2018年图像算法面试题目收集
1、边缘检测算法有哪些?有什么区别?
边缘检测算子一阶的有Roberts Cross算子,Prewitt算子,Sobel算子,Canny算子, Krisch算子,罗盘算子;而二阶的还有Marr-Hildreth,在梯度方向的二阶导数过零点。
1.1.Roberts(罗伯茨交叉)算子
一种利用局部差分算子寻找边缘的算子,分别为4邻域的坐标。Roberts算子采用对角线方向相邻两像素之差近似梯度幅值检测边缘。检测水平和垂直边缘的效果好于斜向边缘,定位精度高,对噪声敏感

1.2. Sobel(索贝尔)算子
一种一阶微分算子,它利用像素邻近区域的梯度值来计算1个像素的梯度,然后根据一定的绝对值来取舍。

Sobel算子根据像素点上下、左右邻点灰度加权差,在边缘处达到极值这一现象检测边缘。对噪声具有平滑作用,提供较为精确的边缘方向信息,边缘定位精度不够高。当对精度要求不是很高时,是一种较为常用的边缘检测方法。
1.3.Prewitt(普利维特)算子

1.4.Canny 边缘检测算子
canny计算过程:
- 高斯滤波器平滑图像。
- 一阶差分偏导计算梯度值和方向。
- 对梯度值不是极大值的地方进行抑制。
- 用双阈值连接图上的联通点。
通俗说一下,
- 用高斯滤波主要是去掉图像上的噪声。
- 计算一阶差分,OpenCV 源码中也是用 sobel 算子来算的。
- 算出来的梯度值,把不是极值的点,全部置0,去掉了大部分弱的边缘。所以图像边缘会变细。
- 双阈值 t1, t2, 是这样的,t1 <= t2,大于 t2 的点肯定是边缘,小于 t1 的点肯定不是边缘,在 t1, t2 之间的点,通过已确定的边缘点,发起8领域方向的搜索(广搜),图中可达的是边缘,不可达的点不是边缘。
- 最后得出 canny 边缘图。
sobel 产生的边缘有强弱,抗噪性好。
laplace 对边缘敏感,可能有些是噪声的边缘,也被算进来了。
canny 产生的边缘很细,可能就一个像素那么细,没有强弱之分。
数字图像 - 边缘检测原理 - Sobel, Laplace, Canny算子
2、滤波算法有哪些?有什么区别?
2.1.中值滤波
中值滤波将图像的每个像素用邻域 (以当前像素为中心的正方形区域)像素的 中值 代替 。
2.2.均值滤波
输出像素值是核窗口内像素值的 均值 ( 所有像素加权系数相等)
能减弱或者消除图像中高频率分量,但不影响低频率分量,在实际应用中可用来消除噪声。
2.3.高斯滤波
是一种特殊的加权平均,只不过模板中的系数由高斯分布来确定的。
3、什么是霍夫变换
主要用来从图像中分离出具有某种相同特征的几何形状(如,直线,圆等)。
以直线检测为例,把图像笛卡尔坐标系统下的坐标转换到极坐标霍夫空间系统,然后量化霍夫参数空间为有限个值间隔等分或者累加格子。当霍夫变换算法开始,每个像素坐标点P(x, y)被转换到(r, theta)的曲线点上面,累加到对应的格子数据点,当一个波峰出现时候,说明有直线存在。
4、图像特征提取算法有哪些?
4.1. 方向梯度直方图(Histogram of Oriented Gradient, HOG)
主要用来提取图像局部纹理的特征。这个特征名字起的也很直白,就是说先计算图片某一区域中不同方向上梯度的值,然后进行累积,得到直方图,这个直方图呢,就可以代表这块区域了,也就是作为特征,可以输入到分类器里面了。
Histogram of Oriented Gridients(HOG) 方向梯度直方图
4.2.LBP(Local Binary Pattern,局部二值模式)
是一种用来描述图像局部纹理特征的算子;它具有旋转不变性和灰度不变性等显著的优点。
(1)圆形LBP算子:
(2)LBP旋转不变模式
(3)LBP等价模式
每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值)。 LBP的应用中,如纹理分类、人脸分析等,一般都不将LBP图谱作为特征向量用于分类识别,而是采用LBP特征谱的统计直方图作为特征向量用于分类识别。
对LBP特征向量进行提取的步骤
(1)首先将检测窗口划分为16×16的小区域(cell);
(2)对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
(3)然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
(4)最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;
然后便可利用SVM或者其他机器学习算法进行分类了。
4.3.尺度不变特征转换(Scale-invariant feature transform或SIFT)
Sift是一种用来描述图像特征描述子。Sift特征匹配算法可以处理两幅图像之间发生平移、旋转、仿射变换情况下的匹配问题,具有很强的匹配能力。
5、支持向量机的原理?和逻辑回归有什么区别?
利用核函数把数据从输入空间映射到特征空间,将非线性分类问题变换为线性分类问题,然后利用超平面把数据分割开来。
1、多项式核函数
2、高斯核函数
1、logistic回归采用的是log对数似然函数L(Y,P(Y|X))=-log(P(Y|X)),SVM采用的是hingle loss.损失函数的目的都是增加对分类影响较大的数据点的权重,减小对分类影响小的数据点的权重。
一般的软间隔SVM采用的是hinge损失函数进行替代,可以得到常见的软件的SVM的优化目标函数。如果采用的是对率损失函数进行替代那么就和逻辑回归的优化目标几乎相同,这就得到了软间隔SVM与逻辑回归的数学上的联系,因此一般来说SVM的性能和逻辑回归的性能差不多。
2、逻辑回归通过输出预测概率后根据阈值进行判断类别,SVM则直接输出分割超平面,然后使用0/1函数对距离进行分类,不能直接输出概率值,如果需要SVM输出概率值则需要进行特殊处理,可以根据距离的大小进行归一化概率输出。
3、逻辑回归可以使用多阈值然后进行多分类,SVM则需要进行推广。
4、SVM在训练过程只需要支持向量的,依赖的训练样本数较小,而逻辑回归则是需要全部的训练样本数据,在训练时开销更大。
6、聊一聊深度学习用过什么模型
1、分类问题:LeNet、VGG16、Incception、ResNet;
2、目标检测:Faster R-CNN、YOLO网络,SSD;
3、语义分割:FCN;
Faster R-CNN使用RPN(Region Proposal Network)区域提名网络取代了Slective Search,在提取好的特征图上,对所有可能的候选框进行判别。即在训练一个网络,对候选区进行打分。
对于任何尺寸候选区域,RoI pooling layer用来得到一个固定大小的特征图。如果特征图(feature map)上的RoI 大小是h∗w(这里忽略了通道数),将这个特征图划分为h/H∗w/W个网格,每个网格大小为H*W,对每个网格做max pooling,这样得到pooling以后的大小就是H∗W(在文章中,VGG16网络使用H=W=7的参数,上图中绘制的是6x6的)。无论原始的RoI多大,最后都转化为7*7大小的特征图。
7、解释一下什么是过拟合、如何防止过拟合
过拟合就是训练出来的模型在训练集上表现很好,但是在测试集上表现较差的一种现象:
1、提前停止;
2、正则化;
3、弃权;
8、L1正则为何具有稀疏解
L1和L2正则常被用来解决过拟合问题。而L1正则也常被用来进行特征选择,主要原因在于L1正则化会使得较多的参数为0,从而产生稀疏解,将0对应的特征遗弃,进而用来选择特征
9、梯度提升树(Gradient Boosting Decison Tree GBDT)说一下
GDBT是前项分布加法算法的特例。它利用前一轮的若、弱学习器的迭代残差,来学习一个回归数(CART),经过多次迭代,当残差小于阈值时,得到一个强分类器。
10、说一下立体视觉极线校正没有做好,后面的匹配应该怎么做?
SAD匹配算法:基本思想:差的绝对值之和。此算法常用于图像块匹配,将每个像素对应数值之差的绝对值求和,据此评估两个图像块的相似度。该算法快速、但并不精确,通常用于多级处理的初步筛选。
BM算法:
SGBM算法:作为一种全局匹配算法,立体匹配的效果明显好于局部匹配算法
GC算法
视差效果:BM < SGBM < GC
处理速度:BM > SGBM > GC
11、虚函数、多态的作用
简单地说,那些被virtual关键字修饰的成员函数,就是虚函数。虚函数的作用,用专业术语来解释就是实现多态性(Polymorphism),多态性是将接口与实现进行分离;用形象的语言来解释就是实现以共同的方法,但因个体差异而采用不同的策略。
多态还有个关键之处就是一切用指向基类的指针或引用来操作对象。指向基类的指针在操作它的多态类对象时,会根据不同的类对象,调用其相应的函数,这个函数就是虚函数。
12、进程间通信
管道、共享内存、消息队列、套接字、信号、信号量
13、指针和引用的区别
指针:指针是一个变量,只不过这个变量存储的是一个地址,指向内存的一个存储单元;而引用跟原来的变量实质上是同一个东西,只不过是原变量的一个别名而已。
14、对内存了解多少
15、如何定义一个只能在堆上生成对象的类
在C++中,类的对象建立分为两种,一种是静态建立,如A a;另一种是动态建立,如A* ptr=new A;这两种方式是有区别的。
静态建立一个类对象,是由编译器为对象在栈空间中分配内存,是通过直接移动栈顶指针,挪出适当的空间,然后在这片内存空间上调用构造函数形成一个栈对象。使用这种方法,直接调用类的构造函数。
动态建立类对象,是使用new运算符将对象建立在堆空间中。这个过程分为两步,第一步是执行operator new()函数,在堆空间中搜索合适的内存并进行分配;第二步是调用构造函数构造对象,初始化这片内存空间。这种方法,间接调用类的构造函数。
16、TCP三次握手、四次挥手?
TCP,提供面向连接的服务,在传送数据之前必须先建立连接,数据传送完成后要释放连接。因此TCP是一种可靠的的运输服务,但是正因为这样,不可避免的增加了许多的开销,比如确认,流量控制等。对应的应用层的协议主要有 SMTP,TELNET,HTTP,FTP 等。
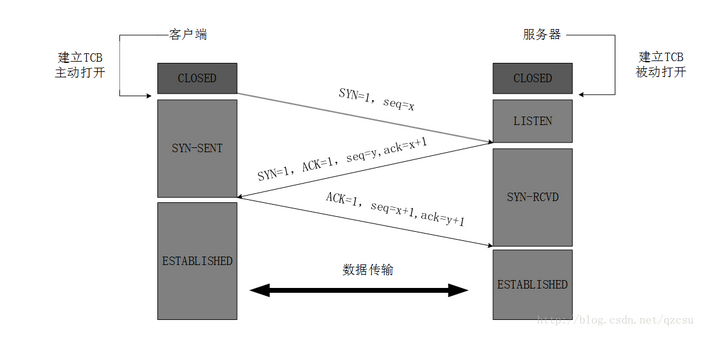
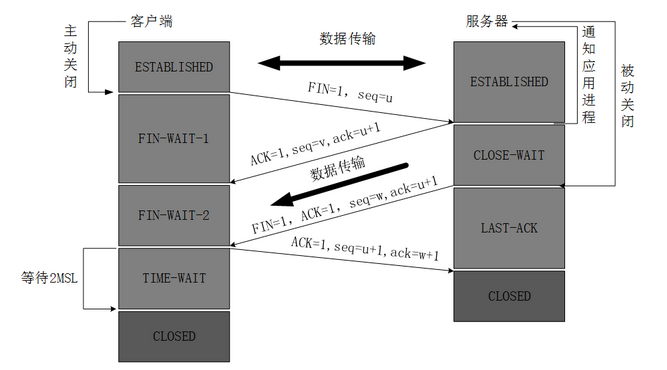
可以用来做端口扫描,如果有应答,说明端口开放。
17、红黑树概念以及应用?
18、局部变量和全局变量的区别?
按存储区域分,全局变量、静态全局变量和静态局部变量都存放在内存的静态存储区域,局部变量存放在内存的栈区。
按作用域分,全局变量在整个工程文件内都有效;静态全局变量只在定义它的文件内有效;静态局部变量只在定义它的函数内有效,只是程序仅分配一次内存,函数返回后,该变量不会消失;局部变量在定义它的函数内有效,但是函数返回后失效。
全局变量和静态变量如果没有手工初始化,则由编译器初始化为0。局部变量的值不可知。
19、怎么实现hashmap?hash冲突怎么办
使用一个下标范围比较大的数组来存储元素。可以设计一个哈希函数使得每个元素的关键字都与一个实际存储地址相对应,于是用这个数组单元来存储这个元素。
但是不能保存每个元素的关键字与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出相同的hash值,这样就产生了“冲突”。这事我们可以采用链地址法,也就是采用数组加链表的方式,数组是hashmap的主体,链表是为了解决哈希冲突存在的,如果定位到的数组包含两边,然后通过关键字去一一查找。
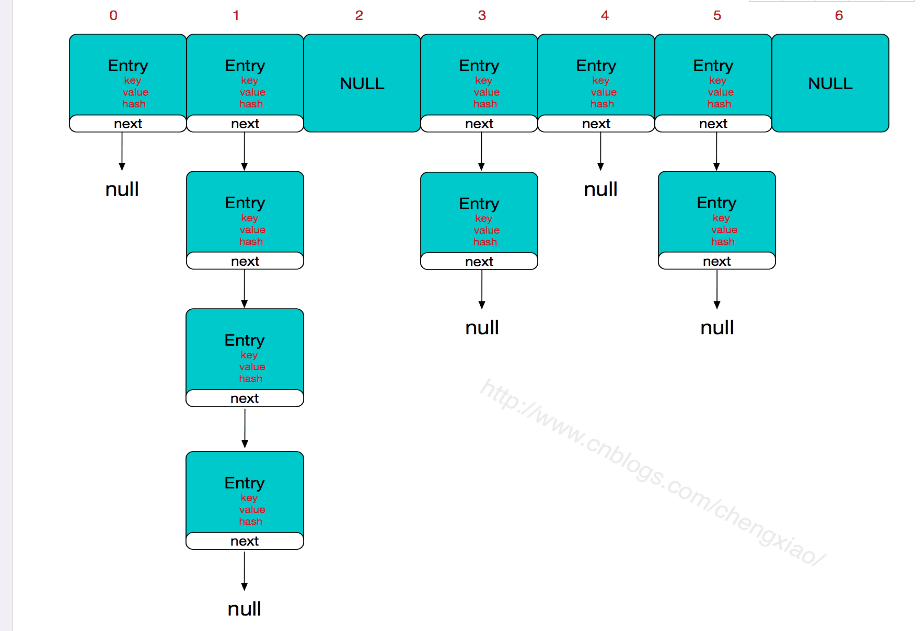
20、进程和线程的区别
1、进程是资源分配的最小单位,线程是CPU调度的最小单位。
2、进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
3、线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
4、但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
21、C++中容器有哪些?
很简单,容器就是保存其它对象的对象,当然这是一个朴素的理解,这种“对象”还包含了一系列处理“其它对象”的方法。
1、顺序容器:是一种各元素之间有顺序关系的线性表,是一种线性结构的可序群集。顺序性容器中的每个元素均有固定的位置,除非用删除或插入的操作改变这个位置。顺序容器的元素排列次序与元素值无关,而是由元素添加到容器里的次序决定。顺序容器包括:vector(向量)、list(列表,和链表类似)、deque(队列)。
2、关联容器:关联式容器是非线性的树结构,更准确的说是二叉树结构。各元素之间没有严格的物理上的顺序关系,也就是说元素在容器中并没有保存元素置入容器时的逻辑顺序。但是关联式容器提供了另一种根据元素特点排序的功能,这样迭代器就能根据元素的特点“顺序地”获取元素。元素是有序的集合,默认在插入的时候按升序排列。关联容器包括:map(集合)、set(映射)、multimap(多重集合)、multiset(多重映射)。
3、容器适配器:本质上,适配器是使一种不同的行为类似于另一事物的行为的一种机制。容器适配器让一种已存在的容器类型采用另一种不同的抽象类型的工作方式实现。适配器是容器的接口,它本身不能直接保存元素,它保存元素的机制是调用另一种顺序容器去实现,即可以把适配器看作“它保存一个容器,这个容器再保存所有元素”。STL
中包含三种适配器:栈stack 、队列queue 和优先级队列priority_queue 。
容器类自动申请和释放内存,因此无需new和delete操作。
22、数据库备份和恢复是怎么实现的?
23、如果网络不收敛怎么解决?
1、数据归一化 : 引入归一化,是由于不同评价指标中,其量纲单位往往不同,变化区间处于不同的数量级,不进行归一化,可能导致某些目标被忽视。
2、Batch Size设的太大
3、学习率设置不对:如果学习率太小,网络很可能会陷入局部最优,局部最优导致了不收敛;但是如果太大,超过了极值,损失就会停止下降,在某一位置反复震荡, 反复震荡也会导致模型的不收敛。
24.、图片字符分割
1、图像信息区域的提取和校正;
- 转换为灰度图、进行滤波处理
- 二值化,进行膨胀处理,使得canny边缘检测时尽可能提取到完整的边缘
- 进行边缘查找,获取最大的边缘
- 找到面积最大的四边形,利用霍夫变换、获取四个顶点,然后计算图像校正的四个顶点,并进行透视变换
2、对于文本倾斜的,用霍夫变化探测出图像中的所有直线,计算每条直线的倾斜角,求他们的平均值,根据倾斜角旋转校正;
3、单字符分割:主要策略就是检测列像素的总和变化,因为没有字符的区域基本是黑色,像素值低;有字符的区域白色较多,列像素和就变大了;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号