
sqoop的配置与使用
一、sqoop的安装
1. 先将sqoop的压缩包上传至/opt里面,执行解压
tar -zxvf /opt/download/hadoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/soft/sqoop146
2. 进入到conf目录下,复制sqoop-env-template.sh,并进行编辑
cd /opt/soft/sqoop146/conf cp sqoop-env-template.sh sqoop-env.sh vim sqoop-env.sh
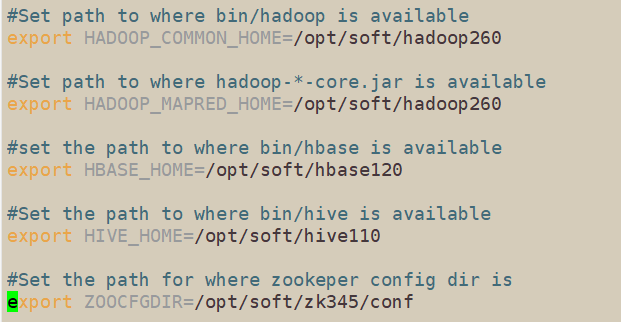
3. 编辑内容如下:将需要连接的数据库的目录导入
4. 复制驱动包进来(需要链接什么数据库就导什么数据库的驱动包)
全部复制到sqoop下的lib包内
这里我先把mysql和oracle的驱动包以及java-json.jar导入;
还有hive的驱动包:
[root@hadoopsingle lib]# cp /opt/soft/hive110/lib/hive-jdbc-1.1.0-cdh5.14.2-standalone.jar ./
还有Hadoop的几个包:
#拷贝hadoop-common
[root@chust01 lib]# cp /opt/software/hadoop/hadoop260/share/hadoop/common/hadoop-common-2.6.0-cdh5.14.2.jar ./
#拷贝hadoop-hdfs
[root@chust01 lib]# cp /opt/software/hadoop/hadoop260/share/hadoop/hdfs/hadoop-hdfs-2.6.0-cdh5.14.2.jar ./
#拷贝hadoop-mapreduce-client-core
[root@chust01 lib]# cp /opt/software/hadoop/hadoop260/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0-cdh5.14.2.jar ./
5. 配置环境变量
#sqoop environment export SQOOP_HOME=/opt/soft/sqoop146 export PATH=$PATH:$SQOOP_HOME/bin
配置完记得source一下,然后sqoop version命令查看下
6. 启动hadoop,测试下sqoop
start-all.sh #测试命令,连上和登陆数据库,连接上之后会出现当前数据库的列表,否则失败。在虚拟机中中,回车默认是提交符,需要增加\转义符 sqoop list-databases \ --connect jdbc:mysql://192.168.221.140:3306 \ --username root \ --password kb10
二、sqoop的使用
sqoop一般就是我们用来将mysql等数据库的数据拉到hdfs上,在传入hive,或者反向操作等。就是一个传输数据的工具,本质上还是个命令行工具。核心功能就是导入和导出:
导入数据:MySQL导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库mysql 等
这里以mysql为例进行操作。
2.1、mysql 导出到 hdfs
四种导入方式:(具体用那种看需求)
2.1.1全量导入
将数据库中的某表整张表导入到hdfs上(这里我以mysql中的Bank表,含id,name,money三个字段为例)
-- 全量导入 sqoop import \ --connect jdbc:mysql://192.168.192.200:3306/mydemo \ --username root \ --password okok \ --table Bank \ --target-dir '/zyp/bank' \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by ','
2.1.2导入指定部分的列
只要名字和money,不要id列
sqoop import \ --connect jdbc:mysql://192.168.192.200:3306/mydemo \ --username root \ --password okok \ --target-dir '/zyp/bank' \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by ',' \ --columns name,money \ --table Bank
2.1.3导入部分行,select查询结果导入。如果用的双引号,$CONDITIONS前面要加转义符,否则会被识别为shell的变量报错。
将查询到的钱数大于1300的数据导入,其余过滤:
-- 按照条件进行查询 将查询到的数据增量导入 sqoop import \ --connect jdbc:mysql://192.168.192.200:3306/mydemo \ --username root \ --password okok \ --target-dir '/zyp/bank' \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by ',' \ --query 'select * from Bank where money>1300 and $CONDITIONS'
2.1.4使用sqoop关键词筛选查询导入数据,使用where子句
sqoop import \ --connect jdbc:mysql://192.168.192.200:3306/mydemo \ --username root \ --password okok \ --target-dir '/zyp/bank' \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by ',' \ --table Bank \ --where 'id=2'
2.2、hdfs 导出到 mysql
这里就再将之前我们上传到hdfs 上的‘zyp/bank’的数据再导出到mysql中的bank表(这个表小写,之前那个表大写)
首先要去mysql那边创建好表(用like的建表语法,只要表结构不要表数据),然后执行以下命令:
sqoop export \ --connect jdbc:mysql://192.168.192.200:3306/mydemo \ --username root \ --password okok \ --table bank \ --export-dir '/zyp/bank' \ --num-mappers 1 \ --input-fields-terminated-by ','
然后去mysql那边查看下你的新表。
2.3、mysql 导出到 hive
先启动hive:
hive --service hiveserver2
进入到hive创建一张表:
hive> create table hive_bank( > id string, > name string, > money string) > row format delimited fields terminated by ',';
然后执行下面命令,直接甩到hive上:
sqoop import \ --connect jdbc:mysql://192.168.192.200:3306/mydemo \ --username root \ --password okok \ --table Bank \ --num-mappers 1 \ --hive-import \ --fields-terminated-by ',' \ --hive-overwrite \ --delete-target-dir \ --hive-table mydemo.hive_bank
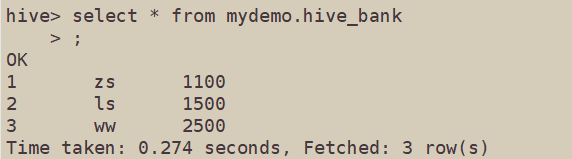
然后去hive上select一下结果:
2.4、hive 导出到 MySQL
1.先去mysql上创建新表 只要表结构不要数据
2.找到你hive上所要导出的这张表再hdfs上的位置,这里我是内部表,路径:
/hive/warehouse/mydemo.db/hive_bank
3.执行下面命令:
sqoop export \ --connect jdbc:mysql://192.168.192.200:3306/mydemo \ --username root \ --password okok \ --table bank1 \ --export-dir '/hive/warehouse/mydemo.db/hive_bank' \ --num-mappers 1 \ --input-fields-terminated-by ','
4.然后去MySQL里查询一下新表bank1
[root@hadoopsingle lib]# cp /opt/soft/hive110/lib/hive-jdbc-1.1.0-cdh5.14.2-standalone.jar ./
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}


