:表示要
a1.sinks.k1.hdfs.round = true
## 表示每隔1分钟改变一次
a1.sinks.k1.hdfs.roundValue = 1
## 切换文件的时候的时间单位是分钟
a1.sinks.k1.hdfs.roundUnit = minute
## 表示只要过了3秒钟,就切换生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 3
## 如果记录的文件大于20字节时切换一次
a1.sinks.k1.hdfs.rollSize = 20
## 当写了5个事件时触发
a1.sinks.k1.hdfs.rollCount = 5
## 收到了多少条消息往dfs中追加内容
a1.sinks.k1.hdfs.batchSize = 10
## 使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream:为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
# Use a channel which buffers events in memory
##使用内存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
1.5 启动命令:
cd /opt/flume-1.8.0
bin/flume-ng agent -c conf -f conf/exec_tail.conf -n a1 -Dflume.root.logger=INFO,console
参数:
-
agent -
--conf / -c <conf>:在<conf>目录使用配置文件,指定配置文件放在什么目录 -
--conf-file / -f <file>:指定配置文件,这个配置文件必须在全局选项的 --conf 参数定义的目录下 -
--name / -n <name>: Agent 的名称,同配置文件中的相对应
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号