

4.18python
一、今日学习内容
使用 requests 库请求网站
爬虫的基本原理
网页请求的过程分为两个环节:
- Request (请求):每一个展示在用户面前的网页都必须经过这一步,也就是向服务器发送访问请求。
- Response(响应):服务器在接收到用户的请求后,会验证请求的有效性,然后向用户(客户端)发送响应的内容,客户端接收服务器响应的内容,将内容展示出来,就是我们所熟悉的网页请求,如图 8 所示。


图 8 Response相应
网页请求的方式也分为两种:
- GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
- POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
所以,在写爬虫前要先确定向谁发送请求,用什么方式发送。
使用 GET 方式抓取数据
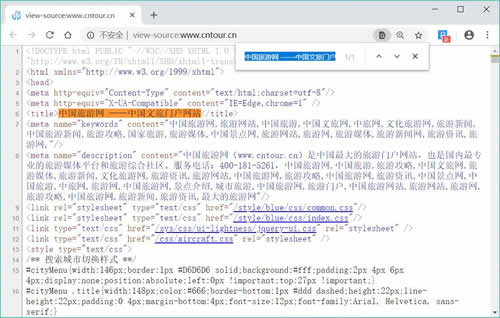
复制任意一条首页首条新闻的标题,在源码页面按【Ctrl+F】组合键调出搜索框,将标题粘贴在搜索框中,然后按【Enter】键。
如图 8 所示,标题可以在源码中搜索到,请求对象是www.cntour.cn,请求方式是GET(所有在源码中的数据请求方式都是GET),如图 9 所示。

确定好请求对象和方式后,在 PyCharm 中输入以下代码:
- import requests #导入requests包
- url = 'http://www.cntour.cn/'
- strhtml = requests.get(url) #Get方式获取网页数据
- print(strhtml.text)
运行结果如图 10 所示:
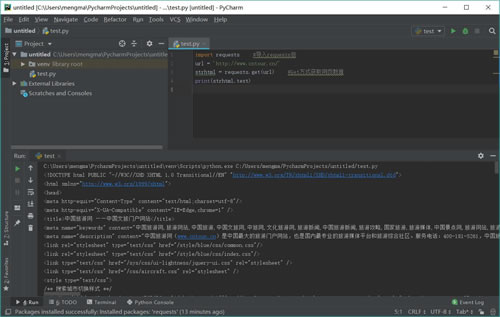
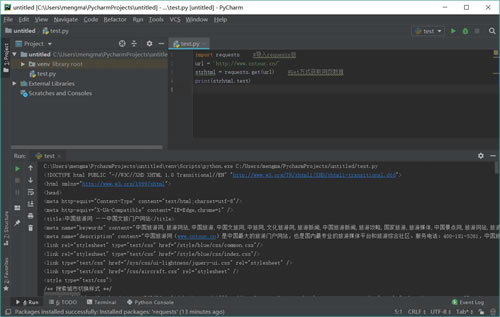
加载库使用的语句是 import+库的名字。在上述过程中,加载 requests 库的语句是:import requests。
用 GET 方式获取数据需要调用 requests 库中的 get 方法,使用方法是在 requests 后输入英文点号,如下所示:
requests.get
将获取到的数据存到 strhtml 变量中,代码如下:
strhtml = request.get(url)
这个时候 strhtml 是一个 URL 对象,它代表整个网页,但此时只需要网页中的源码,下面的语句表示网页源码:
strhtml.text
使用 POST 方式抓取数据
首先输入有道翻译的网址:http://fanyi.youdao.com/,进入有道翻译页面。
按快捷键 F12,进入开发者模式,单击 Network,此时内容为空,如图 11 所示:
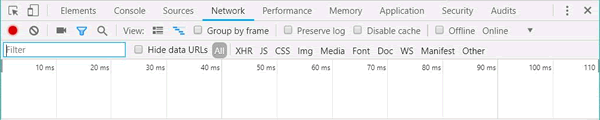
图 11
在有道翻译中输入“我爱中国”,单击“翻译”按钮,如图 12 所示:
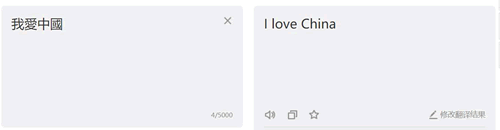

图 12
在开发者模式中,依次单击“Network”按钮和“XHR”按钮,找到翻译数据,如图 13 所示:
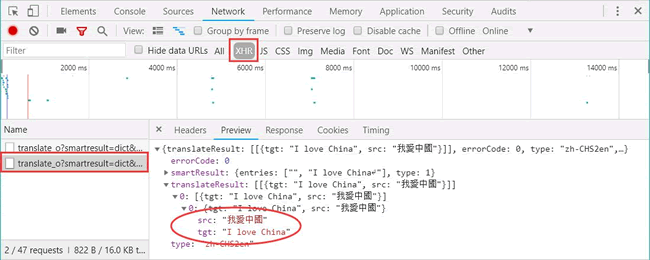
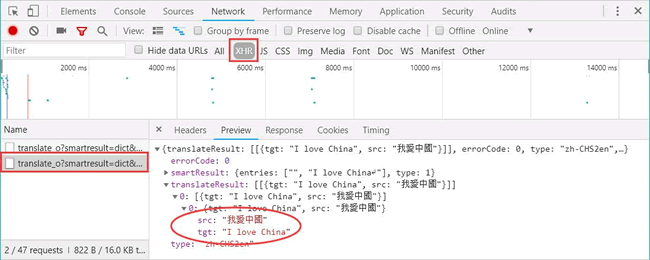
图 13
单击 Headers,发现请求数据的方式为 POST。如图 14 所示:
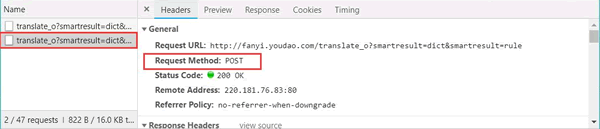
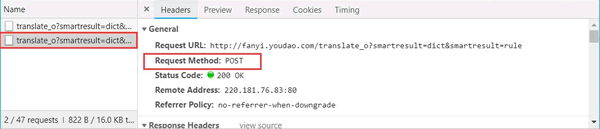
图 14
找到数据所在之处并且明确请求方式之后,接下来开始撰写爬虫。
首先,将 Headers 中的 URL 复制出来,并赋值给 url,代码如下:
url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
POST 的请求获取数据的方式不同于 GET,POST 请求数据必须构建请求头才可以。
Form Data 中的请求参数如图 15 所示:
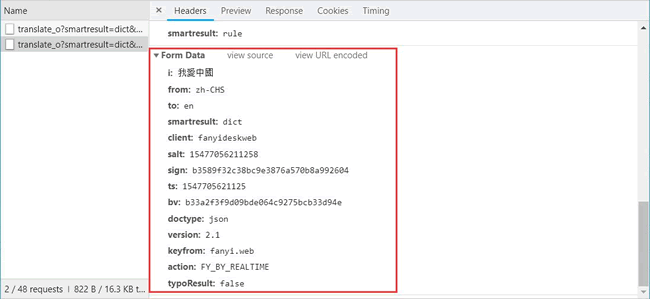
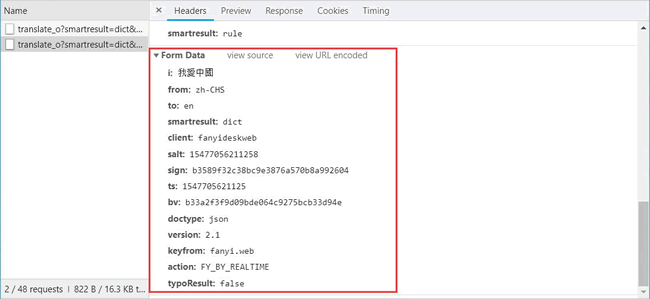
图 15
将其复制并构建一个新字典:
From_data={'i':'我愛中國','from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
接下来使用 requests.post 方法请求表单数据,代码如下:
import requests #导入requests包
response = requests.post(url,data=payload)
将字符串格式的数据转换成 JSON 格式数据,并根据数据结构,提取数据,并将翻译结果打印出来,代码如下:
- import json
- content = json.loads(response.text)
- print(content['translateResult'][0][0]['tgt'])
使用 requests.post 方法抓取有道翻译结果的完整代码如下:
- import requests #导入requests包
- import json
- def get_translate_date(word=None):
- url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
- From_data={'i':word,'from':'zh-CHS','to':'en','smartresult':'dict','client':'fanyideskweb','salt':'15477056211258','sign':'b3589f32c38bc9e3876a570b8a992604','ts':'1547705621125','bv':'b33a2f3f9d09bde064c9275bcb33d94e','doctype':'json','version':'2.1','keyfrom':'fanyi.web','action':'FY_BY_REALTIME','typoResult':'false'}
- #请求表单数据
- response = requests.post(url,data=From_data)
- #将Json格式字符串转字典
- content = json.loads(response.text)
- print(content)
- #打印翻译后的数据
- #print(content['translateResult'][0][0]['tgt'])
- if __name__=='__main__':
- get_translate_date('我爱中国')
二、遇到的问题
暂无
三、明日计划
继续python学习


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· [翻译] 为什么 Tracebit 用 C# 开发
· 腾讯ima接入deepseek-r1,借用别人脑子用用成真了~
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· DeepSeek崛起:程序员“饭碗”被抢,还是职业进化新起点?
· 深度对比:PostgreSQL 和 SQL Server 在统计信息维护中的关键差异