
3.HDFS存储系统
HDFS文件存储系统的构成:
每个block块大小为什么默认是128M?
计算机硬盘吞吐速度为128M左右。(CPU,磁盘,网卡之间的协同效率 即 跨物理机/机架之间文件传输速率)
block块大小设计原则:最小化寻址开销,减少网络传输。
1. 如果块设置过大
第一点: 从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
第二点: mapreduce中的map任务通常一次只处理一个块中的数据,如果块过大运行速度也会很慢。
第三点: 在数据读写计算的时候,需要进行网络传输.如果block过大会导致网络传输时间增长,程序卡顿/超时/无响应. 任务执行的过程中拉取其他节点的block或者失败重试的成本会过高.
第四点: namenode监管容易判断数据节点死亡.导致集群频繁产生/移除副本, 占用cpu,网络,内存资源.
2. 如果块设置过小
第一点: 存放大量小文件会占用NameNode中大量内存来存储元数据,而NameNode的物理内存是有限的;
第二点: 文件块过小,寻址时间增大,导致程序一直在找block的开始位置。
第三点: 操作系统对目录中的小文件处理存在性能问题.比如同一个目录下文件数量操作100万,执行"fs -l "之类的命令会卡死.
第四点: ,则会频繁的进行文件传输,对严重占用网络/CPU资源.
那么为什么是128M?
1.HDFS中,平均寻址时间大概为10ms;
2.经测试发现,寻址时间为传输时间的 1% 时,为最高效状态;10ms/ 0.01 = 1000ms = 1s
3.目前磁盘的传输速率普遍为100MB/s,网卡普遍为千兆传输速率也是100MB/s;
100MB/s X 1s = 100MB
所以最佳默认block大小为128M
4.实际生产中,可以根据集群之间的具体情况进行设置
例如:跨物理机/机架之间文件传输效率为200MB/s时,一般设定block块大小为256MB;文件传输速率为400MB/s时,一般设定block块大小为512MB。最大一般不超过512MB,因为目前固态硬盘的读写速率应该不会超过512MB(RAID另行考虑)
一、NameNode、SecondaryNameNode以及DataNode
1> Namenode(NN):元数据节点 ----> 存储的是目录
一个HDFS集群只有一个活跃的NN。是HDFS主从架构中的master,负责整个文件系统的目录树。
作用:管理的是Block块的元数据信息;
处理客户端的读写请求;
管理Block块的副本放置策略
NameNode被格式化之后,将在Hadoop的/data/tmp/dfs/name/current目录中产生如下文件:
fsimage_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
1、Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户
端执行的所有写操作首先会被记录到Edits文件中。
2、Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包
含HDFS文件系统的所有目录和文件inode的序列化信息。
3、seen_txid文件:保存的是一个数字,就是最后一个edits_的数字。
4、每次NameNode启动的时候都会将Fsimage文件读入内存,加载Edits
里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成
NameNode启动的时候就将Fsimage和Edits文件进行了合并。
edits文件会特别多,namenode会将这些edits传给Secondarynamenode
(理解为秘书),由它来存储并合并,在将合并后的Fsimage文件传回给
namenode。
2> SecondaryNameNode(SNN): 从元数据节点 ----> 相当于Namenode的秘书
接受namenode传来的edits文件按,并每隔一段时间后将他们合并压缩成
一个Fsimage文件,将他传回给Namenode,Namenode需要的时候直接从这
里读取就即可,没有再去读edits文件。
为什么需要一个“秘书”?
NameNode的元数据到底存放在哪里?
首先不可能是磁盘,因为如果存放在磁盘,那么经常操作hdfs,效率会非低,那么就只能会存放内存里。可是,效率虽然快了,但是如果内存满了,或者集群停止服务,那么数据的元数据就会丢失,对于这个问题,HDFS做了一个专门用来解决这个问题的角色,SecondaryNameNode
3> DataNode(DN):数据节点 ----> 真正存储数据并进行备份的地方
保存、检索Block。接收的数据真正存储的地方。一个集群可以有多个数据节点。正常工作中,他一直与namenode进行交互通信,提供自己的本地信息。
4> HDFS的容错机制:
4.1:心跳机制:
在NameNode和DataNode之间维持心跳检测,如果NN没有正常接收到某一个DN的心跳反馈,接下来就不会将任何新的I/O操作派发到那个节点上。同时该节点上的数据也会被认为是无效的,NN就开始检测是否有文件快的副本数目小于设置值,如果小于,就自动开始复制新的副本发送到其他DN节点上。
4.2:检测文件的完整性:
HDFS会记录每个新创建文件的所有储存块的校验和。每当检索这些文件或者从某个节点获取块时,会首先确认校验和是否一致。不一致则代表该块上的数据缺失,便会从其他DataNode节点上获取该块的副本。
4.3:集群的负载均衡:
某时刻如果集群上的某一个节点失效或者增加,可能导致数据分布不均匀,当某个DataNode节点的空闲时间大于一个临界值时,HDFS会自动从其他DataNode迁移数据过来。
4.4:多副本机制:
HDFS会将文件切片成块,再存储至各个DataNode上,文件数据块在HDFS的布局情况由NameNode和hdfs-site.xml中的配置dfs.replication共同决定。dfs.replication表示该文件在HDFS中的副本数,默认为3,即有两份冗余。
二、读写过程
1、HDFS副本机制:
为避免数据丢失,hdfs会创建多个数据的副本,他的存放满足以下特点:
副本默认书为3份。
一个在本地机架节点
一个在同机架不同节点(通过机架感知)
一个在不同机架上的某一节点
如果设置了更多的副本数,其余的副本随机分配,但会尽量避免多份副本在同一节点上
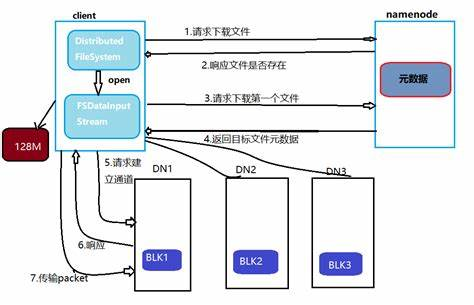
2、读文件
客户端发出请求,传递给DistributedFilesystem,由他向Namenode申请,Namenode获取对应的数据所在块的位置(元数据)。客户端通过这些位置信息,根据就近原则,依靠FSDataInputStream去DataNode上读取相应位置上的文件
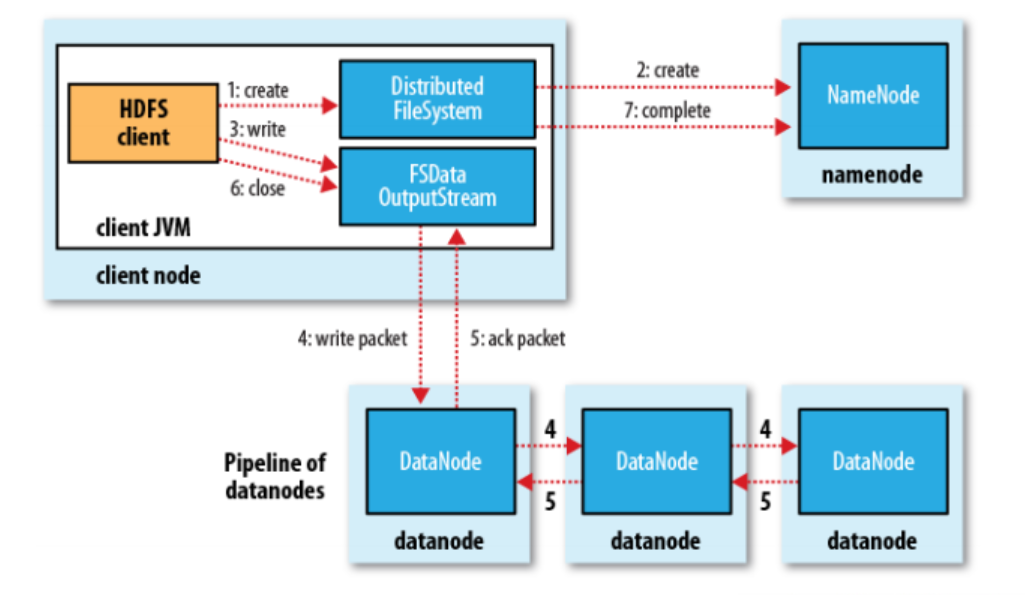
3、写文件
客户端发出请求,传递给DistributedFilesystem,由他向Namenode申请,Namenode先判断文件是否已经存在,并返回给客户端。如果可以上传,再获取距离客户端最接近的节点位置,传递给他,他再返回给客户端;客户端通过这个位置信息,以FSDataOutputStream去在对应的节点上存储数据,存储完成后,通过机架感应,在同机架的另一个节点位置上再写(备份),这一步完成后,再去其他的任意机架上的某一节点,再去备份。这样存储的数据就有三份(副本机制)。
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}


