2.Kafka的工作原理及数据丢失、数据重复问题
一、概述
一个分布式消息中间件,基于zookeeper的分布式日志系统。(最新的3.0版本摆脱了对zookeeper的依赖,游标改为记录在一个单独的队列里)
简单来讲,就是一个存储系统,起一个缓冲作用。
所谓的消息系统,就是将数据从一个地方传递到另一个地方。消息传递模式有两种:点对点传递模式,发布-订阅模式。Kafka是一种发布-订阅模式。
二、特点
1.解耦:
消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2.异步:
支持用户将消息放入队列中,不立刻处理,需要的时候再去处理。
3.削峰:
使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
举个例子:A系统高并发状态下,可能会出现连接异常甚至崩溃的情况,这个时候我们能选择一个中间件,将所有客户的请求都放入消息队列中,A系统只需要从消息队列中拉取消息再做处理即可。
三、角色
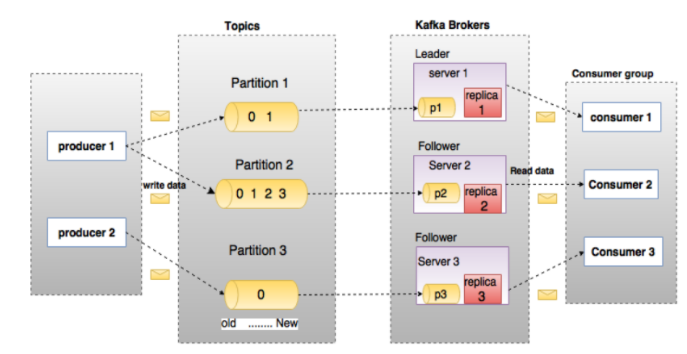
1.Topic消息队列:
发布到Kafka集群的消息的类别。(就看作是一个个的消息队列名,用来找到对应的消息队列)。
(1)Partition:topic中数据的具体管理单元。
一个topic 可以划分为多个partition,分布到多个 broker上管理;
partition 中的每条信息都会被分配一个递增的id(offset);
每个 partition 是一个有序的队列,各个 partition 间是无序的。换句话讲,如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
每个partition都可以有多个副本;
分区对于 kafka 集群的好处是:实现topic数据的负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
(2)Broker:
Kafka集群包含一个或多个服务器,服务器节点称为Broker。容纳多个topic的多个partition。
(3)Offset:
消息在这底层存储中的索引位置,看作一个游标,通过它来确定消息的位置。
2.Producer生产者:
数据的发布者,发送消息给Broker。
3.Consumer消费者:
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
4.Leader和Follower:
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个
Follower。
四、数据丢失和数据重复问题:
在处理这两个问题之前,先来了解两个机制:ACK应答机制和RETIRES延迟重发机制。
ACK应答机制:
在生产者端:broker往内存中写数据时,同时也会进行数据持久化操作,并根据你有多少个Leader和Follower,生成副本。内存先向Leader传输,完成后由leader向Follower进行备份。
此时就要考虑到备份的副本是否完成的问题。这里ACK应答机制可设三个参数:
* 设 0 :不等broker同步完成的确认,继续发送下一条信息。不管数据的持久化,只要内存已处理完,直接传输下一条 (速度快 但不稳定)
* 设 1 :等broker同步完成1次,就继续发送下一条信息。数据持久化只要Leade一完成,就进行下一次传输,不管Leader向Follower的备份 (速度较快 但如果落盘位置挂掉,没有备份数据)
* 设 -1 :等broker全部同步完成,再发送下一条信息。等到数据持久化全部完成(包括备份的),才进行下一次的传输 (稳定,全部落盘才进行下一次的数据传输)
注意:ACK机制只保证写入端的数据安全问题(不丢失),不会去管你数据是否重复等等。
RETIRES延迟重发机制:
ACK应答机制(即便选择-1完全同步)只能保证数据全部备份下来,但不能确定备份数据的节点是否活跃,假如某台机器宕机,这时就需要重复机制,隔段时间再次重新发送一遍。
注意:这里虽避免了数据丢失,但可能会造成数据重复。而且,如果重发后还无
响应,就会跳过这条数据继续下一次的发送,造成该数据丢失
所以,总结如下:
造成数据丢失的原因:
1. ACK应答机制设置为0,数据没有落盘保存,只是在内存中走了一遭,此时内存中的数据一旦没了,那就会造成数据丢失。
设置为1,那么数据只会落盘保存到Leader上,Leader还没向Follower中同步时,此时Leader挂掉,数据丢失。
2. Offset设置为自动提交,他的机制是定时自动提交,如果提交时,数据还没处理完,但数据偏移量已经改变,下次读取的是下一个位置处的数据,而这部分未处理的数据所在节点一旦出现故障,数据也会丢失。
解决办法:
ACK应答机制设为-1(或者all),并且关闭手动提交,提交时采用同步模式
prop.put( ProducerConfig.ACKS_CONFIG, "all");
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
consumer.commitSync();
造成数据重复的原因:
1.延迟重发机制下,节点出现故障导致主从数据同步未完成,他会重新发送一遍
2.已经消费完成,但是offset还未提交,此时节点挂掉,下一次还是会从之前的offset处里数据,重复消费。
解决办法:
1.手动维护offset(但仍有风险);
2.加大kafka.consumer.session.timeout参数,避免错误关闭的情况。
3.在下游选择Hbase或者redis等进行去重。
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号