4.Hive中的ODS、 DWD、 DWS、 ADS 数仓分层
1、数据仓库
我们常提的数仓(DataWarehouse),就是在我们已有的数据库(他是对数据的存储)的基础之上,增加了对数据的OLAP(On-Line Analytical Processing),支持复杂的数据分析操作,更侧重决策支持,提供直观易懂的查询结果,而数据库更着重的是事务处理。换句话讲,就是在数据库已经大量存在的情况下,进一步挖掘数据资源,它包括了一整套的ETL、调度、建模在内的完整理论体系。
一句话概括:
数据库面向事务处理任务;数据仓库中的数据是按照一定的主题域进行组织主题。
2、数据库和数仓区别:
| DW | 数据库 | |
| 用途 | 专门为数据分析设计的,涉及读取大量数据以了解数据之间的关系和趋势 | 用于捕获和存储数据 |
| 特性 | 数据仓库 | 事务数据库 |
| 适合的工作负载 | 分析、报告、大数据 | 事务处理 |
| 数据源 | 从多个来源收集和标准化的数据 | 从单个来源(例如事务系统)捕获的数据 |
| 数据捕获 | 批量写入操作通过按照预定的批处理计划执行 | 针对连续写入操作进行了优化,因为新数据能够最大程度地提高事务吞吐量 |
| 数据标准化 | 非标准化schema,例如星型Schema或雪花型schema | 高度标准化的静态schema |
| 数据存储 | 使用列式存储进行了优化,可实现轻松访问和高速查询性能 | 针对在单行型物理块中执行高吞吐量写入操作进行了优化 |
| 数据访问 | 为最小化I/O并最大化数据吞吐量进行了优化 | 大量小型读取操作 |
3、Hive中的数据分层
理论上一般分为三个层:ODS数据运营层、DW数据仓库层、ADS数据服务层。基于这个基础分层之上,再提交信息的层次,来满足不同的业务需求。
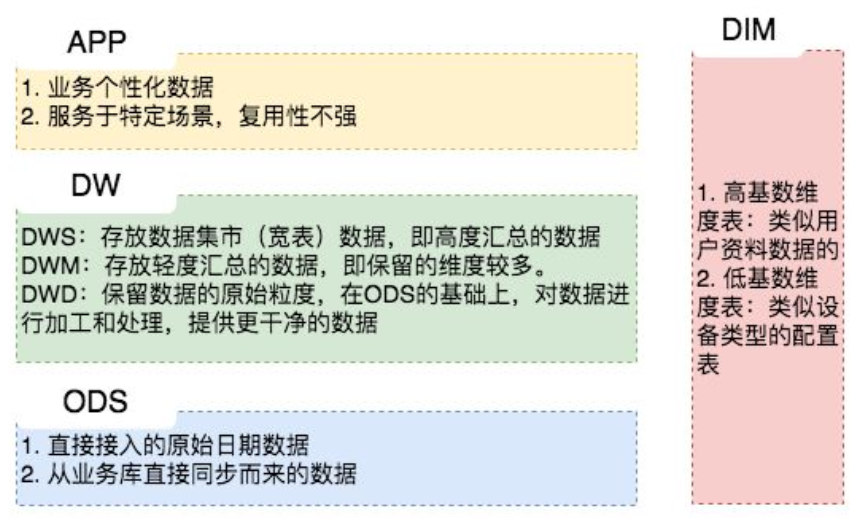
3.1数据运营层(ODS):原始数据
ODS:Operation Data Store 数据准备区,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,称为ODS层,是后续数据仓库加工数据的来源。
ODS层数据的来源方式:
- 业务库 : 经常会使用sqoop来抽取,例如每天定时抽取一次。
实时方面,可以考虑用canal监听mysql的binlog,实时接入即可。 - 埋点日志 : 日志一般以文件的形式保存,可以选择用flume定时同步
可以用spark streaming或者Flink来实时接入 - 消息队列:即来自ActiveMQ、Kafka的数据等.
3.2数据仓库层(DW):数据清洗,建模
DW数据分层,由下到上为DWD(数据明细层),DWM(数据中间层),DWS(数据服务层)。从 ODS 层中获得的数据按照主题建立各种数据模型。这一层和维度建模会有比较深的联系。
1> DWD:data warehouse details 细节数据层,是业务层与数据仓库的隔离层。主要对ODS数据层做一些数据清洗和规范化的操作。(依企业业务需求)
数据清洗:去除空值、脏数据、超过极限范围的
这一层主要是保证数据的质量和完整,方便后续层中特征分析
2> DWM:也有的称为DWB(data warehouse base) 数据基础层,对数据进行轻度聚合,存储的是客观数据,一般用作中间层,可以认为是大量指标的数据层。
这里最容易搞混,实际生产中甚至跳过这个,只有dwd和dws层,其实严格要求上来讲,dwd层数据来源于生产系统,只对数据负责,别的不考虑。而到了dwm层,已经开始向我们的业务层靠拢,要根据数据来进行分析和轻度聚合,进行细粒度统计和沉淀。
3> DWS:data warehouse service 数据服务层,基于DWB上的基础数据,整合汇总成分析某一个主题域的服务数据层,一般是宽表。按照业务进行划分:流量、用户、订单....用于提供后续的业务查询,OLAP分析,数据分发等。
在这一层我们还会建立维度模型,常见的有雪花模型和星型模型。维度建模一般按照以下四个步骤:
1. 选择业务过程 2. 声明粒度 3. 确定维度 4. 确定事实。
这一层主要对ODS/DWD层数据做一些汇总。我们希望80%的业务都能通过我们的DWS层计算,而不是ODS。
3.3数据服务层/应用层(ADS):出报表
ADS:applicationData Service应用数据服务,该层主要是提供数据产品和数据分析使用的数据,一般会存储在ES、mysql等系统中供线上系统使用。
我们通过说的报表数据,或者说那种大宽表,一般就放在这里。
4 数据来源
数据主要会有两个大的来源:
业务库,这里经常会使用 Sqoop 来抽取
在实时方面,可以考虑用 Canal 监听 Mysql 的 Binlog,实时接入即可。
埋点日志,线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用 Flume 定时抽取,也可以用用 Spark Streaming 或者 Storm 来实时接入,当然,Kafka 也会是一个关键的角色。
还有使用filebeat收集日志,打到kafka,然后处理日志
注意: 在这层,理应不是简单的数据接入,而是要考虑一定的数据清洗,比如异常字段的处理、字段命名规范化、时间字段的统一等,一般这些很容易会被忽略,但是却至关重要。特别是后期我们做各种特征自动生成的时候,会十分有用。
总结:
1. 原始数据拉取过来,保持和元数据同步,不做处理形成ODS层;
2. 基于ODS层,保持数据原始粒度,对数据加工和处理(也就是清洗),提供干净的数据作DWD层;
3. 根据ODS和DWD层数据,进行轻度汇总,保留较多维度,形成DWM层;
4. 基于以上所有DW层数据,进行高度汇总,形成DWS层。
DWS会做高度汇总,DWD和ODS粒度相同。

参考:
https://www.cnblogs.com/itboys/p/10592871.html
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号