
MapReduce中的shuffle过程
1.Map task输出k-v对
2.环形缓冲区
map阶段在最后会通过MapOutputBuffer来将数据暂时存储到一个环形缓冲区,在缓冲区写入的数据达到阈值(80%)后,才会开始从这里再写出到磁盘(落盘)。由此可见:环形缓冲区的设计直接影响Map Task的输出效率。
上面大致的流程中,我们不禁有这么几个疑问:
1.什么是环形缓冲区?为什么使用它?
2.缓冲区框架阈值为什么设置为80%?
3.环形缓冲区内部的读写时是什么样的?
下面就通过整体上模拟来解决这些问题。
2.1首先来认识下缓冲区:
缓冲区包含有:单向、双向、环形。这里主要介绍环形。
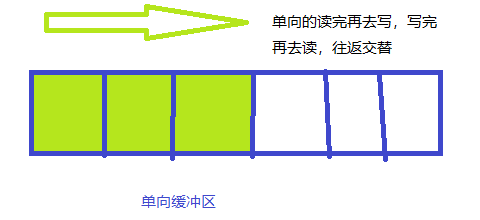
2.1.1 单向缓冲区:
这个很简单,输出的数据直接向缓冲区单向的写入,写满后,一次性开始落盘。不断循环往复。也可以看出,它最大的缺点就是性能太低,不能并发状态下读写数据。
2.1.2 双向缓冲区:
针对于上面的单向缓冲区,在一定程度上进行了一些改进:使用两个缓冲区,原则上一读一写,交替进行,在一定程度上让读写并行(读写效率并不一致,所以有时还是做不到完全并发,出现读写等待的问题)。

2.1.3 环形缓冲区:
1— 》什么是环形缓冲区?
上面双向缓冲区的基础上,再次改进,设计一个环形的(闭环)缓冲区,写入到一定阈值之后,开始写出,同时并发状态下,继续向不断增加的剩余空间写入,写入后写出某种意义上来讲,互不影响。完全达到并发读写

2— 》工作原理:
在环形缓冲区内保存好数据后(80%),有SpillThread线程来将数据写到一个临时文件中,当所有数据全部处理完成之后,对所有文件进行一次合并,生成一个终极文件。这样就使得Map Task任务中的的Collect阶段和Spill阶段并行进行。
3—》索引(写出时怎么找数据)
环形缓冲区内部采用了两级索引,设计了三个环形内存缓冲区:kvoffsets、kvindices和kvbuffer。框架默认这三个共占据空间大小为100M(可改)。其中:
kvbuffer:真正的数据缓存区。存放的就是map端甩来的kv对,默认最多占据95%,超过这个值,便会触发SpillThread,开始溢写。
kvindices:位置索引数组。存放的是kv值在数据缓冲中的起始位置。
kvoffsets:kv偏移量索引数组。保存我们的key/value信息在位置索引kvindices中的偏移量。
kvbuffer占95%,kvoffsets占3.75%,kvindices1.25%
2.2 环形缓冲区工作原理

将一个环形缓冲区展开来看成矩形,首尾本来是相接的,最初,在开始位置有三个指针,(如图红、绿、蓝)分别用来标记写入过程中的开始写的位置(start),数据所占据的(末尾)位置index,以及标记要溢写部分的结尾位置(end)。
2.3 环形缓冲区内工作流程
==============
开始写入数据,index指针随着数据的写入向后移动,start和end保持不动。直到index标记到环形缓冲区80%的地方,此时end指针直接跳到index的位置,start指针不动。那么,此时从start位置到end位置这一区域内的数据,就是我们第一次要溢写的数据,开始溢写。
==============
溢写的同时,start向后移动,同时,继续向环形缓冲区内写入,index指针向后移动,end指针保持不动,这样就使得读写并行。当上一次的溢写完成后,end指针此时如果跳转到了下一个80%的index位置,再次开始溢写。
==============
80%=(end-start)+(index-end)
==============
问:什么阈值设为80%?
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
这里解释一下,map完事之后,会放到一个内存缓冲区里面,上边那个0.8的阈值,说的就是只要使用到百分之80了,就可以做溢写,写到磁盘去。
这里要百分之80的阈值做溢写的原因是:如果没有这百分之80做溢写这个事情
整个环形容器都做缓冲区,map一直输出把缓冲区给占满,没有空闲了,这个时候map会阻塞,就不能往后写了。会把空间给锁住,锁完之后开始做溢写,写完磁盘把空间腾出来之后,才可以继续往里写,这是个线性的时间。
如果我们做了这百分之80的阈值,map输出向这百分之80写,写满了,还有百分之20, 这个时候,map向剩下的百分之20去写的同时,这百分之80做溢写,这个会有一部分时间轴重叠了,会压缩我们的时间,这就是为什么要80做阈值。当然我们可以根据数据来做调整。
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}


