
3.HBase常用命令与实操
启动顺序:
Hadoop(start-all.sh)
zookeeper (zkServer.sh start)
hbase (start-hbase.sh)
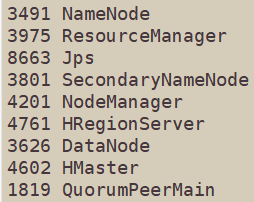
jps看下进程:
DDL:
创建命名空间:
create_namespace '命名空间'
查看命名空间:
describe_namespace '命名空间名称'
列出所有命名空间:
list_namespace
查看命名空间下的表:
list_namespace_tables '命名空间名称'
创建表:
create '命名空间:表名','列簇1','列簇2'
注意,这里不指定命名空间会给default。
创建预分区:
create '命名空间:表名','列簇',...,'分区名字',SPLITS => ['1000','2000','3000']
上面这个命令使得我们对表进行分区,相当与切三刀(1000,2000,3000),分成了四份(0-1000,1000-2000,2000-3000,3000- ~)
还可以通过提前在文件中写好分区档次:
create '命名空间:表名' , '列簇' , SPLITS_FILE => '/opt/test.txt'
删除表:
disable '命名空间:表名' -- 先要停止表的使用,否则删不掉
drop '命名空间:表名'
DML:
插入数据:
put '命名空间:表名',‘行间’,‘列簇:属性名’,‘属性值(多个之间用“,”隔开)’
修改数据:(还是put,定位到了直接覆盖)
put '命名空间:表名',‘行间’,‘列簇:属性名’,‘属性值(多个之间用“,”隔开)’
查看数据:
get '命名空间:表名','行间' -- 查看指定行数据
scan '命名空间:表名' -- 查看全数据
删除数据:
delete '表名' , '行键' , '列簇:列' (删除指定列)
deleteall '表名','行键' (删除整行数据,不管多少个版本(时间戳),该rowkey下的全删)
(HBase shell中不可以删除整个列簇,但在HBase API中可以,下一篇博客)
加过滤器的查:
scan 'mydemo:userinfos',FILTER=>"RowFilter(<,'binary:2')" -- binary按照二进制进行比较
scan 'mydemo:userinfos',FILTER=>"RowFilter(=,'substring:1')" -- substring截取后面的内容 只要包含就显示出来(这里就是将所有行间包含1的全部取出,例如:1,11,21...)
PrefixFilter 前缀过滤
统计表内数据:
count '命名空间:表名' -- 效率较低
(切换至系统界面):hbase org.apache.hadoop.hbase.mapreduce.RowCounter '命名空间:表名' -- 推荐使用
将本地(或者hdfs)上的数据加载到表中:(file://代表本地路径(Linux),不加代表hdfs路径)
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=, -Dimporttsv.columns="HBASE_ROW_KEY,base:username,base:birthday,other:likes" mydemo:userinfos file:///opt/data/hbase.csv
实操部分:
先创建命名空间zyp:
create_namespace 'zyp'
在zyp命名空间下创建一张表student,列簇info:
create 'zyp:student','info'
插入数据:
put 'zyp:student','1001','info:sex','male' put 'zyp:student','1001','info:name','ZhangSan' put 'zyp:student','1001','info:age','24' put 'zyp:student','1002','info:sex','female' put 'zyp:student','1002','info:name','LiSi' put 'zyp:student','1002','info:age','25'
查看数据:(一种全查看scan,一种部分查看get)
scan全表查询:
hbase(main):019:0> scan 'zyp:student' ROW COLUMN+CELL 1001 column=info:age, timestamp=1636283989410, value=24 1001 column=info:name, timestamp=1636283953367, value=ZhangSan 1001 column=info:sex, timestamp=1636283946211, value=male 1002 column=info:age, timestamp=1636284057098, value=25 1002 column=info:name, timestamp=1636284079010, value=LiSi 1002 column=info:sex, timestamp=1636284097848, value=female 2 row(s) in 0.0100 seconds
注意: scan 这里还可通过指定行键范围(左闭右开)来查询:
hbase(main):023:0> scan 'zyp:student',{STARTROW=>'1001',STOPROW=>'1002'} ROW COLUMN+CELL 1001 column=info:age, timestamp=1636283989410, value=24 1001 column=info:name, timestamp=1636283953367, value=ZhangSan 1001 column=info:sex, timestamp=1636283946211, value=male 1 row(s) in 0.0120 seconds
get指定行键查询:(还可继续在细化到列簇,列)
hbase(main):020:0> get 'zyp:student','1001' COLUMN CELL info:age timestamp=1636283989410, value=24 info:name timestamp=1636283953367, value=ZhangSan info:sex timestamp=1636283946211, value=male 3 row(s) in 0.0140 seconds hbase(main):021:0> get 'zyp:student','1001','info' COLUMN CELL info:age timestamp=1636283989410, value=24 info:name timestamp=1636283953367, value=ZhangSan info:sex timestamp=1636283946211, value=male 3 row(s) in 0.0070 seconds hbase(main):022:0> get 'zyp:student','1001','info:name' COLUMN CELL info:name timestamp=1636283953367, value=ZhangSan 1 row(s) in 0.0050 seconds
修改1001数据的名字为ZhangSansan:
put 'zyp:student','1001','info:name','ZhangSansan'
hbase(main):012:0> scan 'zyp:student' ROW COLUMN+CELL 1001 column=info:age, timestamp=1636283989410, value=24 1001 column=info:name, timestamp=1636383647619, value=ZhangSan san 1001 column=info:sex, timestamp=1636283946211, value=male 1002 column=info:age, timestamp=1636284057098, value=25 1002 column=info:name, timestamp=1636284079010, value=LiSi 1002 column=info:sex, timestamp=1636284097848, value=female 1003 column=info:name, timestamp=1636383570552, value=WangWu
删除1001数据的sex列:
hbase(main):014:0> delete 'zyp:student','1001','info:sex' 0 row(s) in 0.0240 seconds hbase(main):015:0> scan 'zyp:student' ROW COLUMN+CELL 1001 column=info:age, timestamp=1636283989410, value=24 1001 column=info:name, timestamp=1636383647619, value=ZhangSan san 1002 column=info:age, timestamp=1636284057098, value=25 1002 column=info:name, timestamp=1636284079010, value=LiSi 1002 column=info:sex, timestamp=1636284097848, value=female 1003 column=info:name, timestamp=1636383570552, value=WangWu 3 row(s) in 0.0090 seconds
清空表数据:
truncate 'zyp:student'
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}


