磁盘IO性能分析
一、IO性能分析
1.1 IO性能、顺序访问和随机访问
如果去看硬盘厂商的性能报告,通常你会看到两个指标;
- 一个是响应时间(
Response Time); - 另一个叫作数据传输率(
Data Transfer Rate),数据传输率也称吞吐率。
1.1.1 数据传输率
我们先来看一看后面这个指标,数据传输率。
我们现在常用的硬盘有两种;
- 一种是
HDD(Hard Disk Drive)硬盘,也就是我们常说的机械硬盘;现在的HDD硬盘,用的是SATA 3.0的接口; - 另一种是
SSD(Solid State Drive)硬盘,一般也被叫作固态硬盘;而SSD硬盘呢,通常会用两种接口:- 一部分用的也是
SATA 3.0的接口; - 另一部分呢,用的是
PCI Express的接口。
- 一部分用的也是
现在我们常用的SATA 3.0的接口,带宽是6Gb/s;这里的b是比特,这个带宽相当于每秒可以传输600MB的数据。
而我们日常用的HDD硬盘的数据传输率,差不多在100~200MB/s左右。比如:
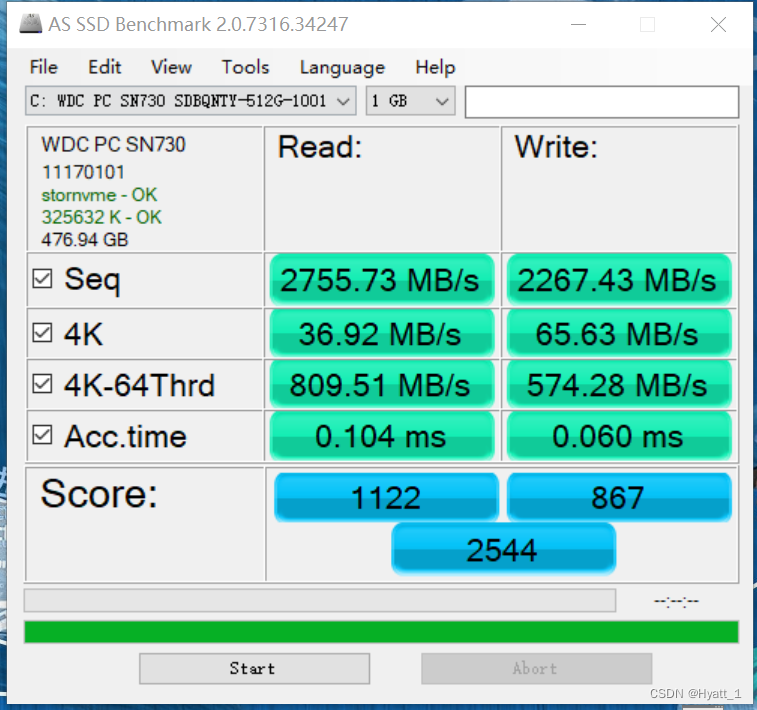
1.1.2 响应时间
除了数据传输率这个吞吐率指标,另一个我们关心的指标响应时间,其实也可以在AS SSD的测试结果里面看到,就是这里面的Acc.Time指标。
这个指标,其实就是程序发起一个硬盘的写入请求,直到这个请求返回的时间。
可以看到,在上面的SSD硬盘上,大概时间都是在几十微秒这个级别。
如果你去测试一块HDD的硬盘,通常会在几毫秒到十几毫秒这个级别。这个性能的差异,就不是10倍了,而是在几十倍,乃至几百倍。
光看响应时间和吞吐率这两个指标,似乎我们的硬盘性能很不错。即使是廉价的HDD硬盘,接收一个来自CPU的请求,也能够在几毫秒时间返回。一秒钟能够传输的数据,也有200MB左右。你想一想,我们平时往数据库里写入一条记录,也就是1KB左右的大小。我们拿200MB去除以1KB,那差不多每秒钟可以插入20万条数据呢。但是这个计算出来的数字,似乎和我们日常的经验不符合啊?这又是为什么呢?
答案就来自于硬盘的读写。在顺序读写和随机读写的情况下,硬盘的性能是完全不同的。
我们回头看一下上面的AS SSD的性能指标。你会看到,里面有一个4K的指标。这个指标是什么意思呢?它其实就是我们的程序,去随机读取磁盘上某一个4KB 大小的数据,一秒之内可以读取到多少数据。
我们拿这个36MB/s和一次读取4KB的数据算一下。
36MB / 4KB = 9000
也就是说,一秒之内,这块SSD硬盘可以随机读取9000次的4KB的数据。如果是写入的话呢,会更多一些65MB /4KB 差不多是1.6万多次。
1.1.3 IOPS
这个每秒读写的次数,我们称之为IOPS,也就是每秒输入输出操作的次数。事实上,比起响应时间,我们更关注IOPS这个性能指标。
IOPS和DTR(Data Transfer Rate,数据传输率)才是输入输出性能的核心指标。
IOPS可细分为如下几个指标:
Toatal IOPS:混合读写和顺序随机I/O负载情况下的磁盘IOPS,这个与实际I/O情况最为相符,大多数应用关注此指标;Random Read IOPS:100%随机读负载情况下的IOPS;Random Write IOPS:100%随机写负载情况下的IOPS;Sequential Read IOPS:100%顺序读负载情况下的IOPS;Sequential Write IOPS:100%顺序写负载情况下的IOPS。
我们在实际的应用开发当中,对于数据的访问,更多的是随机读写,而不是顺序读写。我们平时所说的服务器承受的并发,其实是在说,会有很多个不同的进程和请求来访问服务器。自然,它们在硬盘上访问的数据,是很难顺序放在一起的。这种情况下,随机读写的IOPS才是服务器性能的核心指标。
好了,回到我们引出IOPS这个问题的HDD硬盘,那一块HDD硬盘能够承受的IOPS是多少呢?
HDD硬盘的IOPS通常也就在160左右,而SSD的IOPS大约在10,000-75,000之间,取决于具体的SSD和它的工作负载。
1.2 如何定位IO_WAIT
对于上图那款SSD硬盘,IOPS也就是在1.6万左右。而我们的CPU的主频通常在2GHz以上,也就是每秒可以做20亿次操作。
即使CPU向硬盘发起一条读写指令,需要很多个时钟周期,一秒钟CPU能够执行的指令数,和我们硬盘能够进行的操作数,也有好几个数量级的差异。
这也是为什么,我们在应用开发的时候往往会说性能瓶颈在I/O上。因为很多时候,CPU指令发出去之后,不得不去等我们的I/O操作完成,才能进行下一步的操作。
那么,在实际遇到服务端程序的性能问题的时候,我们怎么知道这个问题是不是来自于CPU等I/O来完成操作呢?
别着急,我们接下来我们以我们测试环境遇到的IO问题为例,就通过top和iostat这些命令,一起来看看CPU到底有没有在等待io操作。
1.2.1 top
在Linux下经常会用top去看服务的负载,也就是load average。load average(负载平均值)是一个重要的性能指标,它反映了系统在过去1分钟、5分钟和15分钟内的平均负载情况。

1.2.1.1 load average
load average 的三个值通常显示在任务栏的第一行中:
- 第一个值 (1分钟内的平均负载):这个值表示最近1分钟内正在运行和等待运行的进程的平均数量;如果这个值持续高于系统的
CPU核心数(例如,如果你有4核CPU,1分钟平均负载超过4),则系统可能会感觉到响应变慢; - 第二个值 (5分钟内的平均负载):这个值显示了最近5分钟内的平均负载情况,它可以帮助你观察到系统负载的长期趋势;
- 第三个值 (15分钟内的平均负载):这个值是最近15分钟内的平均负载情况,通常用来判断系统负载的趋势和变化;
通常来说,如果load average长期超过系统的CPU核心数(尤其是1分钟和5分钟的值),系统可能会感到卡顿或响应变慢,这时候需要进一步检查系统的资源使用情况和可能的性能瓶颈。
通过上图看到load average显示高于系统的核心数(96核),并且持续较长时间。
此外我们机器内存251G,目前剩余只有3G左右,导致服务器输入命令存在严重卡顿问题。
1.2.1.2 各个参数
此外,我们可以通过数字键1调出CPU的资源使用情况。
在top命令的输出结果里面,有一行是以%CPU开头的。下面是各个百分比的含义:
-
us(userspace):用户空间的程序所消耗的CPU时间百分比,这表示正在运行的用户进程(非内核进程)所使用的CPU时间; -
sy(system):内核空间的程序所消耗的CPU时间百分比。这表示正在运行的内核进程所使用的CPU时间,如系统调用、中断处理等; -
ni(nice):通过nice命令设置了较低优先级的进程所消耗的CPU时间百分比;在这个报告中,该项值为0.1; -
id(idle):空闲状态的CPU时间百分比,这表示CPU未被任何任务占用的时间; -
wa(waiting):等待I/O完成的CPU时间百分比,这表示CPU在等待磁盘或其他I/O设备完成操作时所使用的时间; -
hi(hardwareinterrupts):硬件中断所消耗的CPU时间百分比。这表示CPU在处理硬件中断请求时所使用的时间; -
si(softwareinterrupts):软件中断所消耗的CPU时间百分比。这表示CPU在处理软件中断请求时所使用的时间; -
st(stealtime):当运行在虚拟化环境中的虚拟机被物理主机偷取CPU时间时所消耗的CPU时间百分比;
这一行里,有一个叫作wa的指标,这个指标就代表着iowait,也就是CPU等待IO完成操作花费的时间占 CPU的百分比。如果wa值很高,说明系统中有大量的I/O操作占用了CPU时间,导致CPU无法及时处理其他任务,从而影响系统性能。
当系统中有大量的进程在运行时,只有一小部分进程是I/O密集型进程,即依赖磁盘I/O的进程,而其余进程主要是CPU密集型进程,即需要大量的计算资源的进程。因此,在这种情况下,即使磁盘已经达到了最大的吞吐量,wa指标值也可能很低,因为系统中大多数进程并不需要等待磁盘I/O的完成。
下一次,当你自己的服务器遇到性能瓶颈,load很大的时候,你就可以通过top看一看这个指标。
知道了iowait很大,那么我们就要去看一看,实际的I/O操作情况是什么样的。这个时候,你就可以去用iostat这个命令了。
1.2.2 iostat
iotop命令看到实际的硬盘读写情况,这个命令里,不仅有iowait这个CPU等待时间的百分比,还有一些更加具体的指标了,并且它还是按照你机器上安装的多块不同的硬盘划分的。
iostat查看系统IO指标:
iostat -dx 1
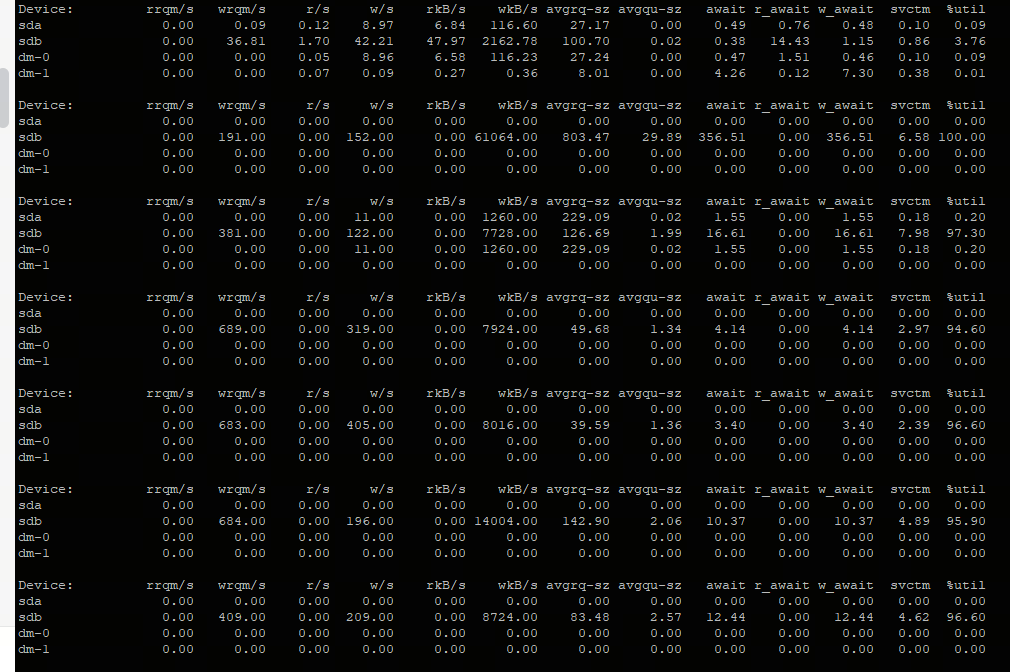
其中:
Device:磁盘设备名称;rrqm/s:每秒钟发起的读请求被合并为更大的请求的数量;wrqm/s:每秒钟发起的写请求被合并为更大的请求的数量;r/s:每秒钟发起的读请求的数量;w/s:每秒钟发起的写请求的数量;rkB/s:每秒钟读取的数据量,单位为KB;wkB/s:每秒钟写入的数据量,单位为KB;avgrq-sz:平均请求大小,单位为扇区大小(一般为512字节);avgqu-sz:平均请求队列长度;await:平均请求等待时间,单位为毫秒;r_await:平均读请求等待时间,单位为毫秒;w_await:平均写请求等待时间,单位为毫秒;svctm:平均请求处理时间,单位为毫秒;%util:磁盘处理I/O的时间百分比,即设备正在处理请求的时间占总时间的百分比;
其中重点关注:
r/s + w/s就是IOPS,即每秒读写次数;rkB/s + wkB/s就是吞吐量,即每秒读写数据量;对应着我们的数据传输率的指标;r_await + w_await,就是响应时间,即指I/O请求从发出到收到响应的间隔时间;
知道实际硬盘读写的IOPS、数据传输率的指标,我们基本上可以判断出,机器的性能是不是卡在I/O上了。
如果util字段显示为100%,表示磁盘正在以最大速度处理请求,也就是说磁盘已经达到了最大的吞吐量。这意味着磁盘已经成为系统中的瓶颈,无法再处理更多的I/O请求。这种情况下,应该考虑增加更多的磁盘或者使用更快的存储设备来提高系统性能。同时,也可以尝试优化应用程序的I/O操作,减少对磁盘的访问,从而降低磁盘的负载。
此前,我们提到过我们机器内存251G,只剩下3G左右,导致服务器输入命令存在严重卡顿问题。后面停止到一些进程后,服务运行正常,内存占用如下;
[root@kylin ~]$ free -h -m
total used free shared buff/cache available
Mem: 251G 116G 13G 4.8G 121G 128G
Swap: 0B 0B 0B
再次通过iostat查看系统IO指标:

可以看到此时的wkB/s可以达到上百MB,远高于服务器卡顿时的10~20MB。
1.2.3 iotop
如果机器的性能卡在了I/O上,通过iotop这个命令,可以看到具体是哪一个进程实际占用了大量I/O;
sudo iotop -o -b | while read -r line;do echo "$line" | grep 'Actual DISKWRITE';done
sudo iotop -oP
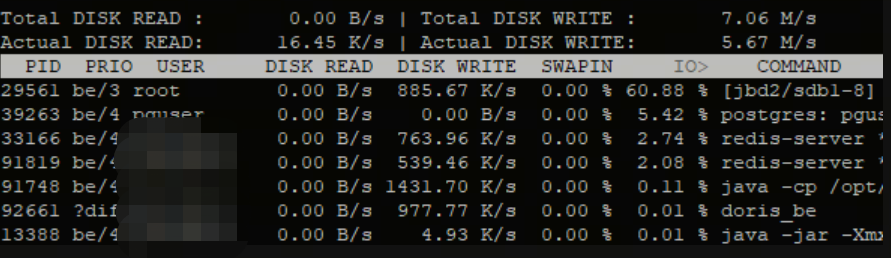
其中:
-o:only show processes or threads actually doing I/O;-P:only show processes, not all threads;-k:use kilobytes instead of a human friendly unit;-b:non-interactive mode;
前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O合并等因素的影响,它们可能并不相等。
如果进程IO等待时间过长(比如80%),大概率磁盘IO到了瓶颈,来不及处理。
关注一下Actual DISK WRITE这个参数,可以参考4K指标的值,如果超过这个值,这台机器的磁盘I/O基本就满了;可以结合夜莺看一下I/O是否满了。
1.3 慢SQL
有时候存在数据库慢SQL导致其他进程请求超时,PG慢SQL查询;
select *
from pg_stat_activity
where state <> 'idle'
and now() - query_start > interval '1s'
order by query_start;
可以看到是否存在慢SQL,以及该SQL是否一次请求了万级别以上的数据。
二、jbd2进程导致磁盘IO高
在服务器发现业务进程偶尔响应超时,排查后发现磁盘的sdb util接近100%;

但是磁盘吞吐量并不高,IO流量只有6MB左右,主要是由w/s导致,也就是写入的IOPS高,这种情况一般就是进程的sync操作密集。
2.1 iotop
通过iotop来查看是哪个进程,显示为jbd2;
查阅一些资料后,了解到jbd2进程负责ext4这种日志文件系统的日志提交操作,关于jbd2引起磁盘IO高,网上也有很多类似案例,总结起来有几方面原因:
- 系统
bug; ext4文件系统的相关配置问题;- 其他进程的
fsync,sync操作过于频繁;
首先排除系统bug因素,网络上反馈的问题在很低的版本,我们生产环境为Centos 7+,其次,查阅了/proc/mounts等信息,发现文件系统配置参数与其他环境差异不大,按照网上提供的关闭某些特性,降低commit 频率等理论来说会有效果,但需要重新mount磁盘,相关组件都要重启,并且这看起来并非根本原因。
2.2 sync
尝试分析sync调用,使用sysdig最方便,但现场环境安装很麻烦,因此开启几个内核trace查看:
在jbd2执行flush时输出日志
echo 1 > /sys/kernel/debug/tracing/events/jbd2/jbd2_commit_flushing/enable
在任意进程执行sync时输出日志:
echo 1 > /sys/kernel/debug/tracing/events/ext4/ext4_sync_file_enter/enable
然后观察日志输出:
cat /sys/kernel/debug/tracing/trace_pipe
输出信息如下:
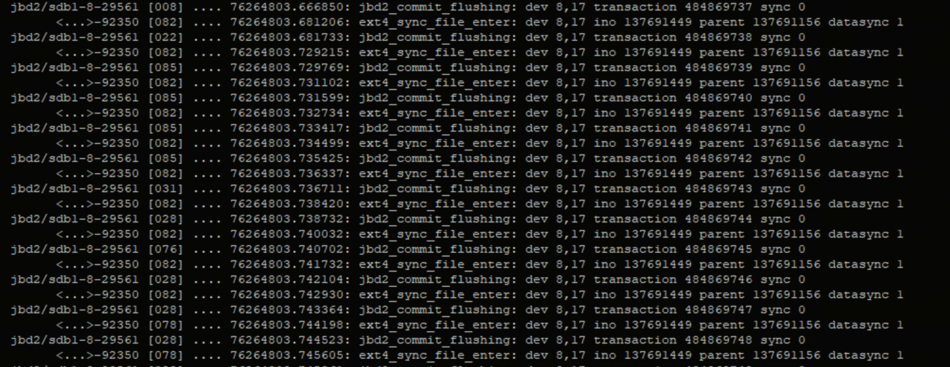
可以看到jbd2和 92350进程有大量的sync,瞬间刷出大量日志,因此基本确定92350进程。
ps看一下是哪个任务导致的:
ps -efL | grep 92350
-L或-T参数显示线程id,ps获取到pid和程序路径后,发现是XX进程,很让人疑惑,XX怎么会大量sync 呢,trace 一下他在做什么。
2.3 strace
我们可以通过strace工具来跟踪进程的系统调用链:
strace -f -p 92350
输出如下:
[pid 13079] writev(357, [{"\0\0\0\30", 4}, {"\2\1\0\0\0\0\0\0\0\0\0\0\0\0i\350\0\0\0\0\0\2\21R", 24}], 2 <unfinished ...>
[pid 93525] futex(0x7fd6040097f8, FUTEX_WAIT_PRIVATE, 2, NULL <unfinished ...>
[pid 93518] futex(0x7fd6040097f8, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
[pid 13089] writev(353, [{"\0\0\0\30", 4}, {"\2\1\0\0\0\0\0\0\0\0\0\0\0\0j\22\0\0\0\0\0\0S\353", 24}], 2 <unfinished ...>
[pid 13088] writev(352, [{"\0\0\0\30", 4}, {"\2\1\0\0\0\0\0\0\0\0\0\0\0\0j\1\0\0\0\0\0\1r\16", 24}], 2 <unfinished ...>
[pid 13086] <... writev resumed> ) = 28
[pid 13080] writev(358, [{"\0\0\0\30", 4}, {"\2\1\0\0\0\0\0\0\0\0\0\0\0\0i\344\0\0\0\0\0\2\10\261", 24}], 2 <unfinished ...>
[pid 13079] <... writev resumed> ) = 28
[pid 93525] <... futex resumed> ) = -1 EAGAIN (Resource temporarily unavailable)
[pid 93518] <... futex resumed> ) = 0
[pid 13089] <... writev resumed> ) = 28
根据fd号去看看这是什么文件:
ll /proc/92350/fd/357
2.4 lsof
我们通过lsof跟踪进程打开的文件信息:
lsof -p 92350
2.5 pidstat
使用pidstat不加任何参数等价于加上-p参数,但是只有正在活动的任务会被显示出来;
13时56分44秒 UID PID %usr %system %guest %CPU CPU Command
13时56分44秒 0 1 0.15 0.26 0.00 0.41 7 systemd
13时56分44秒 0 2 0.00 0.00 0.00 0.00 11 kthreadd
13时56分44秒 0 6 0.00 0.02 0.00 0.02 0 ksoftirqd/0
13时56分44秒 0 7 0.00 0.00 0.00 0.00 0 migration/0
13时56分44秒 0 9 0.00 0.36 0.00 0.36 8 rcu_sched
13时56分44秒 0 11 0.00 0.00 0.00 0.00 0 watchdog/0
13时56分44秒 0 12 0.00 0.00 0.00 0.00 1 watchdog/1
13时56分44秒 0 13 0.00 0.00 0.00 0.00 1 migration/1
13时56分44秒 0 14 0.00 0.00 0.00 0.00 1 ksoftirqd/1
13时56分44秒 0 17 0.00 0.00 0.00 0.00 2 watchdog/2
13时56分44秒 0 18 0.00 0.00 0.00 0.00 2 migration/2
13时56分44秒 0 19 0.00 0.00 0.00 0.00 2 ksoftirqd/2
......
其中:
PID:被监控的任务的进程号;%usr:当在用户层执行(应用程序)时这个任务的cpu使用率,和nice优先级无关。注意这个字段计算的cpu时间不包括在虚拟处理器中花去的时间;%system: 这个任务在系统层使用时的cpu使用率;%guest: 任务花费在虚拟机上的cpu使用率(运行在虚拟处理器);%CPU:任务总的cpu使用率。在SMP环境(多处理器)中,如果在命令行中输入-I参数的话,cpu使用率会除以你的cpu数量;CPU:正在运行这个任务的处理器编号;Command:这个任务的命令名称。
一个命令查看指定进程的CPU、内存、磁盘IO、上下文切换次数的使用情况;
pidstat [option] [interval] [count]
其中:
option:指定运行参数;interval:指定两次输出之间的时间间隔,单位秒;count:指定输出次数。
2.5.1 查看内存
查看指定进程内存使用情况:
pidstat -r -p [pid] 5
返回结果中:
minflt/s:进程每秒发生的次要错误,不需要从磁盘加载页;majflt/s:进程每秒发生的主要错误,需要从磁盘加载页;VSZ:分配给进程的虚拟内存大小,单位KB;RSS:分配给进程的真实内存大小,单位KB;%MEM:进程占用的内存百分比。
2.5.2 查看磁盘IO
观测进程的IO性能指标:
pidstat -d -p 92350 1 5
输出结果如下:
20时31分40秒 UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
20时31分41秒 1005 92350 0.00 2864.00 0.00 java
20时31分42秒 1005 92350 0.00 2868.00 0.00 java
20时31分43秒 1005 92350 0.00 2972.00 0.00 java
20时31分44秒 1005 92350 0.00 2732.00 0.00 java
20时31分45秒 1005 92350 0.00 2876.00 0.00 java
平均时间: 1005 92350 0.00 2862.40 0.00 java
其中:
-d:展示IO统计数据;-p:指定进程号;- 间隔
1秒输出5组数据; - 输出中每项的含义:
- 每秒读取的数据大小(
kB_rd/s),单位是KB; - 每秒发出的写请求数据大小(
kB_wr/s),单位是KB; - 每秒取消的写请求数据大小(
kB_ccwr/s),单位是KB。
- 每秒读取的数据大小(
2.5.3 查看进程上下文切换
pidstat -w -p [pid] 5
返回结果中:
cswch/s:进程主动进行上下文切换的次数;nvcswch/s:进程被动进行上下文切换的次数。
2.5.4 查看线程
如果想查看指定进程所有线程的CPU、内存、磁盘IO、上下文切换次数的使用情况;
比如查看进程所有线程的CPU使用情况:
pidstat -u -t -p [pid] 5
返回结果中:
TGID:主线程ID;TID:线程ID。
参考文章:
[1] IO性能到底是怎么回事儿

 浙公网安备 33010602011771号
浙公网安备 33010602011771号