linux同步机制-互斥锁
一、互斥锁(mutex)
1.1 什么是互斥锁
互斥锁实现了“互相排斥”(mutual exclusion)同步的简单形式,所以名为互斥锁。互斥锁禁止多个进程同时进入受保护的代码“临界区”(critical section)。因此,在任意时刻,只有一个进程被允许进入这样的代码保护区。
mutex的语义相对于信号量要简单轻便一些,在锁争用激烈的测试场景下,mutex比信号量执行速度更快,可扩展性更好,另外mutex数据结构的定义比信号量小。
1.2 互斥锁的特性
- 互斥锁是Linux内核中用于互斥操做的一种同步原语;
- 互斥锁是一种休眠锁,锁争用时可能存在进程的睡眠与唤醒,context的切换带来的代价较高,适用于加锁时间较长的场景;
- 互斥锁每次只容许一个进程进入临界区,有点相似于二值信号量;
- 互斥锁在锁争用时,在锁被持有时,选择自旋等待,而不当即进行休眠,能够极大的提升性能,这种机制(optimistic spinning)也应用到了读写信号量上;
- 互斥锁的缺点是互斥锁对象的结构较大,会占用更多的CPU缓存和内存空间;
- 与信号量相比,互斥锁的性能与扩展性都更好,所以,在内核中老是会优先考虑互斥锁;
- 互斥锁按为了提升性能,提供了三条路径处理:快速路径,中速路径,慢速路径;
1.3 互斥锁的使用
定义互斥锁:
struct mutex my_mutex;
初始化互斥锁:
mutex_init(&my_mutex);
或者使用宏定义,并初始化互斥锁:
DEFINE_MUTEX(my_mutex)
获取互斥锁:
void mutex_lock(struct mutex *lock);
该函数用于获得mutex, 它会导致睡眠, 因此不能在中断上下文中使用。
int mutex_lock_interruptible(struct mutex *lock);
该函数功能与mutex_lock类似,不同之处为mutex_lock进入睡眠状态的进程不能被信号打断,而mutex_lock_interruptible进入睡眠状态的进程能被信号打断,而使用此函数进入休眠后,进程状态被设置为TASK_INTERRUPTIBLE,该类型的睡眠是可以被信号打断的。
如果返回0,表示获得互斥锁;如果被信号打断,返回EINTR。
int mutex_trylock(struct mutex *lock);
mutex_trylock用于尝试获得mutex,获取不到mutex时不会引起进程睡眠。
释放互斥锁:
void mutex_unlock(struct mutex *lock);
1.4 mutex和信号量
mutex和信号量相比要高效的多:
- mutex最先实现自旋等待机制;
- mutex在睡眠之前尝试获取锁;
- mutex实现MCS所来避免多个CPU争用锁而导致CPU高速缓存颠簸现象;
二、MCS锁机制
2.1 MCS锁
- 上文中提到过mutex在实现过程当中,采用了optimistic spinning自旋等待机制,这个机制的核心就是基于MCS锁机制来实现的;
- MCS锁机制是由John Mellor Crummey和Michael Scott在论文中《algorithms for scalable synchronization on shared-memory multiprocessors》提出的,并以他俩的名字来命名;
- MCS锁机制要解决的问题是:在多CPU系统中,每当一个spinlock的值出现变化时,所有试图获取这个spinlock的CPU都需要读取内存,刷新自己对应的cache line,而最终只有一个CPU可以获得锁,也只有它的刷新才是有意义的。锁的争抢越激烈(试图获取锁的CPU数目越多),无谓的开销也就越大;
- MCS锁机制的核心思想:每一个CPU都分配一个自旋锁结构体,自旋锁的申请者(per-CPU)在local-CPU变量上自旋,这些结构体组建成一个链表,申请者自旋等待前驱节点释放该锁;
- osq(optimistci spinning queue)是基于MCS算法的一个具体实现,并通过了迭代优化;
2.2 oqs流程分析
optimistic spinning,乐观自旋,到底有多乐观呢?当发现锁被持有时,optimistic spinning相信持有者很快就能把锁释放,因此它选择自旋等待,而不是睡眠等待,这样也就能减少进程切换带来的开销了。
看一下数据结构吧:

osq_lock如下:

osq加锁有几种情况:
- 加锁过程中使用了原子操作,来确保正确性; 无人持有锁,那是最理想的状态,直接返回;
- 有人持有锁,将当前的Node加入到OSQ队列中,在没有高优先级任务抢占时,自旋等待前驱节点释放锁;
- 自旋等待过程中,如果遇到高优先级任务抢占,那么需要做的事情就是将之前加入到OSQ队列中的当前节点,从OSQ队列中移除,移除的过程又分为三个步骤,分别是处理prev前驱节点的next指针指向、当前节点Node的next指针指向、以及将prev节点与next后继节点连接;
加锁过程中使用了原子操作,来确保正确性;
osq_unlock如下:

解锁时也分为几种情况:
- 无人争用该锁,那直接可以释放锁;
- 获取当前节点指向的下一个节点,如果下一个节点不为NULL,则将下一个节点解锁;
- 当前节点的下一个节点为NULL,则调用osq_wait_next,来等待获取下一个节点,并在获取成功后对下一个节点进行解锁;
从解锁的情况可以看出,这个过程相当于锁的传递,从上一个节点传递给下一个节点;
在加锁和解锁的过程中,由于可能存在操作来更改osq队列,因此都调用了osq_wait_next来获取下一个确定的节点:

三、互斥锁源码实现
3.1 mutex
mutext结构体在include/linux/mutex.h文件中定义:
/* * Simple, straightforward mutexes with strict semantics: * * - only one task can hold the mutex at a time * - only the owner can unlock the mutex * - multiple unlocks are not permitted * - recursive locking is not permitted * - a mutex object must be initialized via the API * - a mutex object must not be initialized via memset or copying * - task may not exit with mutex held * - memory areas where held locks reside must not be freed * - held mutexes must not be reinitialized * - mutexes may not be used in hardware or software interrupt * contexts such as tasklets and timers * * These semantics are fully enforced when DEBUG_MUTEXES is * enabled. Furthermore, besides enforcing the above rules, the mutex * debugging code also implements a number of additional features * that make lock debugging easier and faster: * * - uses symbolic names of mutexes, whenever they are printed in debug output * - point-of-acquire tracking, symbolic lookup of function names * - list of all locks held in the system, printout of them * - owner tracking * - detects self-recursing locks and prints out all relevant info * - detects multi-task circular deadlocks and prints out all affected * locks and tasks (and only those tasks) */ struct mutex { atomic_long_t owner; spinlock_t wait_lock; #ifdef CONFIG_MUTEX_SPIN_ON_OWNER struct optimistic_spin_queue osq; /* Spinner MCS lock */ #endif struct list_head wait_list; #ifdef CONFIG_DEBUG_MUTEXES void *magic; #endif #ifdef CONFIG_DEBUG_LOCK_ALLOC struct lockdep_map dep_map; #endif };
可以看到上面的英文注释:
- 一次只能有一个进程能持有互斥锁;
- 只有锁的持有者能进行解锁操作;
- 禁止多次解锁操作;
- 禁止递归加锁操作;
- mutext结构必须通过API进行初始化;
- mutex结构禁止通过memset或者拷贝来进行初始化;
- 持有互斥锁的进程可能无法退出;
- 不能释放持有锁所在的内存区域;
- 已经被持有的muetxt锁禁止被再初始化;
- mutext锁不能在硬件或软件中断上下文中使用,比如tasklet、定时器等;
然后我们再来介绍这个结构体中几个重要的成员:
- owner:原子计数。用于指向锁持有者进程的task struct,0表示没有被进程持有锁;
- wait_lock:自旋锁,用于wait_list链表的保护操作;
- wait_list:是一个双向链表,使用该等待列表保存因获取不到互斥锁而进行睡眠的进程:;
从上面成员可以看到,mutext的源码实现应该使用到了原子操作、以及自旋锁。
当存在多个进程竞争互斥锁时,由于互斥锁是共享变量,因此对互斥锁的成员变量的修改都要是互斥操作。
3.2 mutext初始化
mutex锁的初始化有两种方式,一种是静态使用DEFINE_MUTEX宏:
#define __MUTEX_INITIALIZER(lockname) \ { .owner = ATOMIC_LONG_INIT(0) \ , .wait_lock = __SPIN_LOCK_UNLOCKED(lockname.wait_lock) \ , .wait_list = LIST_HEAD_INIT(lockname.wait_list) \ __DEBUG_MUTEX_INITIALIZER(lockname) \ __DEP_MAP_MUTEX_INITIALIZER(lockname) } #define DEFINE_MUTEX(mutexname) \ struct mutex mutexname = __MUTEX_INITIALIZER(mutexname)
这里初始化了原子计数owner、自旋锁结构体wait_lock 、以及等待列表wait_list。
另一种是在内核代码中动态使用mutex_init函数,定义在kernel/locking/mutex.c文件中::
# define mutex_init(mutex) \ do { \ static struct lock_class_key __key; \ \ __mutex_init((mutex), #mutex, &__key); \ } while (0) void __mutex_init(struct mutex *lock, const char *name, struct lock_class_key *key) { atomic_set(&lock->count, 1); spin_lock_init(&lock->wait_lock); INIT_LIST_HEAD(&lock->wait_list); mutex_clear_owner(lock); #ifdef CONFIG_MUTEX_SPIN_ON_OWNER osq_lock_init(&lock->osq); //初始化MCS锁 #endif debug_mutex_init(lock, name, key); }
3.2 mutex_lock
mutext_lock加锁流程如下图:

mutex_lock定义在kernel/locking/mutex.c文件中:
/** * mutex_lock - acquire the mutex * @lock: the mutex to be acquired * * Lock the mutex exclusively for this task. If the mutex is not * available right now, it will sleep until it can get it. * * The mutex must later on be released by the same task that * acquired it. Recursive locking is not allowed. The task * may not exit without first unlocking the mutex. Also, kernel * memory where the mutex resides must not be freed with * the mutex still locked. The mutex must first be initialized * (or statically defined) before it can be locked. memset()-ing * the mutex to 0 is not allowed. * * (The CONFIG_DEBUG_MUTEXES .config option turns on debugging * checks that will enforce the restrictions and will also do * deadlock debugging) * * This function is similar to (but not equivalent to) down(). */ void __sched mutex_lock(struct mutex *lock) { might_sleep(); if (!__mutex_trylock_fast(lock)) __mutex_lock_slowpath(lock); }
mutex_lock为了提高性能,分为三种路径处理,优先使用快速和中速路径来处理,如果条件不满足则会跳转到慢速路径来处理,慢速路径中会进行睡眠和调度,因此开销也是最大的。
3.3 fast-path
快速路径是在__mutex_trylock_fast中实现:
/* * Lockdep annotations are contained to the slow paths for simplicity. * There is nothing that would stop spreading the lockdep annotations outwards * except more code. */ /* * Optimistic trylock that only works in the uncontended case. Make sure to * follow with a __mutex_trylock() before failing. */ static __always_inline bool __mutex_trylock_fast(struct mutex *lock) { unsigned long curr = (unsigned long)current; unsigned long zero = 0UL; if (atomic_long_try_cmpxchg_acquire(&lock->owner, &zero, curr)) return true; return false; }
直接调用原子操作函数atomic_long_try_cmpxchg_acquire来进行判断:
- 如果lock->owner等于0,则将curr赋值给lock->owner,标识curr进程持有锁,并直接返回:
- 如果lock->owner不等于0,表明锁被持有,需要进入下一个路径来处理了;
3.4 mid-path
中速路径和慢速路径都在__mutex_lock_common中实现:
static noinline void __sched __mutex_lock_slowpath(struct mutex *lock) { __mutex_lock(lock, TASK_UNINTERRUPTIBLE, 0, NULL, _RET_IP_); } static int __sched __mutex_lock(struct mutex *lock, long state, unsigned int subclass, struct lockdep_map *nest_lock, unsigned long ip) { return __mutex_lock_common(lock, state, subclass, nest_lock, ip, NULL, false); }
可以看到__mutex_lock_slowpath的最终实现在__mutex_lock_common函数中:


1 /* 2 * Lock a mutex (possibly interruptible), slowpath: 3 */ 4 static __always_inline int __sched 5 __mutex_lock_common(struct mutex *lock, long state, unsigned int subclass, 6 struct lockdep_map *nest_lock, unsigned long ip, 7 struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx) 8 { 9 struct mutex_waiter waiter; 10 bool first = false; 11 struct ww_mutex *ww; 12 int ret; 13 14 might_sleep(); 15 16 ww = container_of(lock, struct ww_mutex, base); 17 if (use_ww_ctx && ww_ctx) { 18 if (unlikely(ww_ctx == READ_ONCE(ww->ctx))) 19 return -EALREADY; 20 21 /* 22 * Reset the wounded flag after a kill. No other process can 23 * race and wound us here since they can't have a valid owner 24 * pointer if we don't have any locks held. 25 */ 26 if (ww_ctx->acquired == 0) 27 ww_ctx->wounded = 0; 28 } 29 30 preempt_disable(); 31 mutex_acquire_nest(&lock->dep_map, subclass, 0, nest_lock, ip); 32 33 if (__mutex_trylock(lock) || 34 mutex_optimistic_spin(lock, ww_ctx, use_ww_ctx, NULL)) { 35 /* got the lock, yay! */ 36 lock_acquired(&lock->dep_map, ip); 37 if (use_ww_ctx && ww_ctx) 38 ww_mutex_set_context_fastpath(ww, ww_ctx); 39 preempt_enable(); 40 return 0; 41 } 42 spin_lock(&lock->wait_lock); 43 /* 44 * After waiting to acquire the wait_lock, try again. 45 */ 46 if (__mutex_trylock(lock)) { 47 if (use_ww_ctx && ww_ctx) 48 __ww_mutex_check_waiters(lock, ww_ctx); 49 50 goto skip_wait; 51 } 52 53 debug_mutex_lock_common(lock, &waiter); 54 55 lock_contended(&lock->dep_map, ip); 56 57 if (!use_ww_ctx) { 58 /* add waiting tasks to the end of the waitqueue (FIFO): */ 59 __mutex_add_waiter(lock, &waiter, &lock->wait_list); 60 61 62 #ifdef CONFIG_DEBUG_MUTEXES 63 waiter.ww_ctx = MUTEX_POISON_WW_CTX; 64 #endif 65 } else { 66 /* 67 * Add in stamp order, waking up waiters that must kill 68 * themselves. 69 */ 70 ret = __ww_mutex_add_waiter(&waiter, lock, ww_ctx); 71 if (ret) 72 goto err_early_kill; 73 74 waiter.ww_ctx = ww_ctx; 75 } 76 77 waiter.task = current; 78 79 set_current_state(state); 80 for (;;) { 81 /* 82 * Once we hold wait_lock, we're serialized against 83 * mutex_unlock() handing the lock off to us, do a trylock 84 * before testing the error conditions to make sure we pick up 85 * the handoff. 86 */ 87 if (__mutex_trylock(lock)) 88 goto acquired; 89 90 /* 91 * Check for signals and kill conditions while holding 92 * wait_lock. This ensures the lock cancellation is ordered 93 * against mutex_unlock() and wake-ups do not go missing. 94 */ 95 if (signal_pending_state(state, current)) { 96 ret = -EINTR; 97 goto err; 98 } 99 if (use_ww_ctx && ww_ctx) { 100 ret = __ww_mutex_check_kill(lock, &waiter, ww_ctx); 101 if (ret) 102 goto err; 103 } 104 105 spin_unlock(&lock->wait_lock); 106 schedule_preempt_disabled(); 107 108 /* 109 * ww_mutex needs to always recheck its position since its waiter 110 * list is not FIFO ordered. 111 */ 112 if ((use_ww_ctx && ww_ctx) || !first) { 113 first = __mutex_waiter_is_first(lock, &waiter); 114 if (first) 115 __mutex_set_flag(lock, MUTEX_FLAG_HANDOFF); 116 } 117 118 set_current_state(state); 119 /* 120 * Here we order against unlock; we must either see it change 121 * state back to RUNNING and fall through the next schedule(), 122 * or we must see its unlock and acquire. 123 */ 124 if (__mutex_trylock(lock) || 125 (first && mutex_optimistic_spin(lock, ww_ctx, use_ww_ctx, &waiter))) 126 break; 127 128 spin_lock(&lock->wait_lock); 129 } 130 spin_lock(&lock->wait_lock); 131 acquired: 132 __set_current_state(TASK_RUNNING); 133 134 if (use_ww_ctx && ww_ctx) { 135 /* 136 * Wound-Wait; we stole the lock (!first_waiter), check the 137 * waiters as anyone might want to wound us. 138 */ 139 if (!ww_ctx->is_wait_die && 140 !__mutex_waiter_is_first(lock, &waiter)) 141 __ww_mutex_check_waiters(lock, ww_ctx); 142 } 143 144 mutex_remove_waiter(lock, &waiter, current); 145 if (likely(list_empty(&lock->wait_list))) 146 __mutex_clear_flag(lock, MUTEX_FLAGS); 147 148 debug_mutex_free_waiter(&waiter); 149 150 skip_wait: 151 /* got the lock - cleanup and rejoice! */ 152 lock_acquired(&lock->dep_map, ip); 153 154 if (use_ww_ctx && ww_ctx) 155 ww_mutex_lock_acquired(ww, ww_ctx); 156 157 spin_unlock(&lock->wait_lock); 158 preempt_enable(); 159 return 0; 160 161 err: 162 __set_current_state(TASK_RUNNING); 163 mutex_remove_waiter(lock, &waiter, current); 164 err_early_kill: 165 spin_unlock(&lock->wait_lock); 166 debug_mutex_free_waiter(&waiter); 167 mutex_release(&lock->dep_map, 1, ip); 168 preempt_enable(); 169 return ret; 170 }
这个代码实在太多了,我懒得看了,直接看其它博主分析的流程图吧:
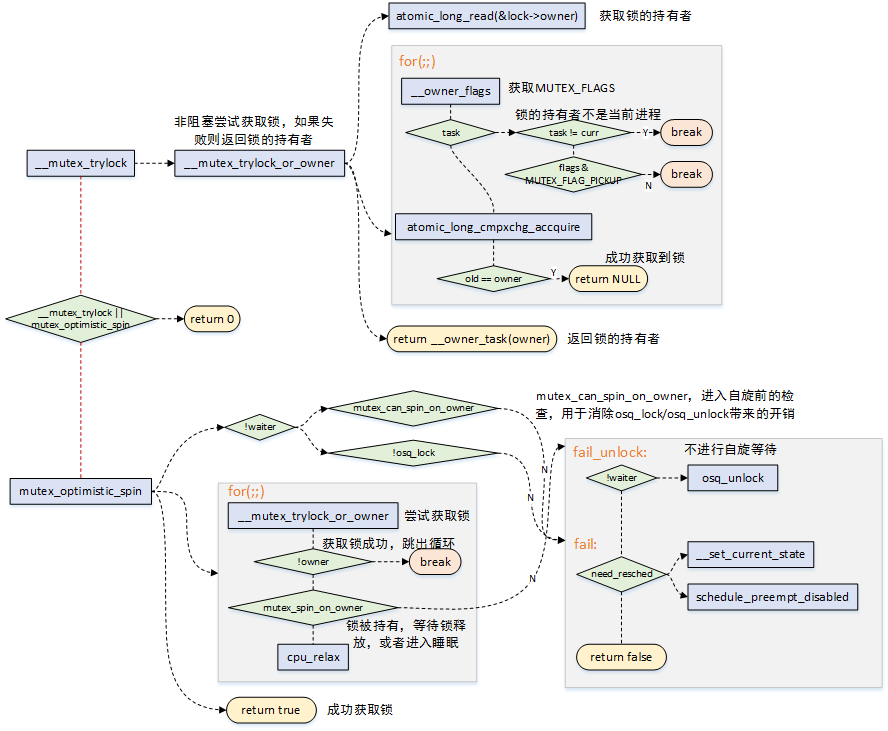
当发现mutex锁的持有者正在运行(另一个CPU)时,可以不进行睡眠调度,而可以选择自选等待,当锁持有者正在运行时,它很有可能很快会释放锁,这个就是乐观自旋的原因;
自旋等待的条件是持有锁者正在临界区运行,自旋等待才有价值;
__mutex_trylock_or_owner函数用于尝试获取锁,如果获取失败则返回锁的持有者。互斥锁的结构体中owner字段,分为两个部分:
1)锁持有者进程的task_struct(由于L1_CACHE_BYTES对齐,低位比特没有使用);
2)MUTEX_FLAGS部分,也就是对应低三位,如下:
- MUTEX_FLAG_WAITERS:比特0,标识存在非空等待者链表,在解锁的时候需要执行唤醒操作;
- MUTEX_FLAG_HANDOFF:比特1,表明解锁的时候需要将锁传递给顶部的等待者;
- MUTEX_FLAG_PICKUP:比特2,表明锁的交接准备已经做完了,可以等待被取走了;
mutex_optimistic_spin用于执行乐观自旋,理想的情况下锁持有者执行完释放,当前进程就能很快的获取到锁。实际需要考虑,如果锁的持有者如果在临界区被调度出去了,task_struct->on_cpu == 0,那么需要结束自旋等待了,否则岂不是傻傻等待了。
- mutex_can_spin_on_owner:进入自旋前检查一下,如果当前进程需要调度,或者锁的持有者已经被调度出去了,那么直接就返回了,不需要做接下来的osq_lock/oqs_unlock工作了,节省一些额外的overhead;
- osq_lock用于确保只有一个等待者参与进来自旋,防止大量的等待者蜂拥而至来获取互斥锁;
- for(;;)自旋过程中调用__mutex_trylock_or_owner来尝试获取锁,获取到后皆大欢喜,直接返回即可;
- mutex_spin_on_owner,判断不满足自旋等待的条件,那么返回,让我们进入慢速路径吧,毕竟不能强求;
3.5 slow-path
慢速路径的主要代码流程如下:

从for(;;)部分的流程可以看到,当没有获取到锁时,会调用schedule_preempt_disabled将本身的任务进行切换出去,睡眠等待,这也是它慢的原因了;
3.6 mutex_unlock
mutex_unlock释放锁流程如下图:
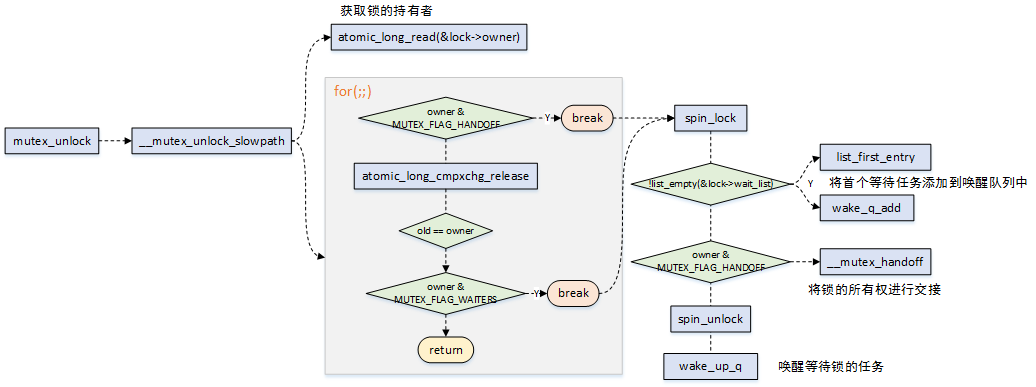
mutex_unlock定义在kernel/locking/mutex.c文件中:
/** * mutex_unlock - release the mutex * @lock: the mutex to be released * * Unlock a mutex that has been locked by this task previously. * * This function must not be used in interrupt context. Unlocking * of a not locked mutex is not allowed. * * This function is similar to (but not equivalent to) up(). */ void __sched mutex_unlock(struct mutex *lock) { #ifndef CONFIG_DEBUG_LOCK_ALLOC if (__mutex_unlock_fast(lock)) return; #endif __mutex_unlock_slowpath(lock, _RET_IP_); }
释放锁的流程相对来说比较简单,也分为快速路径与慢速路径;
快速路径是在__mutex_unlock_fast中实现:
static __always_inline bool __mutex_unlock_fast(struct mutex *lock) { unsigned long curr = (unsigned long)current; if (atomic_long_cmpxchg_release(&lock->owner, curr, 0UL) == curr) return true; return false; }
直接调用原子操作函数atomic_long_cmpxchg_release来进行判断:
- 如果lock->owner等于curr,也是锁的持有者为当前进程,则将lock->owner设置为0,并返回true;
- 如果lock->owner不等于curr,表明锁的持有者不是当前进程,返回false;
慢速路径释放锁,针对三种不同的MUTEX_FLAG来进行判断处理,并最终唤醒等待在该锁上的任务;
void __sched __mutex_unlock_slowpath(struct mutex *lock, ...) { // 释放mutex,同时获取记录状态的低3个bits unsigned long old = atomic_long_cmpxchg_release(&lock->owner, owner, __owner_flags(owner)); ... spin_lock(&lock->wait_lock); if (!list_empty(&lock->wait_list)) { // 获取等待队列中的第一个线程 struct mutex_waiter *waiter = list_first_entry (&lock->wait_list, struct mutex_waiter, list); // 将该线程加入wake_q struct task_struct *next = waiter->task; wake_q_add(&wake_q, next); } spin_unlock(&lock->wait_lock); // 唤醒该线程 wake_up_q(&wake_q); }
参考文章
[3]Linux Mutex机制分析(转载)
[5]Linux中的mutex机制[一] - 加锁和osq lock

 浙公网安备 33010602011771号
浙公网安备 33010602011771号