
1.Hadoop简介以及伪分布式的搭建
Hadoop基本介绍
hadoop是一个框架: hadoop的本质其实就是一系列功能模块儿组成的框架,每个模块分别负责hadoop的一些功能,如HDFS负责大数据的存储功能;Yarn,负责整个集群的资源调度;Common则负责Hadoop远程过程调用的实现以及提供序列化机制。
hadoop具有高容错性,以及高拓展性
hadoop适合处理大数据数据
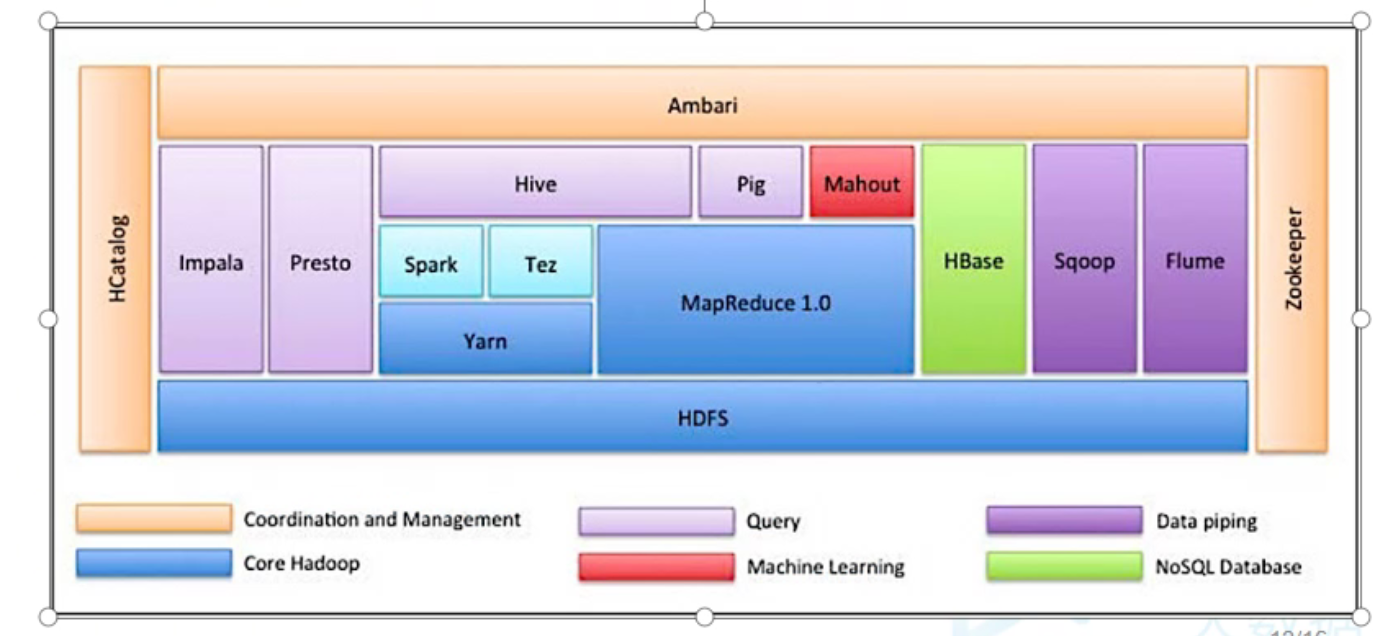
Hadoop生态圈
Centos7单机上搭建Hadoop(伪分布模式)
这里我都放在/opt目录下,创建一个soft文件夹,将Hadoop解压放在下面的hadoop260文件夹中
1、首先将Hadoop的压缩包传到/opt目录下
2、依次在/opt目录下创建soft和hadoop260文件夹,并将hadoop的压缩包解压到这里,去掉一层目录
[root@hadoopsingle opt]# mkdir -p soft/hadoop260 [root@hadoopsingle opt]# tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz -C /opt/soft/hadoop260/ --strip-components 1
3、接下来修改6个配置文件
首先进入到/opt/soft/hadoop260/etc/hadoop这个文件夹,在执行下面的修改
1.修改hadoop-env.sh文件,将jdk配置进去。这个是hadoop启动时的环境脚本
[root@hadoopsingle hadoop]# vim hadoop-env.sh
在下面这个位置,将你jdk的路径填上 # The java implementation to use. export JAVA_HOME=/opt/soft/jdk180
2.修改core-site.xml文件。
[root@hadoopsingle hadoop]# vim core-site.xml 修改如下:汉字为解释 记得删掉!!!!
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
文件系统的对外接口,就填入该单机的IP地址,端口通用9000(比如以后Java连接时的接口)
<name>fs.defaultFS</name>
<value>hdfs://192.168.234.200:9000</value>
</property>
<property>
存储系统临时文件的地方
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop260/tmp</value>
</property>
<property>
将来任何组都可以访问该hadoop系统,只要是root用户的
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
远程访问权限,只要是root用户的
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
任何user都可登录,只要是root用户的
<name>hadoop.proxyuser.root.users</name>
<value>*</value>
</property>
</configuration>
如果不是root用户,就必须到HDFS系统进行授权
3.修改hdfs-site.xml 文件
[root@hadoopsingle hadoop]# vim hdfs-site.xml
添加如下:
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
文件存进来时,备份多少遍。一般为3份,但这里单机模式,就先搞一份
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4.修改文件,首先拷贝一份,拷贝完再修改
[root@hadoopsingle hadoop]# cp mapred-site.xml.template mapred-site.xml [root@hadoopsingle hadoop]# vim mapred-site.xml
添加如下:
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
将mapreduce的调度工作分配给yarn
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.修改yarn-site.xml文件
[root@hadoopsingle hadoop]# vim yarn-site.xml 添加如下: <configuration>
<property>
因为是单机伪分布,所以这里直接写localhost <name>yarn.resourcemanager.localhost</name> <value>localhost</value> </property> <property>
心跳机制-->nodemanager来管理 <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
6.修改/etc/profile文件,配置Hadoop的环境变量
#hadoop environment export HADOOP_HOME=/opt/soft/hadoop260 这里填你自己的Hadoop安装路径 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
修改完记得source生效
注意!!!
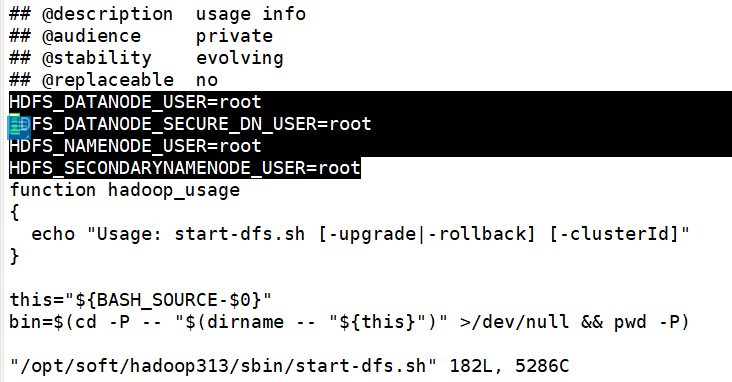
这里我是用的是hadoop的cdh版本,如果使用其他apache高版本,还应修改他的启动和关闭脚本!!!(脚本位置:/opt/soft/hadoop313/sbin/下的start-dfs.sh和stop-dfs.sh)
注意添加位置!!!不要添加到最后!
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_DN_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
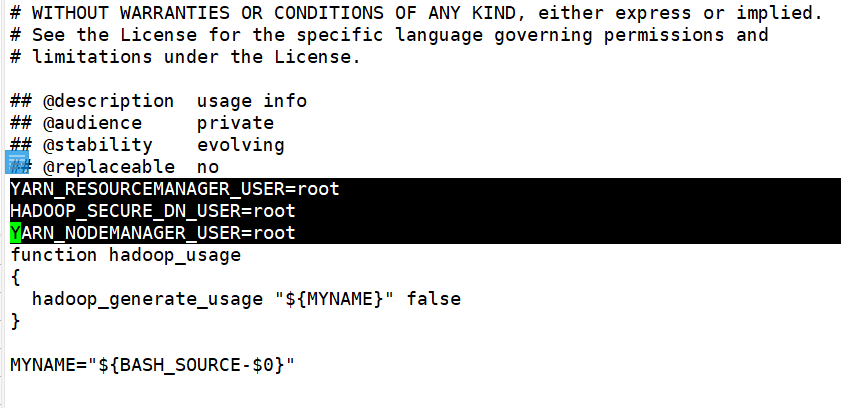
再修改yarn的启动 和关闭脚本:(位置:/opt/soft/hadoop313/sbin/下的start-yarn.sh和stop-tarn.sh)
注意添加位置!!!不要添加到最后!
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=root YARN_NODEMANAGER_USER=root
4、初次启动格式化一下
[root@hadoopsingle hadoop]# hadoop namenode -format 等到最后出现 /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoopSingle/192.168.234.200 ************************************************************/ 格式化完成
5、启动hadoop
[root@hadoopsingle hadoop]# start-all.sh
6、启动完成后查看下进程,如果以下全有,搭建完成。
[root@hadoopsingle hadoop]# jps 20497 SecondaryNameNode 20662 ResourceManager 20951 NodeManager 21015 Jps 20330 DataNode 20205 NameNode
如果这里进程缺少任意一个,按如下步骤查看原因:
[root@hadoopsingle hadoop]# cd /opt/soft/hadoop260/logs/ 首先进入到Hadoop的日志文件夹,缺少哪个进程就查看对应的日志文件,再日志文件最后部分会有错误信息提示 [root@hadoopsingle logs]# ll total 184 -rw-r--r--. 1 root root 27097 Sep 9 02:04 hadoop-root-datanode-hadoopsingle.log -rw-r--r--. 1 root root 716 Sep 9 01:53 hadoop-root-datanode-hadoopsingle.out -rw-r--r--. 1 root root 37768 Sep 9 02:04 hadoop-root-namenode-hadoopsingle.log -rw-r--r--. 1 root root 716 Sep 9 01:53 hadoop-root-namenode-hadoopsingle.out -rw-r--r--. 1 root root 25525 Sep 9 02:04 hadoop-root-secondarynamenode-hadoopsingle.log -rw-r--r--. 1 root root 716 Sep 9 01:53 hadoop-root-secondarynamenode-hadoopsingle.out -rw-r--r--. 1 root root 0 Sep 9 01:53 SecurityAuth-root.audit drwxr-xr-x. 2 root root 6 Sep 9 02:03 userlogs -rw-r--r--. 1 root root 29727 Sep 9 02:05 yarn-root-nodemanager-hadoopsingle.log -rw-r--r--. 1 root root 702 Sep 9 01:53 yarn-root-nodemanager-hadoopsingle.out -rw-r--r--. 1 root root 35633 Sep 9 02:04 yarn-root-resourcemanager-hadoopsingle.log -rw-r--r--. 1 root root 702 Sep 9 01:53 yarn-root-resourcemanager-hadoopsingle.out
7、关闭集群命令
[root@hadoopsingle hadoop]# stop-all.sh
8、配置免密登录
[root@hadoopsingle ~]# jps 1736 Jps [root@hadoopsingle ~]# ssh-keygen -t rsa -P '' 注意引号中间为你设定的密码 空着就行,不要密码 [root@hadoopsingle .ssh]# ssh-copy-id root@hadoopsingle 分发一下密码,这里初次连接,还需要输一次密码。以后就不用了
[root@hadoopsingle .ssh]# ssh hadoopsingle
Last login: Thu Sep 9 16:40:01 2021 from 192.168.234.1 [root@hadoopsingle ~]# exit logout Connection to hadoopsingle closed. 无秘配置完成
接下来分别启动一下: [root@hadoopsingle .ssh]# cd /opt/soft/hadoop260/sbin [root@hadoopsingle sbin]# start-dfs.sh 启动hdfs [root@hadoopsingle sbin]# jps 1953 NameNode 2083 DataNode 2387 Jps 2254 SecondaryNameNode [root@hadoopsingle sbin]# start-yarn.sh 启动yarn [root@hadoopsingle sbin]# jps 1953 NameNode 2083 DataNode 2444 ResourceManager 2893 Jps 2254 SecondaryNameNode 2559 NodeManager
本文来自博客园,作者:{理想三旬},转载请注明原文链接:{https://www.cnblogs.com/zyp0519/}


