8.总结Hive中的窗口函数以及anti join,semi join
相关函数说明: OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化 CURRENT ROW:当前行 n PRECEDING:往前n行数据 n FOLLOWING:往后n行数据 UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
LAG (scalar_expression [,offset] [,default]):往前第n行的数据 (下沉) LEAD (scalar_expression [,offset] [,default]):往后第n行数据 (上浮)
(scalar_expression:关键字 offset:偏移量 default:默认值)
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。
准备一些测试数据:
spark.sql("create table if not exists test0824(name string,ctime string,money int)")
spark.sql("""
insert overwrite table test0824 values('zs','2020-01-01',10.0),
('ls','2020-01-02',15.0),
('zs','2020-02-03',23.0),
('ls','2020-01-04',29.0),
('zs','2020-01-05',46.0),
('zs','2020-04-06',42.0),
('ls','2020-01-07',50.0),
('zs','2020-01-08',55.0),
('ww','2020-04-08',62.0),
('ww','2020-04-09',68.0),
('zl','2020-05-10',12.0),
('ww','2020-04-11',75.0),
('zl','2020-06-12',80.0),
('ww','2020-04-13',94.0)
""")
spark.sql("select *,count(1)over() total_persion,sum(money)over() total_money from test0824 order by name,ctime;").show()
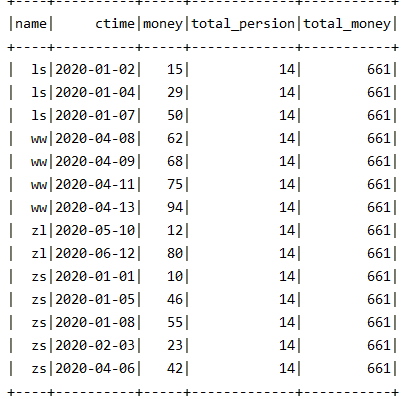
一 窗口函数:
row_number():每个窗口内生成一个伪列用来排序,不可重复(1,2,3,4,5,6)
rank():窗口排名可以重复,重复后续会有空位(1,2,3,3,5,6)
dense_rank():窗口内排名可以重复,重复后续无空位(1,2,3,3,4,5)
控制窗口大小:
over():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
1- partition by():控制窗口大小
上面是对全局开窗的展示,下面根据name来开窗:
spark.sql("select *,count(1) over(partition by name) total_persion,sum(money) over(partition by name) total_money from test0824;").show()
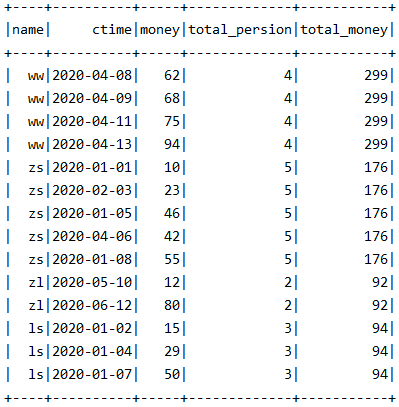
2- UNBOUNDED PRECEDING 和 CURRENT ROW
(在计算时,通过该函数可以控制窗口内参与计算的范围)
-- 计算每个人的开始的消费金额到当前时间消费金额的和 spark.sql("select *,sum(money)over(partition by name rows between unbounded preceding and current row)total_money from test0824;")
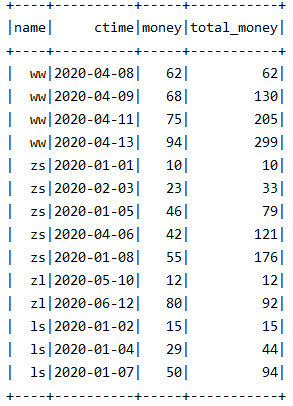
- 注意:当进行排序后 默认从起始行到当前行
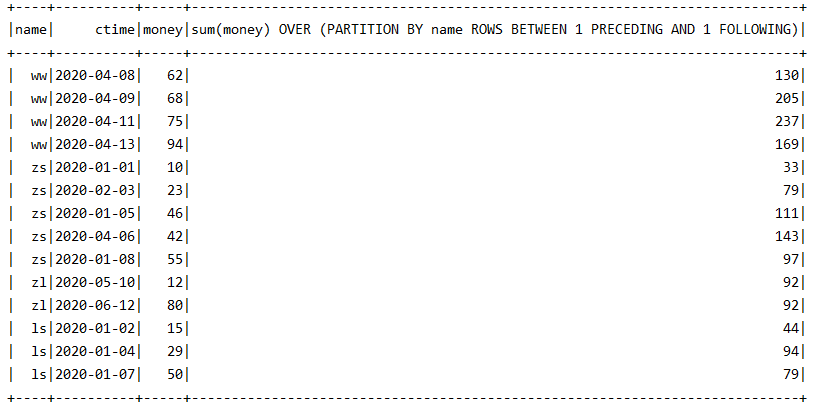
3- n PRECEDING 和 n FOLLOWING
( 当前数据的前n行到到当前数据的后n行 )
-- 窗口中每一行与上下邻近两行的和 spark.sql("select *,sum(money)over(partition by name rows between 1 preceding and 1 following) from test0824;")
二 anti join 和 semi join
1、a left anti join b : 在查询过程中,剔除a表中和b表中有交集的部分
常见应用场景:求增量数据时常用此功能剔除之前数据。
2、a left semi join b : 取出相交的那部分数据,但与INNER JOIN有所不同:当b表中存在重复的数据(这里假设有两条),当使用INNER JOIN 的时候,b表这两条重复数据都会参与关联;但是用LEFT SEMI JOIN时,当a表中的记录,在b表上产生符合条件之后就返回,不会再继续查找b表记录了,所以如果b表有重复,也不会产生重复的多条记录。
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号