第二十节、基于传统图像处理的目标检测与识别(词袋模型BOW+SVM附代码)
在上一节、我们已经介绍了使用HOG和SVM实现目标检测和识别,这一节我们将介绍使用词袋模型BOW和SVM实现目标检测和识别。
一 词袋介绍
词袋模型(Bag-Of-Word)的概念最初不是针对计算机视觉的,但计算机视觉会使用该概念的升级。词袋最早出现在神经语言程序学(NLP)和信息检索(IR)领域,该模型忽略掉文本的语法和语序,用一组无序的单词来表达一段文字或者一个文档。
我们使用BOW在一系列文档中构建一个字典,然后使用字典中每个单词次数构成向量来表示每一个文档。比如:
- 文档1:I like OpenCV and I like Python;
- 文档2:I like C++ and Python;
- 文档3:I don't like artichokes;
对于这三个文档,我们建立如下的字典:
dic = {1:'I',
2:'like',
3:'OpenCV',
4:'and',
5:'Python',
6:'C++',
7:'don\'t',
8:'artichokes'}
该字典一共有8项。使用这8项构成的向量来表示每个文档,每个向量包含字典中的所有单词,向量的每个元素表示文档中每个单词出现的次数。则上面三个文档可以使用如下向量来表示:
[2,2,1,1,1,0,0,0]
[1,1,0,1,1,1,0,0]
[1,1,0,0,0,0,1,1]
每一个向量都可以看做是一个文档的直方图表示或被当做特征,这些特征可以用来训练分类器。在实际中,也有许多有效地应用,比如垃圾邮箱过滤。
二 计算机视觉中的BOW
与应用到文本的BOW模型类比,我们可以把BOW模型应用到计算机视觉,我们把图像的特征当做单词,把图像“文字化”之后,有助于大规模的图像检索。
1、BOW基本步骤
- 特征提取:提取数据集中每幅图像的特征点,然后提取特征描述符,形成特征数据(如:SIFT或者SURF方法);
- 学习词袋:把处理好的特征数据全部合并,利用聚类把特征词分为若干类,此若干类的数目由自己设定,每一类相当于一个视觉词汇;
- 利用视觉词袋量化图像特征:每一张图像由很多视觉词汇组成,我们利用统计的词频直方图,可以表示图像属于哪一类;
这个过程需要获取视觉词汇(visual word)字典,从一定程度上来说,词汇越多越好,因此我们需要的数据集也相应的越大越好;
2、BOW可视化
下面我们来对BOW过程进行可视化,
- 假设我们有三个目标类,分别是人脸、自行车和吉他。首先从图像中提取出相互独立的视觉词汇(假设使用SIFT方法):

通过观察会发现,同一类目标的不同实例之间虽然存在差异,但我们仍然可以找到它们之间的一些共同的地方,比如说人脸,虽然说不同人的脸差别比较大,但眼睛,嘴,鼻子等一些比较细小的部位,却观察不到太大差别,我们可以把这些不同实例之间共同的部位提取出来,作为识别这一类目标的视觉词汇。
- 将所有的视觉词汇集合在一起:

- 利用K-means算法构造词汇字典。K-means算法是一种基于样本间相似性度量的间接聚类方法,此算法以$k$为参数,把$n$个对象分为$k$个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT算法提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为词汇字典中的基础词汇,假定我们将$k$设为4,那么词汇字典的构建过程如下:

- 利用词汇字典的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用词汇字典中的词汇近似代替,通过统计词汇字典中每个词汇在图像中出现的次数,可以将图像表示成为一个$k=4$维数值向量:

上图中,我们从人脸、自行车和吉他三个目标类图像中提取出的不同视觉词汇,而构造的词汇字典中,会把词义相近的视觉词汇合并为同一类,经过合并,词汇表中只包含了四个视觉词汇,分别按索引值标记为1,2,3,4。通过观察可以看到,它们分别属于自行车、人脸、吉他、人脸类。统计这些词汇在不同目标类中出现的次数可以得到每幅图像的直方图表示(我们假定存在误差,实际情况亦不外如此):
人脸: [3,30,3,20] 自行车:[20,3,3,2] 吉他: [8,12,32,7]
其实这个过程非常简单,就是针对人脸、自行车和吉他这三个文档,抽取出相似的部分(或者词义相近的视觉词汇合并为同一类),构造一个字典,字典中包含4个视觉单词,即:
dic = {1:'自行车',
2:'人脸',
3:'吉他',
4:'人脸类'}
最终人脸、自行车和吉他这三个文档皆可以用一个4维向量表示,最后根据三个文档相应部分出现的次数绘制对应的直方图。
需要说明的是,以上过程只是针对三个目标类非常简单的一个示例,实际应用中,为了达到较好的效果,单词表中的词汇数量$k$往往非常庞大,并且目标类数目越多,对应的$k$值也越大,一般情况下,$k$的取值在几百到上千,在这里取$k=4$仅仅是为了方便说明。
三 目标识别
对于图像和视频检测中的目标类型没有具体限制,但是为了使结果的准确度在可以接收的范围内,需要一个足够大的数据集,包括训练图像的大小尽量也一样。
如果自己构建数据集将会花费较长的时间,因此,在这里我们利用现成的数据集,在网上可以下载这样的数据集,这里我们使用猫和狗的数据集:
https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/data


训练集一共包含25000张照片,其中一半是狗(正样本),一半是猫(负样本),在这里我们就使用其中的部分数据集,训练一个二分类器;
- 首先我们选取一定数量的正负样本(这里选择的为10,没有选择全部样本是因为数据量大,计算速度就会很慢,而且该数值小一些有时候效果会更好),然后使用SIFT算法提取特征数据,并使用聚类分类(k=40),形成词汇字典;
- 选取更多正负样本数据集(这里选择的是400),利用视觉词袋(即词汇字典)量化每一个样本特征,并使用SVM进行训练;
- 对100个样本进行测试;
代码如下:
# -*- coding: utf-8 -*- """ Created on Wed Oct 17 09:38:26 2018 @author: zy """ ''' 词袋模型BOW+SVM 目标识别 以狗和猫数据集二分类为例 如果是狗 返回True 如果是猫 返回False ''' import numpy as np import cv2 class BOW(object): def __init__(self,): #创建一个SIFT对象 用于关键点提取 self.feature_detector = cv2.xfeatures2d.SIFT_create() #创建一个SIFT对象 用于关键点描述符提取 self.descriptor_extractor = cv2.xfeatures2d.SIFT_create() def path(self,cls,i): ''' 用于获取图片的全路径 ''' return '%s/%s/%s.%d.jpg'%(self.train_path,cls,cls,i+1) def fit(self,train_path,k): ''' 开始训练 args: train_path:训练集图片路径 我们使用的数据格式为 train_path/dog/dog.i.jpg train_path/cat/cat.i.jpg k:k-means参数k ''' self.train_path = train_path #FLANN匹配 参数algorithm用来指定匹配所使用的算法,可以选择的有LinearIndex、KTreeIndex、KMeansIndex、CompositeIndex和AutotuneIndex,这里选择的是KTreeIndex(使用kd树实现最近邻搜索) flann_params = dict(algorithm=1,tree=5) flann = cv2.FlannBasedMatcher(flann_params,{}) #创建BOW训练器,指定k-means参数k 把处理好的特征数据全部合并,利用聚类把特征词分为若干类,此若干类的数目由自己设定,每一类相当于一个视觉词汇 bow_kmeans_trainer = cv2.BOWKMeansTrainer(k) pos = 'dog' neg = 'cat' #指定用于提取词汇字典的样本数 length = 10 #合并特征数据 每个类从数据集中读取length张图片(length个狗,length个猫),通过聚类创建视觉词汇 for i in range(length): bow_kmeans_trainer.add(self.sift_descriptor_extractor(self.path(pos,i))) bow_kmeans_trainer.add(self.sift_descriptor_extractor(self.path(neg,i))) #进行k-means聚类,返回词汇字典 也就是聚类中心 voc = bow_kmeans_trainer.cluster() #输出词汇字典 <class 'numpy.ndarray'> (40, 128) print(type(voc),voc.shape) #初始化bow提取器(设置词汇字典),用于提取每一张图像的BOW特征描述 self.bow_img_descriptor_extractor = cv2.BOWImgDescriptorExtractor(self.descriptor_extractor,flann) self.bow_img_descriptor_extractor.setVocabulary(voc) #创建两个数组,分别对应训练数据和标签,并用BOWImgDescriptorExtractor产生的描述符填充 #按照下面的方法生成相应的正负样本图片的标签 1:正匹配 -1:负匹配 traindata,trainlabels = [],[] for i in range(400): #这里取200张图像做训练 traindata.extend(self.bow_descriptor_extractor(self.path(pos,i))) trainlabels.append(1) traindata.extend(self.bow_descriptor_extractor(self.path(neg,i))) trainlabels.append(-1) #创建一个SVM对象 self.svm = cv2.ml.SVM_create() #使用训练数据和标签进行训练 self.svm.train(np.array(traindata),cv2.ml.ROW_SAMPLE,np.array(trainlabels)) def predict(self,img_path): ''' 进行预测样本 ''' #提取图片的BOW特征描述 data = self.bow_descriptor_extractor(img_path) res = self.svm.predict(data) print(img_path,'\t',res[1][0][0]) #如果是狗 返回True if res[1][0][0] == 1.0: return True #如果是猫,返回False else: return False def sift_descriptor_extractor(self,img_path): ''' 特征提取:提取数据集中每幅图像的特征点,然后提取特征描述符,形成特征数据(如:SIFT或者SURF方法); ''' im = cv2.imread(img_path,0) return self.descriptor_extractor.compute(im,self.feature_detector.detect(im))[1] def bow_descriptor_extractor(self,img_path): ''' 提取图像的BOW特征描述(即利用视觉词袋量化图像特征) ''' im = cv2.imread(img_path,0) return self.bow_img_descriptor_extractor.compute(im,self.feature_detector.detect(im)) if __name__ == '__main__': #测试样本数量,测试结果 test_samples = 100 test_results = np.zeros(test_samples,dtype=np.bool) #训练集图片路径 狗和猫两类 进行训练 train_path = './data/cat_and_dog/data/train' bow = BOW() bow.fit(train_path,40) #指定测试图像路径 for index in range(test_samples): dog = './data/cat_and_dog/data/train/dog/dog.{0}.jpg'.format(index) dog_img = cv2.imread(dog) #预测 dog_predict = bow.predict(dog) test_results[index] = dog_predict #计算准确率 accuracy = np.mean(test_results.astype(dtype=np.float32)) print('测试准确率为:',accuracy) #可视化最后一个 font = cv2.FONT_HERSHEY_SIMPLEX if test_results[0]: cv2.putText(dog_img,'Dog Detected',(10,30),font,1,(0,255,0),2,cv2.LINE_AA) cv2.imshow('dog_img',dog_img) cv2.waitKey(0) cv2.destroyAllWindows()
运行结果如下:


四 目标检测
在上面我们已经初步完成了目标识别,但是还有个问题我们没有解决,假设一张图中有多个目标,我们有时候需要定位到每个目标的具体位置。要想做到这一点,我们需要使用滑动窗口的方法,对每一个候选区域进行目标识别,具体步骤如下:

- 给定一张图像28×28×3 的图片应用滑动窗口操作,以 14×14 区域滑动窗口,从左到右移动,从上到下移动,对于每得到的一个滑动区域,使用BOW训练很好的SVM进行分类;
- 把每个滑动区域的预测结果保存下来;
- 完成整个图像的分类后,缩放图像并重复整个滑动窗口的过程;
- 继续对图像进行缩放和分类,直至缩放到最小尺寸才停止;
在这个阶段,已经收集了图像内容的重要信息。然而,还有一个问题:很可能检测是以许多评分为正数的重叠块结束。这意味着图像中可能包含被检测四五次的对象,如果将这些作为检测结果,那么这个结果是相当不准确的,因此需要使用非极大值抑制解决这个问题。
以人脸检测为例,我们从网上搜集到10000张大小为96×96的人脸图片,以及从一些图片中随机裁切到的10000张大小为96×96非人脸图片:


有了训练集之后,要想训练一个人脸检测的检测器,还需要包含以下步骤:
- 创建一个bow训练器,并利用k-means聚类获取视觉字典;
- 利用视觉词袋(即词汇字典)量化每一个样本特征,然后训练SVM分类器;
- 尝试对测试图像的图像金字塔采用滑动窗口检测;
- 对重叠的边界框采用非极大值抑制;
- 输出结果;
该项目主要包含以下几个文件:
- pyramid.py:主要用来生成图像金字塔,以及在每个图像金字塔上进行滑动窗口;
- detector.py:主要用来获取获取视觉字典,以及训练SVM分类器;
- non_max_suppression.py:对检测到的边界框进行非极大值抑制;
- test.py:主程序,用来训练SVM分类器,并对测试图像的图像金字塔采用滑动窗口检测;
pyramid.py代码如下:
# -*- coding: utf-8 -*- """ Created on Thu Oct 18 10:13:46 2018 @author: zy """ ''' 图像金字塔 ''' import numpy as np import cv2 def resize(img,scale_factor): ''' 对图像进行缩放 args: img:输入图像 scale_factor:缩放因子 缩小scale_factor>1 ''' ret = cv2.resize(img,(int(img.shape[1]*(1.0/scale_factor)),int(img.shape[0]*(1.0/scale_factor))), interpolation=cv2.INTER_AREA) return ret def pyramid(img,scale=1.5,min_size=(200,200)): ''' 图像金字塔 对图像进行缩放,这是一个生成器 args: img:输入图像 scale:缩放因子 min_size:图像缩放的最小尺寸 (w,h) ''' yield img while True: img = resize(img,scale) if img.shape[0] < min_size[1] or img.shape[1] < min_size[0]: break yield img def silding_window(img,stride,window_size): ''' 滑动窗口函数,给定一张图像,返回一个从左到右滑动的窗口,直至覆盖整个图像的宽度,然后回到左边界 继续下一个步骤,直至覆盖图像的宽度,这样反复进行,直至到图像的右下角 args: img:输入图像 stride:滑动步长 标量 widow_size:(w,h) 一定不能大于img大小 return: 返回滑动窗口:x,y,滑动区域图像 ''' for y in range(0,img.shape[0]-window_size[1],stride): for x in range(0,img.shape[1]-window_size[0],stride): yield (x,y,img[y:y+window_size[1],x:x+window_size[0]])
non_max_suppression.py文件如下:
# -*- coding: utf-8 -*- """ Created on Thu Oct 18 13:37:42 2018 @author: zy """ import numpy as np ''' 非极大值抑制 https://blog.csdn.net/hongxingabc/article/details/78996407 1、按打分最高到最低将BBox排序 ,例如:A B C D E F 2、A的分数最高,保留,从B-E与A分别求重叠率IoU,假设B、D与A的IoU大于阈值, 那么B和D可以认为是重复标记去除 3、余下C E F,重复前面两步 ''' def nms(boxes,threshold): ''' 对边界框进行非极大值抑制 args: boxes:边界框,数据为list类型,形状为[n,5] 5位表示(x1,y1,x2,y2,score) threshold:IOU阈值 大于该阈值,进行抑制 ''' if len(boxes) == 0: return [] x1 = boxes[:,0] y1 = boxes[:,1] x2 = boxes[:,2] y2 = boxes[:,3] scores = boxes[:,4] #计算边界框区域大小,并按照score进行倒叙排序 areas = (x2-x1 + 1)*(y2-y1 + 1) idxs = np.argsort(scores)[::-1] #keep为最后保留的边框 keep = [] while len(idxs) > 0: #idxs[0]是当前分数最大的窗口,肯定保留 i = idxs[0] keep.append(i) #计算窗口i与其他所有窗口的交叠部分的面积 xx1 = np.maximum(x1[i], x1[idxs[1:]]) yy1 = np.maximum(y1[i], y1[idxs[1:]]) xx2 = np.minimum(x2[i], x2[idxs[1:]]) yy2 = np.minimum(y2[i], y2[idxs[1:]]) w = np.maximum(0.0, xx2 - xx1 + 1) h = np.maximum(0.0, yy2 - yy1 + 1) inter = w * h #交/并得到iou值 ovr = inter / (areas[i] + areas[idxs[1:]] - inter) #inds为所有与窗口i的iou值小于threshold值的窗口的index,其他窗口此次都被窗口i吸收 inds = np.where(ovr <= threshold)[0] #order里面只保留与窗口i交叠面积小于threshold的那些窗口,由于ovr长度比order长度少1(不包含i),所以inds+1对应到保留的窗口 idxs = idxs[inds + 1] return boxes[keep]
detector.py文件如下:
# -*- coding: utf-8 -*- """ Created on Thu Oct 18 14:59:09 2018 @author: zy """ ''' 词袋模型BOW+SVM 目标检测 ''' import numpy as np import cv2 import pickle import os class BOW(object): def __init__(self,): #创建一个SIFT对象 用于关键点提取 self.feature_detector = cv2.xfeatures2d.SIFT_create() #创建一个SIFT对象 用于关键点描述符提取 self.descriptor_extractor = cv2.xfeatures2d.SIFT_create() def fit(self,files,labels,k,length=None): ''' 开始训练 可以用于多分类 args: files:训练集图片路径 list类型 [['calss0-1','calss0-2','calss0-3','class0-4',...] ['calss1-1','calss1-2','calss1-3','class1-4',...] ['calss2-1','calss2-2','calss2-3','class2-4',...] ['calss3-1','calss3-2','calss3-3','class3-4',...] ...] labes:对应的每个样本的标签 [[0,0,0,0]... [1,1,1,1]... [2,2,2,2]... [3,3,3,3]... ...] k:k-means参数k length:指定用于训练词汇字典的样本长度 ''' #类别数 classes = len(files) #样本数量 samples = len(files[0]) if length is None: length = samples elif length > samples: length = samples #FLANN匹配 参数algorithm用来指定匹配所使用的算法,可以选择的有LinearIndex、KTreeIndex、KMeansIndex、CompositeIndex和AutotuneIndex,这里选择的是KTreeIndex(使用kd树实现最近邻搜索) flann_params = dict(algorithm=1,tree=5) flann = cv2.FlannBasedMatcher(flann_params,{}) #创建BOW训练器,指定k-means参数k 把处理好的特征数据全部合并,利用聚类把特征词分为若干类,此若干类的数目由自己设定,每一类相当于一个视觉词汇 bow_kmeans_trainer = cv2.BOWKMeansTrainer(k) print('building BOWKMeansTrainer...') #合并特征数据 每个类从数据集中读取length张图片,通过聚类创建视觉词汇 for j in range(classes): for i in range(length): #有一些图像会抛异常,主要是因为该图片没有sift描述符 descriptor = self.sift_descriptor_extractor(files[j][i]) if not descriptor is None: bow_kmeans_trainer.add(descriptor) #print('error:',files[j][i]) #进行k-means聚类,返回词汇字典 也就是聚类中心 self.voc = bow_kmeans_trainer.cluster() #输出词汇字典 <class 'numpy.ndarray'> (40, 128) print(type(self.voc),self.voc.shape) #初始化bow提取器(设置词汇字典),用于提取每一张图像的BOW特征描述 self.bow_img_descriptor_extractor = cv2.BOWImgDescriptorExtractor(self.descriptor_extractor,flann) self.bow_img_descriptor_extractor.setVocabulary(self.voc) print('adding features to svm trainer...') #创建两个数组,分别对应训练数据和标签,并用BOWImgDescriptorExtractor产生的描述符填充 #按照下面的方法生成相应的正负样本图片的标签 traindata,trainlabels = [],[] for j in range(classes): for i in range(samples): descriptor = self.bow_descriptor_extractor(files[j][i]) if not descriptor is None: traindata.extend(descriptor) trainlabels.append(labels[j][i]) #创建一个SVM对象 self.svm = cv2.ml.SVM_create() self.svm.setType(cv2.ml.SVM_C_SVC) self.svm.setGamma(0.5) self.svm.setC(30) self.svm.setKernel(cv2.ml.SVM_RBF) #使用训练数据和标签进行训练 self.svm.train(np.array(traindata),cv2.ml.ROW_SAMPLE,np.array(trainlabels)) def save(self,path): ''' 保存模型到指定路径 ''' print('saving model....') #保存svm模型 self.svm.save(path) #保存bow模型 f1 = os.path.join(os.path.dirname(path),'dict.pkl') with open(f1,'wb') as f: pickle.dump(self.voc,f) def load(self,path): ''' 加载模型 ''' print('loading model....') #加载svm模型 self.svm = cv2.ml.SVM_load(path) #加载bow模型 f1 = os.path.join(os.path.dirname(path),'dict.pkl') with open(f1,'rb') as f: voc = pickle.load(f) #FLANN匹配 参数algorithm用来指定匹配所使用的算法,可以选择的有LinearIndex、KTreeIndex、KMeansIndex、CompositeIndex和AutotuneIndex,这里选择的是KTreeIndex(使用kd树实现最近邻搜索) flann_params = dict(algorithm=1,tree=5) flann = cv2.FlannBasedMatcher(flann_params,{}) #初始化bow提取器(设置词汇字典),用于提取每一张图像的BOW特征描述 self.bow_img_descriptor_extractor = cv2.BOWImgDescriptorExtractor(self.descriptor_extractor,flann) self.bow_img_descriptor_extractor.setVocabulary(voc) def predict(self,img): ''' 进行预测样本 args: img:图像数据 args: label:样本所属类别标签,和训练输入标签值一致 score:置信度 分数越低,置信度越高,表示属于该类的概率越大 ''' #转换为灰色 if len(img.shape) == 3: img = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY) #提取图片的BOW特征描述 #data = self.bow_descriptor_extractor(img_path) keypoints = self.feature_detector.detect(img) if keypoints: data = self.bow_img_descriptor_extractor.compute(img,keypoints) _,result = self.svm.predict(data) #所属标签 label = result[0][0] #设置标志位 获取预测的评分 分数越低,置信度越高,表示属于该类的概率越大 a,res = self.svm.predict(data,flags=cv2.ml.STAT_MODEL_RAW_OUTPUT) score = res[0][0] #print('Label:{0} Score:{1}'.format(label,score)) return label,score else: return None,None def sift_descriptor_extractor(self,img_path): ''' 特征提取:提取数据集中每幅图像的特征点,然后提取特征描述符,形成特征数据(如:SIFT或者SURF方法); args: img_path:图像全路径 ''' im = cv2.imread(img_path,0) keypoints = self.feature_detector.detect(im) if keypoints: return self.descriptor_extractor.compute(im,keypoints)[1] else: return None def bow_descriptor_extractor(self,img_path): ''' 提取图像的BOW特征描述(即利用视觉词袋量化图像特征) args: img_path:图像全路径 ''' im = cv2.imread(img_path,0) keypoints = self.feature_detector.detect(im) if keypoints: return self.bow_img_descriptor_extractor.compute(im,keypoints) else: return None
test.py主程序代码如下:
# -*- coding: utf-8 -*- """ Created on Thu Oct 18 15:16:20 2018 @author: zy """ ''' 使用BOW+SVM进行滑动窗口目标检测 可以分类 ''' import cv2 import numpy as np from detector import BOW from pyramid import pyramid,silding_window from non_max_suppression import nms import os def prepare_data(rootpath,samples): ''' 加载数据集 args: rootpath:数据集所在的根目录 要求在该路径下,存放数据,每一类使用一个文件夹存放,文件名即为类名 sample:指定获取的每一类样本长度 return: train_path:训练集路径 list类型 [['calss0-1','calss0-2','calss0-3','class0-4',...] ['calss1-1','calss1-2','calss1-3','class1-4',...] ['calss2-1','calss2-2','calss2-3','class2-4',...] ['calss3-1','calss3-2','calss3-3','class3-4',...] labels:每一个样本类别标签 list类型 [[0,0,0,0]... [1,1,1,1]... [2,2,2,2]... [3,3,3,3]... ...] classes:每一个类别对应的名字 lst类型 ''' files = [] labels = [] #获取rootpath下的所有文件夹 classes = [x for x in os.listdir(rootpath) if os.path.isdir(os.path.join(rootpath,x))] #遍历每个类别样本 for idx in range(len(classes)): #获取当前类别文件所在文件夹的全路径 path = os.path.join(rootpath,classes[idx]) #遍历每一个文件路径 filelist = [os.path.join(path,x) for x in os.listdir(path) if os.path.isfile(os.path.join(path,x))] #追加到字典 files.append(filelist[:samples]) labels.append([idx]*samples) return files,labels,classes if __name__ == '__main__': ''' 1、训练或者直接加载训练好的模型 ''' #训练? is_training = False bow = BOW() if is_training: #样本个数 越大,训练准确率相对越高 samples = 5000 #根路径 rootpath = '../data/face/train' #训练集图片路径 files,labels,classes = prepare_data(rootpath,samples) #k越大,训练准确率相对越高 bow.fit(files,labels,1000,samples//5) #保存模型 bow.save('./svm.mat') else: #加载模型 bow.load('./svm.mat') ''' 2、测试计算目标识别的准确率 ''' #测试样本数量,测试结果 start_index = 5000 test_samples = 1000 test_results = [] #指定测试图像路径 #根路径 rootpath = '../data/face/train' #训练集图片路径 files,labels,classes = prepare_data(rootpath,6000) for j in range(len(files)): for i in range(start_index,start_index+test_samples): #预测 img = cv2.imread(files[j][i]) label,score = bow.predict(img) if label is None: continue #print(files[j][i],label,labels[j][i]) if label == labels[j][i]: test_results.append(True) else: test_results.append(False) test_results = np.asarray(test_results,dtype=np.float32) #计算准确率 accuracy = np.mean(test_results) print('测试准确率为:',accuracy) ''' 3、利用滑动窗口进行目标检测 ''' #滑动窗口大小 w,h = 72,72 test_img = './3.jpg' img = cv2.imread(test_img) rectangles = [] counter = 1 scale_factor = 1.2 font = cv2.FONT_HERSHEY_PLAIN #label,score = bow.predict(img[50:280,100:280]) #print('预测:',label,score) #图像金字塔 for resized in pyramid(img.copy(),scale_factor,(img.shape[1]//2,img.shape[1]//2)): print(resized.shape) #图像缩小倍数 scale = float(img.shape[1])/float(resized.shape[1]) #遍历每一个滑动区域 for (x,y,roi) in silding_window(resized,10,(w,h)): if roi.shape[1] != w or roi.shape[0] != h: continue try: label,score = bow.predict(roi) #识别为人 if label == 1: #得分越小,置信度越高 if score < -1: #print(label,score) #获取相应边界框的原始大小 rx,ry,rx2,ry2 = x*scale,y*scale,(x+w)*scale,(y+h)*scale rectangles.append([rx,ry,rx2,ry2,-1.0*score]) except: pass counter += 1 windows = np.array(rectangles) boxes = nms(windows,0.15) for x,y,x2,y2,score in boxes: cv2.rectangle(img,(int(x),int(y)),(int(x2),int(y2)),(0,0,255),1) cv2.putText(img,'%f'%score,(int(x),int(y)),font,1,(0,255,0)) cv2.imshow('img',img) cv2.waitKey(0) cv2.destroyAllWindows()
当我们把is_training设置为True时,则采用5000张正样本和5000负样本训练词汇字典和SVM分类器,然后使用第5000~6000张图像作为测试数据,获取分类器的准确率,由于训练时间较长,我已经把模型训练好了,并分别保存在以下文件中:
- dict.pkl:保存BOWKMeansTrainer训练器训练好的词汇字典;
- svm.mat:保存训练好的SVM分类器参数;
当我们把is_training设置为False,运行程序,可以得到1000张测试样本的准确率如下:

可以看到准确率大概为95%,如果想得到更高的准确率,我们需要使用更多的数据集进行训练,后面我们对一张图像进行目标检测,效果如下:

然后我更换了一张测试图像,检测结果如下:
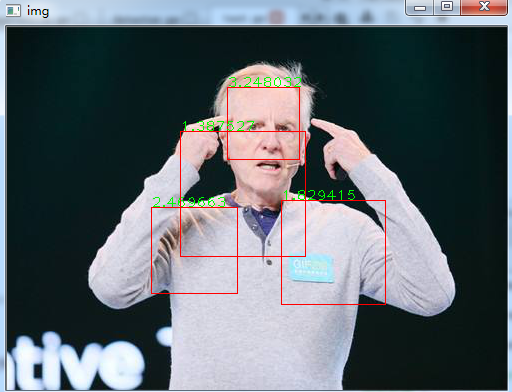
从这一张图上我们看到了什么,你会发现有很多错误的边界框,这主要是因为我们的分类器的准确率只有95%,因此当我们采用滑动窗口时,可能会有成百上千个边界框,这样就会把较多的非人脸框识别为人脸,但是我们会发现人脸边界框的置信度相对较高,对于含有单个人脸的图像,我们可以过滤得到置信度得分最高的边界框。
五 代码下载
参考文章:
[1]OpenCV 3计算机视觉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号