https://www.cnblogs.com/zylyehuo/
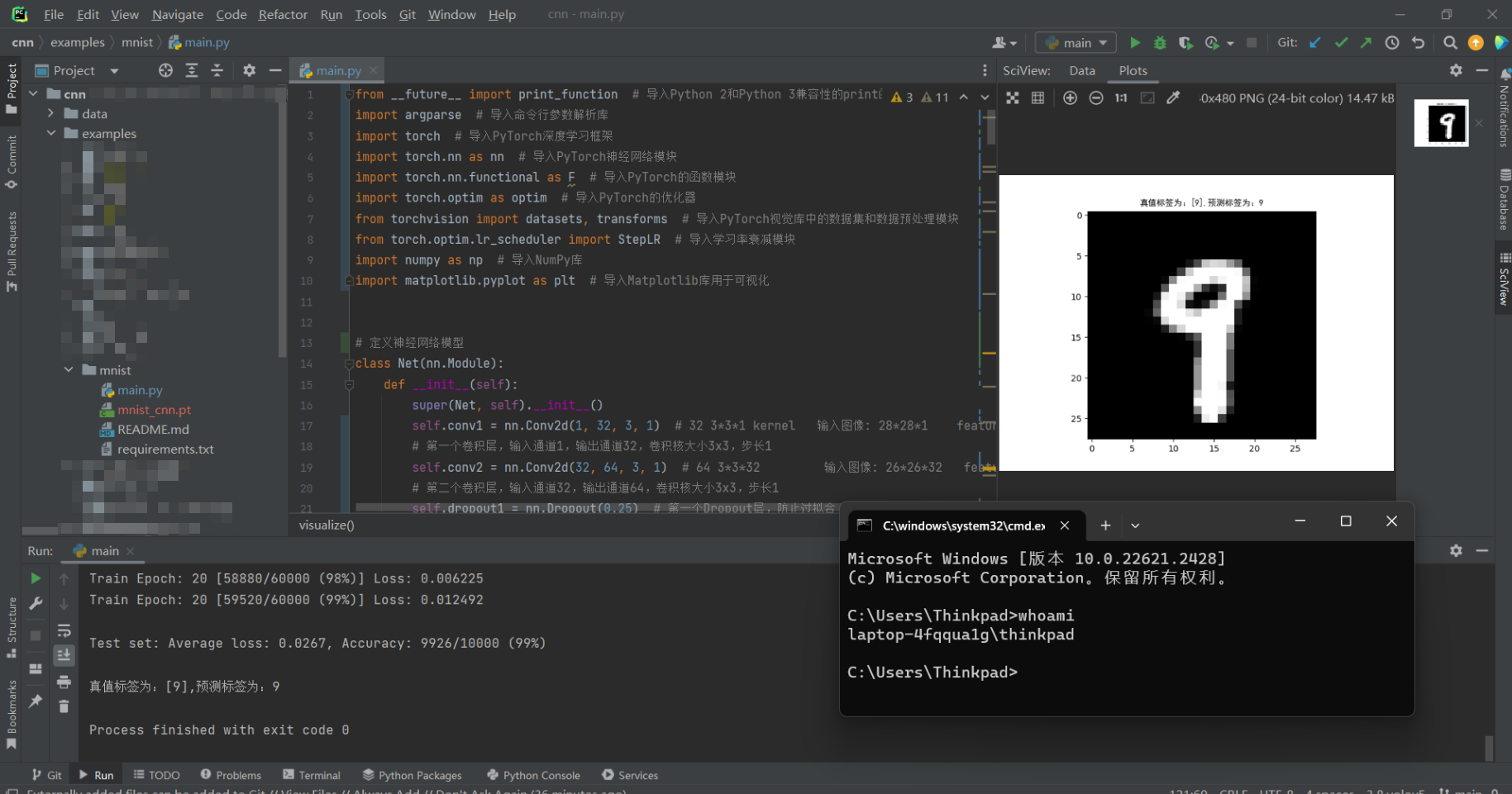
效果展示
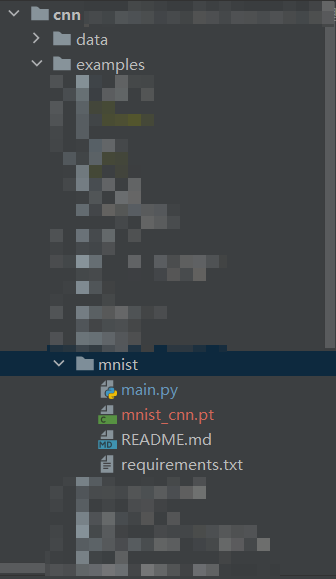
目录结构
README.md
# Basic MNIST Example
pip install -r requirements.txt
python main.py
# CUDA_VISIBLE_DEVICES=2 python main.py # to specify GPU id to ex. 2
requirements.txt
torch
torchvision
main.py
from __future__ import print_function # 导入Python 2和Python 3兼容性的print函数
import argparse # 导入命令行参数解析库
import torch # 导入PyTorch深度学习框架
import torch.nn as nn # 导入PyTorch神经网络模块
import torch.nn.functional as F # 导入PyTorch的函数模块
import torch.optim as optim # 导入PyTorch的优化器
from torchvision import datasets, transforms # 导入PyTorch视觉库中的数据集和数据预处理模块
from torch.optim.lr_scheduler import StepLR # 导入学习率衰减模块
import numpy as np # 导入NumPy库
import matplotlib.pyplot as plt # 导入Matplotlib库用于可视化
# 定义神经网络模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1) # 32 3*3*1 kernel 输入图像: 28*28*1 feature map 26*26*32
# 第一个卷积层,输入通道1,输出通道32,卷积核大小3x3,步长1
self.conv2 = nn.Conv2d(32, 64, 3, 1) # 64 3*3*32 输入图像: 26*26*32 feature map 24*24*64
# 第二个卷积层,输入通道32,输出通道64,卷积核大小3x3,步长1
self.dropout1 = nn.Dropout(0.25) # 第一个Dropout层,防止过拟合
self.dropout2 = nn.Dropout(0.5) # 第二个Dropout层,防止过拟合
self.fc1 = nn.Linear(9216, 128) # 全连接层1,输入维度9216,输出维度128
self.fc2 = nn.Linear(128, 10) # 全连接层2,输入维度128,输出维度10(用于分类0-9数字)
# 前向传播函数
def forward(self, x): # batchsize,h,w,channel
x = self.conv1(x) # 第一个卷积层
x = F.relu(x) # 使用ReLU激活函数
x = self.conv2(x) # 第二个卷积层
x = F.relu(x) # 使用ReLU激活函数
x = F.max_pool2d(x, 2) # feature map h * w 24*24*64 -> 12 * 12 *64
# 最大池化,将特征图大小缩小一半
x = self.dropout1(x) # 应用第一个Dropout层,防止过拟合
x = torch.flatten(x, 1) # dim0 batch size
# 将特征图展平成一维,dim0为批次大小
x = self.fc1(x) # 第一个全连接层
x = F.relu(x) # 使用ReLU激活函数
x = self.dropout2(x) # 应用第二个Dropout层,防止过拟合
x = self.fc2(x) # 第二个全连接层
output = F.log_softmax(x, dim=1) # 使用log_softmax作为输出,用于多类别分类
return output
# 训练函数
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader): # 遍历训练数据集
data, target = data.to(device), target.to(device) # 将数据和目标移到指定设备(GPU或CPU)
optimizer.zero_grad() # 梯度清零,准备计算新一批数据的梯度
output = model(data) # 使用模型前向传播得到预测结果
loss = F.nll_loss(output, target) # 计算交叉熵损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 根据梯度更新模型参数
if batch_idx % args.log_interval == 0: # 每隔一定批次数输出训练状态
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run: # 如果开启了快速检查模式,提前结束训练
break
# 测试函数
def test(model, device, test_loader):
model.eval() # 设置模型为评估模式
test_loss = 0 # 初始化测试损失
correct = 0 # 初始化正确分类的样本数
with torch.no_grad(): # 禁用梯度计算
for data, target in test_loader: # 遍历测试数据集
data, target = data.to(device), target.to(device) # 将数据和目标移到指定设备(GPU或CPU)
output = model(data) # 使用模型前向传播得到预测结果
test_loss += F.nll_loss(output, target, reduction='sum').item() # # 累积损失
pred = output.argmax(dim=1, keepdim=True) # 找到预测的类别
correct += pred.eq(target.view_as(pred)).sum().item() # 统计正确分类的样本数
test_loss /= len(test_loader.dataset) # 计算平均测试损失
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset))) # 打印测试结果,包括平均损失和准确率
# 可视化结果函数
def visualize_results(data, predictions, targets):
image_index = np.random.randint(0, len(data) - 1) # 随机选择一个图像索引
plt.subplot(111) # 创建一个子图
image = data[image_index].cpu().numpy().squeeze() # 获取图像数据并将其转换为NumPy数组
prediction = predictions[image_index].item() # 获取预测的类别
target = targets[image_index].item() # 获取真实标签
plt.imshow(image, cmap='gray') # 显示图像,使用灰度颜色映射
title = f"真值标签为:[{target}],预测标签为:{prediction}" # 创建图像标题
print(title)
plt.title(title, fontproperties='SimHei') # 设置标题并指定字体
plt.show() # 显示图像
def visualize(model, device, test_loader):
model.eval() # 设置模型为评估模式
test_loss = 0 # 初始化测试损失
correct = 0 # 初始化正确分类的样本数
test_data, test_predictions, test_targets = [], [], [] # 初始化用于保存数据、预测和目标的列表
with torch.no_grad(): # 禁用梯度计算
for data, target in test_loader: # 遍历测试数据集
data, target = data.to(device), target.to(device) # 将数据和目标移到指定设备(GPU或CPU)
output = model(data) # 使用模型前向传播得到预测结果
test_loss += F.nll_loss(output, target, reduction='sum').item() # 累积损失
pred = output.argmax(dim=1, keepdim=True) # 找到预测的类别
correct += pred.eq(target.view_as(pred)).sum().item() # 统计正确分类的样本数
# 收集数据、预测和目标
test_data.append(data)
test_predictions.append(pred)
test_targets.append(target)
test_loss /= len(test_loader.dataset) # 计算平均测试损失
# V可视化结果
test_data = torch.cat(test_data, dim=0) # 拼接所有数据
test_predictions = torch.cat(test_predictions, dim=0) # 拼接所有预测
test_targets = torch.cat(test_targets, dim=0) # 拼接所有目标
visualize_results(test_data, test_predictions, test_targets) # 调用可视化函数
def visual():
use_cuda = torch.cuda.is_available() # 检查是否可用CUDA
use_mps = False # 暂时禁用 macOS GPU 支持
# 根据CUDA和 macOS GPU 支持选择设备
if use_cuda:
device = torch.device("cuda")
elif use_mps:
device = torch.device("mps")
else:
device = torch.device("cpu")
# 设置测试数据加载参数
test_kwargs = {'batch_size': 64}
# 如果使用CUDA,设置CUDA加载参数
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
# 更新测试数据加载参数以包括CUDA参数
test_kwargs.update(cuda_kwargs)
# 数据预处理:将图像数据转换为张量并进行标准化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 创建测试数据集
dataset = datasets.MNIST('../data', train=False,
transform=transform) # list
# 创建测试数据加载器
test_loader = torch.utils.data.DataLoader(dataset, **test_kwargs)
# 定义模型文件路径
model_path = "mnist_cnn.pt"
# 加载模型
model = Net()
model.load_state_dict(torch.load(model_path))
# 将模型移动到选择的设备上
model.to(device)
# 调用可视化函数
visualize(model, device, test_loader)
# 主函数
def main():
# 训练参数设置
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
# 输入训练批次大小(默认:64)
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
# 输入测试批次大小(默认:1000)
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
# 训练的时期数(默认:20)
parser.add_argument('--epochs', type=int, default=20, metavar='N',
help='number of epochs to train (default: 14)')
# 学习率(默认:1.0)
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
# 学习率步长衰减因子(默认:0.7)
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
# 禁用CUDA训练
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
# 禁用macOS GPU训练
parser.add_argument('--no-mps', action='store_true', default=False,
help='disables macOS GPU training')
# 快速检查一次
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
# 随机种子(默认:1)
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
# 设置多少批次后记录训练状态
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
# 设置是否保存训练模型
parser.add_argument('--save-model', action='store_true', default=True,
help='For Saving the current Model')
args = parser.parse_args() # 解析命令行参数
# 检查是否使用CUDA(GPU),以及是否可用
use_cuda = not args.no_cuda and torch.cuda.is_available()
# 暂时不使用 macOS GPU
use_mps = False # not args.no_mps and torch.backends.mps.is_available()
# 设置随机种子
torch.manual_seed(args.seed)
# 根据CUDA和MPS的可用性选择设备
if use_cuda:
device = torch.device("cuda")
elif use_mps:
device = torch.device("mps")
else:
device = torch.device("cpu")
# 定义训练和测试数据集的批处理参数
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
# 如果使用CUDA,配置相应的参数
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
# 数据预处理和加载
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 训练数据集
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
# 测试数据集
dataset2 = datasets.MNIST('../data', train=False,
transform=transform) # list
# 创建训练和测试数据加载器
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
# 创建神经网络模型并将其移到所选设备
model = Net().to(device)
# 配置优化器
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
# 设置学习率衰减策略
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
# 开始训练循环
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
# 保存训练好的模型
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
if __name__ == '__main__':
main() # 训练、测试模型函数
visual() # 可视化函数