
1.Hadoop上搭建hive;初始hhive;并运用zeppelin工具
一、准备阶段
1.搭建好Hadoop的服务器。
2.hive压缩包 上传至/opt
3.zeppelin压缩包 上传至/opt
二、开始搭建Hive
(确保安装mysql和hadoop)
首先上传hive至opt目录下 hive-1.1.0-cdh5.14.2.tar.gz
mkdir -p /opt/soft/hive110
解压hive
tar -zxf hive-1.1.0-cdh5.14.2.tar.gz -C /opt/soft/hive110 --strip-components
切换至conf文件下
cd /opt/soft/hive110/conf
创建一个文件:hive-site.xml
touch hive-site.xml
编辑此文件 hive-site.xml
vim hive-site.xml
向里面添加以下内容:
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!--hive元数据文件在hdfs上存放的位置--> <property> <name>hive.metastore.warehouse.dir</name> <value>/hive110/warehouse</value> </property> <property> <!--MySQL是否安装在本地 是为true 否为false--> <name>hive.metastore.local</name> <value>false</value> </property> <property> <!--hive链接MySQL 在本地就是localhost 远程写ip--> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.192.180:3306/hive?useSSL=false&createDatabaseIfNotExist=true&useSSL=false</value> </property> <property> <!--链接的驱动--> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <!--mysql登录用户名--> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <!--mysql登录用户密码--> <name>javax.jdo.option.ConnectionPassword</name> <value>okok</value> </property> <property> <!--第三方程序提供的用户名和密码,NONE说明不需要密码--> <name>hive.server2.authentication</name> <value>NONE</value> </property> <property> <!----> <name>hive.server2.thrift.client.user</name> <value>root</value> </property> <property> <!----> <name>hive.server2.thrift.client.password</name> <value>root</value> </property> </configuration>
配置hive环境
vim /etc/profile
添加:
#hive environment export HIVE_HOME=/opt/soft/hive110 export PATH=$PATH:$HIVE_HOME/bin
刷新配置文件
source /etc/profile
上传mysql的驱动包至/opt/soft/hive110/lib
启动hadoop:
start-all.sh
初始化一下hive:
schematool -dbType mysql -initSchema
登录
hive
(小海豚验证)
三、连接Hive的方法:
1.[root@hadoop101 conf]# hive
2.Beelin连接:
beeline -u jdbc:hive2://192.168.192.180:10000/mydemo
3.Zeppelin链接
四、配置Zeppelin
1.创建本地文件夹:mkdir -p /opt/soft/zeppelin081
上传zeppelin-0.8.1-bin-all.tgz至/opt
去opt目录下解压:
tar -zxf zeppelin-0.8.1-bin-all.tgz -C /opt/soft/zeppelin081 --strip-components 1
2.修改两个配置文件:
进入zeppelin的conf文件夹
cp zeppelin-site.xml.template zeppelin-site.xml
vim zeppelin-site.xml
向拷贝后的文件添加以下内容:
<property> <name>zeppelin.helium.registry</name> <value>helium</value> </property>
再拷贝 cp zeppelin-env.sh.template zeppelin-env.sh并修改
vim zeppelin-env.sh
找到以下内容修改(记得去掉前面注释!!!):
export JAVA_HOME=/opt/soft/jdk180
export HADOOP_CONF_DIR=/opt/soft/hadoop260/etc/hadoop
3.配置环境变量
#zeppelin environment export ZEPPELIN_HOME=/opt/soft/zeppelin081 export PATH=$PATH:$ZEPPELIN_HOME/bin
记得source一下
4.拷贝hive的hive-site.xml 文件到zeppelin081
cp /opt/soft/hive110/conf/hive-site.xml /opt/soft/zeppelin081/conf/
拷贝 hadoop-common-2.6.0-cdh5.14.2.jar 到 zeppelin081
cp /opt/soft/hadoop260/share/hadoop/common/hadoop-common-2.6.0-cdh5.14.2.jar /opt/soft/zeppelin081/interpreter/jdbc/
拷贝 hive-jdbc-1.1.0-cdh5.14.2-standalone.jar 到zeppelin081
cp /opt/soft/hive110/lib/hive-jdbc-1.1.0-cdh5.14.2-standalone.jar /opt/soft/zeppelin081/interpreter/jdbc/
(注意:如果是hive高版本 这个 jar 包位置有所不同,可能会在/opt/soft/hive312/jdbc下)
至此,zeppelin配置完成。
五、启动Zeppelin
1.启动Zeppelin
zeppelin-daemon.sh start
2.网页登录,端口8080
192.168.56.160:8080
3.在web界面配置集成hive
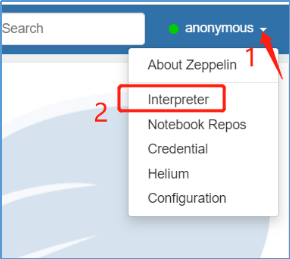
(1)右上角anonymous --> interpreter --> +Create新建一个叫做hive的集成环境
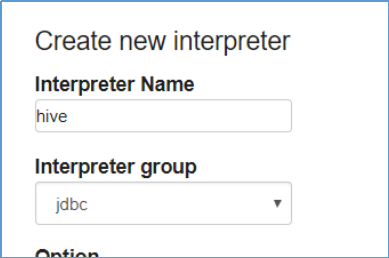
(2)设置properties
default.driver org.apache.hive.jdbc.HiveDriver
default.url jdbc:hive2://192.168.56.160:10000
default.user hive

点击保存,并重启hive 解释器。
以上都为交互模式
命令行模式:hive -e ‘.......’
Hive的使用
创建分区表
分区表操作:实际上就是建立一个个的文件夹,将数据按照你的分区约定,分别存放进去。分为静态分区和动态分区
创建一个分区表,id,name,birthmonth三列,其中按birthmonth分区:
%hive create table mydemo.my_part( id string, name string ) partitioned by (birthmonth string) -- 分区的那个列写在外面 row format delimited fields terminated by ','
手工创建一个静态分区
%hive alter table mydemo.my_part add partition(birthmonth='01') -- 实质上就是手工添加一个文件夹
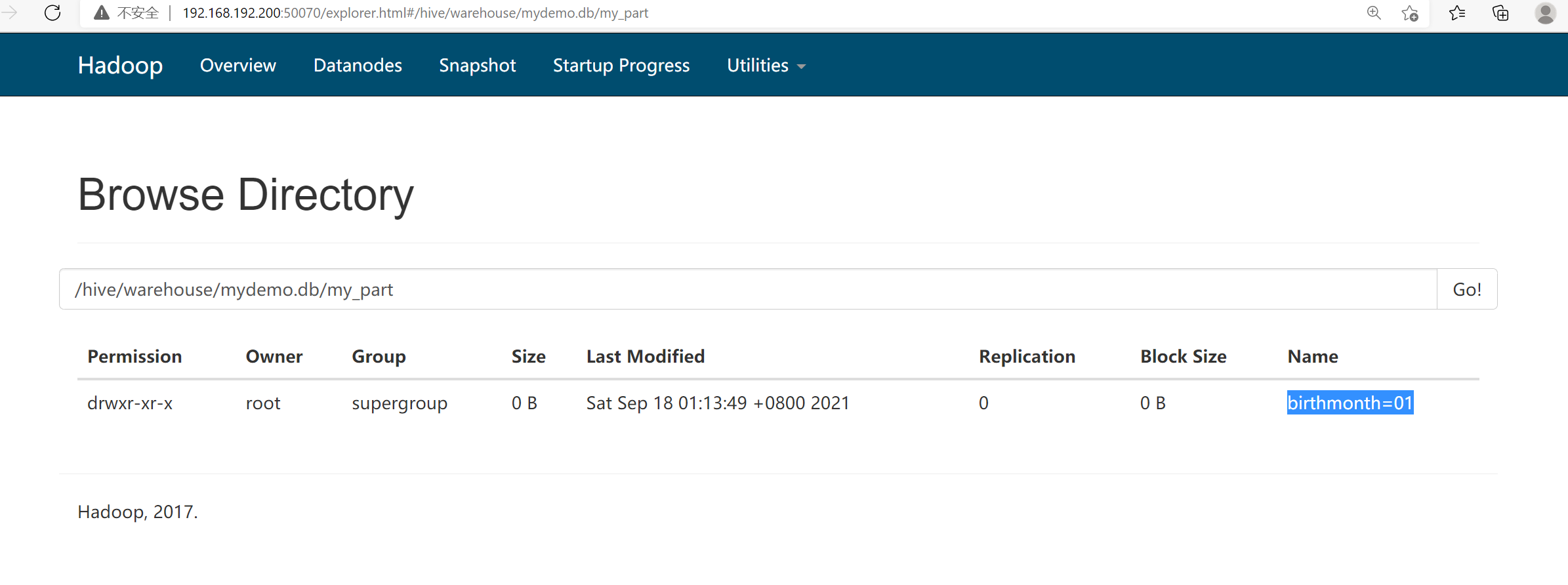
此时去你的50070端口,你会发现在/hive/warehouse/mydemo.db/my_part路径下,为你生成好了一个 ‘birthmonth=01’ 文件夹
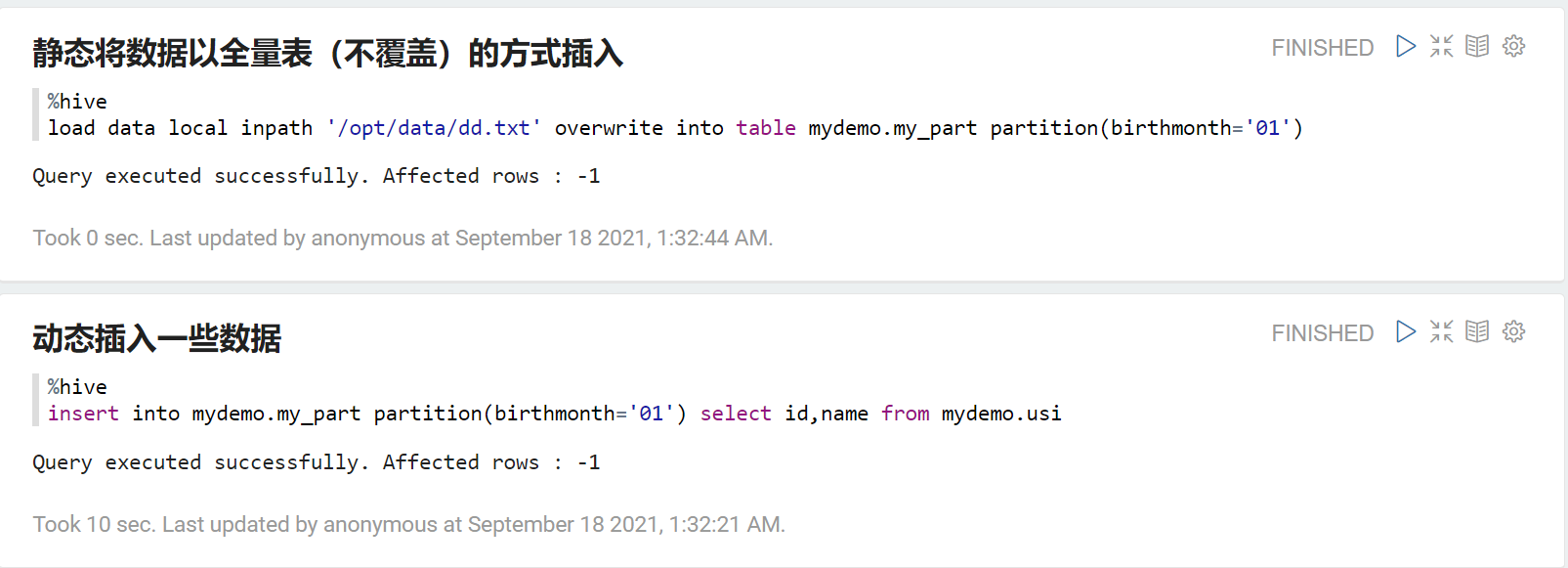
向指定分区里面插入Linux本地的数据文件进去(两种方法 : 静态 和 动态)
(overwrite全量表 : 会覆盖;不加就是增量表: 不会覆盖以前的数据,而是往后进行追加)
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}


