大数据 -- zookeeper和kafka集群环境搭建
一 运行环境
从阿里云申请三台云服务器,这里我使用了两个不同的阿里云账号去申请云服务器。我们配置三台主机名分别为zy1,zy2,zy3。
我们通过阿里云可以获取主机的公网ip地址,如下:

通过secureRCT连接主机106.15.74.155,运行ifconfig,可以查看其内网ip地址:

1、账号1申请了两台云服务器:
主机zy1的公网ip为:106.15.74.155,内网ip为172.19.182.67。
主机zy2的公网ip为:47.103.134.70,内网ip为172.19.14.178。
2、账号2申请了一台云服务器:
主机zy3的公网ip为:47.97.10.51,内网ip为172.16.229.255。
3、阿里云入规则配置
由于主机位于不同的局域网下,因此需要进行一个公网端口到内网端口的映射。在搭建zookeeper和kafka需要使用到2181,2888 ,3888,9092端口。需要在阿里云中配置入规则,具体可以参考阿里云官方收藏:同一个地域、不同账号下的实例实现内网互通 。

注意:如果47.103.134.70配置一个入端口3888,那么对该47.103.134.70:3888的访问会实际映射到172.19.14.178:3888下。如果是同一局域网下的两个主机,是不需要配置这个的,可以直接互通。
如果想了解更多,可以参考以下博客:
通过SSH访问阿里云服务器的原理可以参考-用SSH访问内网主机的方法
4、配置/etc/hosts
以主机zy1为例:配置如下:

注意zy1对应的ip需要配置为内网ip,也就是本机ip:172.19.182.67。而zy2、zy3配置的都是公网ip。
二 JDK安装
在每个主机下执行以下操作:
1、安装之前先查看一下有无系统自带jdk
rpm -qa |grep java rpm -qa |grep jdk rpm -qa |grep gcj
如果有就使用批量卸载命令
rpm -qa | grep java | xargs rpm -e --nodeps
2、直接yum安装1.8.0版本openjdk
进入 Oracle 官方网站 下载合适的 JDK 版本,准备安装:

在/usr目录下创建java目录:
mkdir /usr/java cd /usr/java
解压 JDK:
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/java
3、配置环境变量
JAVA_HOME=/usr/java/jdk1.8.0_231 JRE_HOME=/usr/java/jdk1.8.0_231/jre CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export JAVA_HOME JRE_HOME CLASS_PATH PATH
使得配置生效
. /etc/profile
4、查看版本
echo $JAVA_HOME echo $CLASSPATH java -version
三 安装zookeeper
在主机zy1下面执行以下操作:
1、下载并解压
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
创建目录/opt/bigdata:
mkdir /opt/bigdata
解压文件到/opt/bigdata:
tar -zxvf zookeeper-3.4.13.tar.gz -C /opt/bigdata
跳转目录:
cd /opt/bigdata/zookeeper-3.4.13/
2、复制配置文件
cp conf/zoo_sample.cfg conf/zoo.cfg
修改配置文件如下:
vim conf/zoo.cfg

其中部分参数意义如下:
- server.1=zy1:2888:3888:server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里。第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
- dataDir:快照日志的存储路径。
- dataLogDir:事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多。
- clientPort:这个端口就是客户端连接 zookeeper 服务器的端口,zookeeper 会监听这个端口,接受客户端的访问请求。
3、创建myid文件
创建/opt/bigdata/data/zookeeper/zkdata:
mkdir -vp /opt/bigdata/data/zookeeper/zkdata
创建myid文件:
echo 1 > /opt/bigdata/data/zookeeper/zkdata/myid
4、拷贝zookeeper到主机zy2、zy3
scp -r /opt/bigdata/zookeeper-3.4.13/ zy2:/opt/bigdata/ scp -r /opt/bigdata/zookeeper-3.4.13/ zy3:/opt/bigdata/
5、创建主机zy2、zy3的myid文件
zyx主机:
创建/opt/bigdata/data/zookeeper/zkdata:
mkdir -vp /opt/bigdata/data/zookeeper/zkdata
创建myid文件:
echo x > /opt/bigdata/data/zookeeper/zkdata/myid
注意:x表示主机的编号。
6、配置环境变量(每个主机都需要配置)
vim /etc/profile #set java environment , append export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.13 export PATH=$ZOOKEEPER_HOME/bin:$PATH
使得配置生效
. /etc/profile
7、启动服务并查看
进入到zookeeper目录下,在每个主机下分别执行
cd /opt/bigdata/zookeeper-3.4.13 bin/zkServer.sh start
检查服务状态
bin/zkServer.sh status

可以用“jps”查看zk的进程,这个是zk的整个工程的main
jps

注意:zk集群一般只有一个leader,多个follower,主一般是响应客户端的读写请求,而从同步数据,当主挂掉之后就会从follower里投票选举一个leader出来。
8、客户端连接
zookeeper服务开启后,进入客户端的命令:
zkCli.sh
更多常用命令参考博客:Kafka在zookeeper中存储结构和查看方式。
9、出现错误常用排错手段
1、防火墙
防火墙没有关闭问题。解决方式参考:https://blog.csdn.net/weiyongle1996/article/details/73733228
2、端口没有开启
如果/etc/hosts全部配置为公网:在zy1运行zkServer.sh start,查看端口开启状态:
netstat -an | grep 3888
则会发现无法开启公网3888端口,我们应该打开的是内网机器对应的端口。
如果端口已经开启,可以通过telnet ip port判断该端口是否可以从外部访问。
四 安装kafka
在主机zy1下执行:
1、下载并解压
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.1.1/kafka_2.12-2.1.1.tgz tar -zxvf kafka_2.12-2.1.1.tgz -C /opt/bigdata
重命名:
cd /opt/bigdata/ mv kafka_2.12-2.1.1 kafka
2、修改kafka配置文件
在/opt/bigdata/kafka下:
vim config/server.properties
各个参数意义:
- broker.id=1 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样;
- listeners=PLAINTEXT://主机:9092 #当前kafka对外提供服务的主机:端口(默认是9092);
- num.network.threads=3 #这个是borker进行网络处理的线程数;
- num.io.threads=8 #这个是borker进行I/O处理的线程数;
- log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个;
- socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能;
- socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘;
- socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小;
- num.partitions=1 #默认的分区数,一个topic默认1个分区数;
- log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天;
- message.max.byte=5242880 #消息保存的最大值5M;
- default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务;
- replica.fetch.max.bytes=5242880 #取消息的最大直接数;
- log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件;
- log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除;
- log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能;
- zookeeper.connect=xx:12181,xx:12181,xx:12181#设置zookeeper的连接端口;
注意,这里如果希望在java中创建topic也是多个备份,需要添加一下属性
#default replication factors for automatically created topics,默认值1;
default.replication.factor=3
#When a producer sets acks to "all" (or "-1"), this configuration specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful.
#min.insync.replicas and acks allow you to enforce greater durability guarantees,默认值1;
min.insync.replicas=3
上面是参数的解释,实际的修改项为:
broker.id=1
listeners=PLAINTEXT://zy1:9092 #内网地址
advertised.listeners=PLAINTEXT://106.15.74.155:9092 #公网地址(不然远程客户端无法访问)
log.dirs=/opt/bigdata/kafka/kafka-logs
#此外,可以在log.retention.hours=168 下面新增下面三项:
message.max.byte=5242880
default.replication.factor=2
replica.fetch.max.bytes=5242880
#设置zookeeper的连接端口
zookeeper.connect=zy1:2181,zy2:2181,zy3:2181

如果我们需要删除topic,还需要配置一下内容:
delete.topic.enable=true
具体参考博客:kafka安装及删除Topic,Kafka0.8.2.1删除topic逻辑。
3、复制kafka到zy2、zy3
scp -r /opt/bigdata/kafka zy2:/opt/bigdata/
scp -r /opt/bigdata/kafka zy3:/opt/bigdata/
4、修改zy2、zy3的配置文件server.properties
拷贝文件过去的其他两个节点需要更改broker.id和listeners,以zy2为例:

5、启动kafka
我们可以根据Kafka内带的zk集群来启动,但是建议使用独立的zk集群:
zkServer.sh start
在/opt/bigdata/kafka下 ,三个节点分别执行如下命令,启动kafka集群:
bin/kafka-server-start.sh config/server.properties &

运行命令后服务确实后台启动了,但日志会打印在控制台,而且关掉命令行窗口,服务就会随之停止,这个让我挺困惑的。后来,参考了其他的启动脚本,通过测试和调试最终找到了完全满足要求的命令。
bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
其中1>/dev/null 2>&1 是将命令产生的输入和错误都输入到空设备,也就是不输出的意思。/dev/null代表空设备。
注意:如果内存不足:打开kafka安装位置,在bin目录下找到kafka-server-start.sh文件,将export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"修改为export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"。
6、验证
思路:以下给出几条kafka指令。创建一个topic,一个节点作为生产者,两个节点作为消费者分别看看能否接收数据,进行验证:
创建及查看topic:
cd /opt/big/data/kafka bin/kafka-topics.sh --list --zookeeper zy1:2181 bin/kafka-topics.sh --create --zookeeper zy1:2181 --replication-factor 3 --partitions 3 --topic zy-test

开启生产者:
bin/kafka-console-producer.sh --broker-list zy1:9092 --topic zy-test

开启消费者:
bin/kafka-console-consumer.sh --bootstrap-server zy2:9092 --topic zy-test --from-beginning

节点zy1产生消息,如果消息没有清理,在节点zy2、zy3都可以接收到消息。
注意:更多命令的参数可以通过类似如下命令 bin/kafka-console-consumer.sh 查看。
7、更多kafka命令
以下是kafka常用命令行总结:
查看topic的详细信息
bin/kafka-topics.sh -zookeeper zy1:2181 --describe --topic zy-test

可以看到topic包含3个复本,每个副本又分为三个partition。以zy-test:partition0为例,其leader保存在broker.id=1的主机上,副本保存在2、3节点上。其消息保存在配置参数log.dirs所指定的路径下:
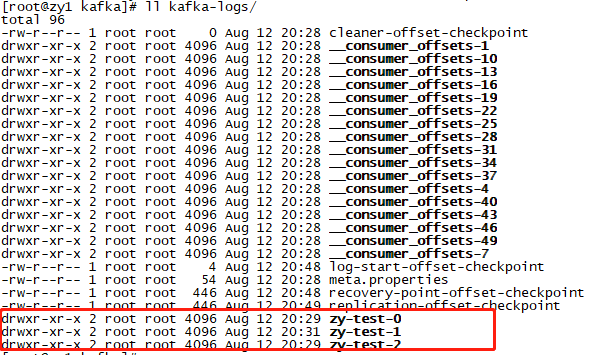
为topic增加副本
bin/kafka-reassign-partitions.sh --zookeeper zy1:2181 --reassignment-json-file json/partitions-to-move.json -execute
创建topic
bin/kafka-topics.sh --create --zookeeper zy1:2181 --replication-factor 3 --partitions 3 --topic zy-test
为topic增加partition
bin/kafka-topics.sh –-zookeeper zy1:2181 –-alter –-partitions 3 –-topic zy-test
kafka生产者客户端命令
bin/kafka-console-producer.sh --broker-list zy1:9092 --topic zy-test
kafka消费者客户端命令
bin/kafka-console-consumer.sh --bootstrap-server zy2:9092 --topic zy-test --from-beginning
kafka服务启动
bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
删除topic
bin/kafka-topics.sh --zookeeper zy1:2181 --delete --topic zy-test
8、关闭kafka
bin/kafka-server-stop.sh
五 consumer offsets
由于Zookeeper并不适合大批量的频繁写入操作,新版Kafka已推荐将consumer的位移信息保存在kafka内部的topic中,即__consumer_offsets topic,并且默认提供了kafka_consumer_groups.sh脚本供用户查看consumer信息。
1、获取消息在topic中的记录信息
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list zy1:9092 --topic zy-test

输出结果每个字段分别表示topic、partition、untilOffset(当前partition的最大偏移);
上面的输出结果表明kafka队列总有产生过4条消息(这并不代表kafka队列现在一定有4条消息,因为kafka有两种策略可以删除旧数据:基于时间、基于大小)。
由于我使用kafka-console-producer.sh生成了四条消息:zy、19941108、 liuyan、1。因此kafka消息队列中存在4条消息。
2、创建一个console consumer group
bin/kafka-console-consumer.sh --bootstrap-server zy1:9092 --consumer.config config/consumer.properties --topic zy-test --from-beginning
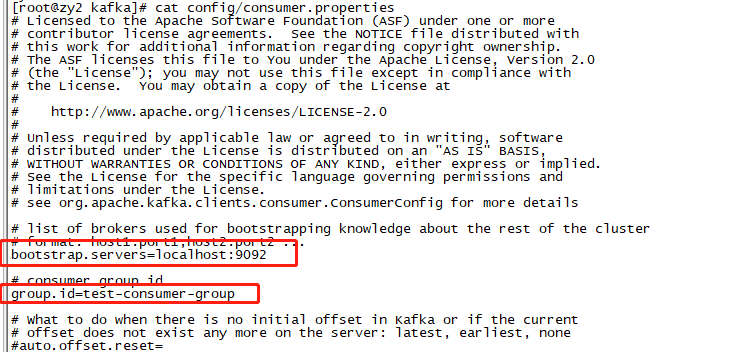

再次建立消费者:

会发现获取不到数据。这是因为我们指定了消费组,第一次消费时从offset为0开始消费,把4条消息全部读出,此时offset移动到最后,当再次使用同一消费组读取数据,则会从上次的offset开始获取数据。
而使用:
bin/kafka-console-consumer.sh --bootstrap-server zy1:9092 --topic zy-test --from-beginning
每次都会获取四条数据,这是因为每次都会创建一个新的消费者,这些消费者会被随机分配到一个不同的组,因此每次都是从offset为0开始消费。
参数解释:

3、 获取该consumer group的group id
bin/kafka-consumer-groups.sh --bootstrap-server zy1:9092 --list

可以看到有三个消费组,前两个消费者没有指定消费组,随机产生一个console-consumer-***的group.ig。
第三个是我们刚刚在config/consumer.properties 中指定的消费组。
4、查看消费者组的offset
bin/kafka-consumer-groups.sh --bootstrap-server zy1:9092 --describe --group test-consumer-group

如果此时再使用生产者客户端生成两条消息:

再次查看消费组test-consumer-group的消费情况:

5、KAFKA API指定位移消费
由于我们还没有介绍KAFKA的API,这块内容就不先介绍,具体参考博客:Kafka消费者 之 指定位移消费。
六 各个端口作用
- 2888:zookeeper集群三台主机心跳端口;
- 3888:zookeeper集群三台主机选取leader端口,防止其中一个宕机了;
- 2181:zookeeper服务器监听端口,等待消费者连接,消费者可以从中获取topic分区以及消费offset等信息(高版本消费者offset已经保存在kafka内部的topic中了);
- 9092:kafka服务器绑定端口,等待生产者和消费者连接;
因此上面介绍的kafka命令,与topic相关的使用--zookeeper zy1:2181,与生产者、消费者相关的使用 --bootstrap-server zy1:9092。
参考博客:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号