2.Hbase的读写流程
Hbase框架不同于一般框架,一般框架都是读快写慢,而Hbase恰恰相反,他的写要更快些。
写数据流程:
1.发出请求:
(第一次交互)客户端通过Zookeeper的调度,通过它上面的meta表,找到meta表所在的HregionServer位置信息,返回给客户端;
(第二次交互)客户端再次交互上面所获取的HregionServer,通过你要查的这张表的表名和RowKey,找到这条数据所在的表的具体位置(多个HregionServer中的具体某一个),将该HregionServer返回给客户端;
(第三次交互)客户端通过二所获取的HregionServer找到所在位置,进行写操作。到这里写数据就完成了。
注意:老版本里zookeeper还有一个-root-表,他记录的是.meta.表的信息,就是在最开始多了一次交互。

2.写到内存后落盘:
数据写入到Hregion的Memstore(内存)中,直到达到阈值(128M),进行flush操作,持久化到StoreFile;
3.“先合再分”:
在Hregion上,StoreFile文件不断增多,到达一个阈值后(一般3-10个文件),进行Compact合并操作,合成一个StoreFile,而不断的合并,达到一定阈值后,进行split溢写操作,把当前Hregion分成两个Hregion(由HregionServer负责),同时父Hregion下线,生成的两个新的被Hmaster分配到相应的HregionServer上。写数据完成。
由此可见,Hbase只有增添数据的操作,我们的修改和删除都是再后续的Compact中得以实现(覆盖原数据:根据rowkey+列簇+列全部对应后,如果全一致,就会生一个新的版本,
也就是时间戳,你下次读对应的数据他会返回给你最新的版本),客户端进行写数据操作时,只要进入内存,就立刻返回,这也正是Hbase的IO高效所在原因
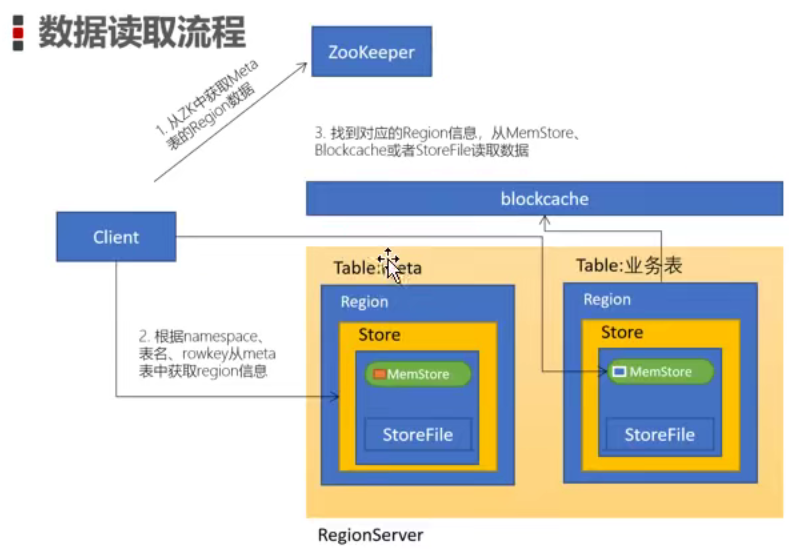
读数据流程:
HBase读取数据两种方式:get和scan。
通常我们都是根据rowkey来查找,
- 从rowkey来找这张表table,而table从行的方向上又分为了多个region,每一个region他有一个特殊属性:startkey - endkey,这样就能判断你的rowkey是否在这个region上。region里对应又有多个store(存放的是列簇)。
- 找到他所在的region便可找到他所在的regionserver,因为最终客户端还是要和regionserver进行交互。
1.客户端访问Zookeeper,查找-root-表(之前我所提的“根表”),获取.meta.表信息,它里面存的是所有表的元数据(在哪个region上),进而找到在哪一个HregionServer上维护。
2.HregionServer的内存分为Memstroe和BlockCache两部分,前者主要用来写数据,后者主要用来读数据。当读数据 请求过来时,先到Memstore中查找,找不到再去BlockCache中查,再查不到才去StoreFile上读,读到后把结果返回并放入到BlockCache(下次再查这条就更快了)。
这里就把memstore看成一个记忆缓存,blockcache堪称是一个二级缓冲。
归纳下:
client >> zookeeper >> -root- >> .meta. >> Hregion >> HregionServer >> client
由此可见:
读写数据流程其实并不需要Hmaster的参与,这部分工作依赖于zookeeper,这时即便你的Hmaster宕掉也不影响。
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号