3.Java并发编程-Java多线程之线程安全
线程安全
当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些进程如何交替执行,并且在主调代码中,不需要任何额外的同步或协同,这个类都能表现出正确的行为,那么就称这个类是线程安全的。
线程安全特性
- 原子性:同一时刻只能有一个线程对它进行操作。
- 可见性:一个线程对主内存的修改,可以及时的被其他线程观察到。
- 有序性:一个线程观察其他线程的指令执行顺序,由于指令重排序的存在,该观察结果一般杂乱无序。
原子性:
一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
Atomic类:
Atomic包采用CAS算法:
public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
var1为操作的对象,var2为该对象当前值,var4为该对象增加值,var5为底层当前值。
CAS(Compare And Swap)实现的核心原理:用当前对象的值(工作内存)与底层(主内存)的值进行对比,如果当前值等于底层值,则执行对应的操作,如果不相等,则继续循环取值,直到相等(死循环),不断进行循环尝试。
CAS的操作过程:CAS比较的过程可以通俗的理解为CAS(V,O,N),包含三个值分别为:V内存地址实际存放的值;O预期的值(旧值),N更新的新值,当V和O相同时,也就是说明旧值和内存中实际的值相同,表明该值没有被其他线程修改过,即该旧值就是目前来说最新的值了,自然可以将新值N赋值给V,反之V和O不相同,表明该值已经被其他线程修改过,则该旧值O不是最新的版本,所以不能将该值N赋值给V,返回V即可,当多个线程使用CAS操作一个变量时,只有一一个线程会成功,并成功更新,其余会失败,失败的线程会重新尝试,当然也可以选择挂起线程。
原子类型划分
普通原子类型:提供对boolean、int、long和对象的原子性操作:AtomicBoolean、AtomicInteger、AtomicLong、AtomicReference
AtomicBoolean
//ThreadSafe public class AtomicBooleanTest { private static AtomicBoolean isHappened = new AtomicBoolean(false); public static int clientTotal = 5000;// 请求总数 public static int threadTotal = 200;// 同时并发执行的线程数 public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal ; i++) { executorService.execute(() -> { try { semaphore.acquire(); method(); semaphore.release(); } catch (Exception e) { e.printStackTrace(); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); System.out.println("isHappened: " + isHappened.get()); } private static void method() { if (isHappened.compareAndSet(false, true)) { System.out.println("executing..."); } } }
AtomicInteger:
//ThreadSafe public class AtomicIntegerTest { public static int clientTotal = 5000;// 请求总数 public static int threadTotal = 200;// 同时并发执行的线程数 public static AtomicInteger count = new AtomicInteger(0); public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal ; i++) { executorService.execute(() -> { try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { e.printStackTrace(); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); System.out.println("count:" + count.get()); } private static void add() { count.incrementAndGet(); // count.getAndIncrement(); } }
AtomicLong
//ThreadSafe public class AtomicLongTest { public static int clientTotal = 5000;// 请求总数 public static int threadTotal = 200;// 同时并发执行的线程数 public static AtomicLong count = new AtomicLong(0); public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal ; i++) { executorService.execute(() -> { try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { e.printStackTrace(); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); System.out.println("count:" + count.get()); } private static void add() { count.incrementAndGet(); // count.getAndIncrement(); } }
AtomicReference
//ThreadSafe
public class AtomicReferenceTest {
private static AtomicReference<Integer> count = new AtomicReference<>(0);
public static void main(String[] args) {
count.compareAndSet(0, 2); // 2
count.compareAndSet(0, 1); // no
count.compareAndSet(1, 3); // no
count.compareAndSet(2, 4); // 4
count.compareAndSet(3, 5); // no
System.out.println("result: " + count.get());//4
}
}
原子类型数组:提供对数组元素的原子性操作。AtomicLongArray、AtomicIntegerArray、AtomicReferenceArray
AtomicLongArray
AtomicIntegerArray
AtomicReferenceArray
AtomicLong与LongAdder
AtomicLong的原理是依靠底层的cas来保障原子性的更新数据(在死循环内不断尝试修改目标值,直至修改成功),在要添加或者减少的时候,会使用自循(CLH)方式不断地cas到特定的值,从而达到更新数据的目的。然而在线程竞争激烈的情况下,自循往往浪费很多计算资源才能达成预期效果。
对于普通类型的变量long,double类型的变量,JVM允许将64位的读操作或写操作拆成两个32位的操作。
LongAdder将热点数据分离(将AtomicLong的内部核心数据value分离成一个数组,每个线程访问时,通过hash等算法映射到其中一个数字进行计数,最终的技术结果则为这个数组的求和累加,其中热点数据的value被分离成多个单元的cell,每个cell独自维护内部的值,当前对象的实际值由多个cell累计合成,这样热点就进行了有效的分离,提高了并行度,在AtomicLong的基础上,将单点的更新压力分散到各个节点上,在低并发的情况下,通过对base的直接更新,可以保障和AtomicLong的性能基本一致,而在高并发的情况下则通过分散提高了性能)。
LongAdder的缺点:如果在统计的时候有并发更新,则可能会导致统计的数据存在误差。
|
|
|
|
|
|
|
原子类型字段更新器:提供对指定对象的指定字段进行原子性操作 |
AtomicLongFieldUpdater AtomicIntegerFieldUpdater AtomicReferenceFieldUpdater |
|
带版本号的原子引用类型:以版本戳的方式解决原子类型的ABA问题 |
AtomicStampedReference AtomicMarkableReference |
|
原子累加器(JDK1.8):AtomicLong和AtomicDouble的升级类型,专门用于数据统计,性能更高 |
DoubleAccumulator DoubleAdder LongAccumulator LongAdder |
LongAdder
//ThreadSafe
public class LongAdderTest{
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
public static LongAdder count = new LongAdder();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
e.printStackTrace();
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("count:" + count);
}
private static void add() {
count.increment();
}
}AtomicIntegerFieldUpdater
//ThreadSafe
@Data
public class AtomicIntegerFieldUpdaterTest {
private static AtomicIntegerFieldUpdater<AtomicIntegerFieldUpdaterTest> updater =
AtomicIntegerFieldUpdater.newUpdater(AtomicIntegerFieldUpdaterTest.class, "count");
@Getter
public volatile int count = 100;
public static void main(String[] args) {
AtomicIntegerFieldUpdaterTest example = new AtomicIntegerFieldUpdaterTest();
if (updater.compareAndSet(example, 100, 120)) {
System.out.println("update success 1 : " + example.getCount());
}
if (updater.compareAndSet(example, 100, 120)) {
System.out.println("update success 2 : " + example.getCount());
} else {
System.out.println("update failed : " + example.getCount());
}
}
}update success 1 : 120
update failed : 120
ABA问题:
CAS机制的原理由CPU支持的原子操作,其原子性是在硬件层面进行保证的。
而CAS机制可能会出现ABA问题,即T1读取内存变量为A,T2修改内存变量为B,T2修改内存变量为A,这时T1再CAS操作A时是可行的。但实际上在T1第二次操作A时,已经被其他线程修改过了。
解决方案:添加版本号。
锁实现原子性:
|
synchronized |
依赖JVM。在类的继承过程中synchronized不具有传递性。synchronized不属于方法声明的一部分。 |
|
lock |
依赖特殊的CPU指令,代码实现,如ReenTrantLock; |
原子性对比:
|
Atomic |
竞争激烈时能维持常态,比lock性能好,只能同步一个值。 |
|
synchronized |
不可中断锁,适合竞争不激烈,可读性好。 |
|
Lock |
可中断锁,多样化同步,竞争激烈时能维持常态。 |
可见性:
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
导致共享变量在线程不可见的原因:
|
线程交叉执行。 |
|
重排序结合线程交叉执行。 |
|
共享变量更新后的值没有在工作内存与主存之间及时更新。 |
synchronized关键字
JMM关于synchronized的两条规定:
|
线程解锁前必须把共享变量的值刷新到主内存。 |
|
线程加锁时,将清空工作内存中共享变量的值,从而使用共享变量时需要从主内存中重新读取最新的值,注意(加锁与解锁是同一把锁)。 |
volatile关键字
根据JMM,Java中有一块主内存,不同的线程有自己的工作内存,同一个变量值在主内存中只有一份,如果线程用到了这个变量的话,自己的工作内存中有一份一模一样的拷贝。每次进入线程从主内存中拿到变量值,每次执行完线程将变量从工作内存同步回主内存中。
volatile解决的是变量在多个线程之间的可见性,但是无法保证原子性。
public class VolatileTest {
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
public static volatile int count = 0;
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
add();
semaphore.release();
} catch (Exception e) {
System.out.println("exception" + e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println("count:" + count); //count!=5000
}
private static void add(){
count++;
}
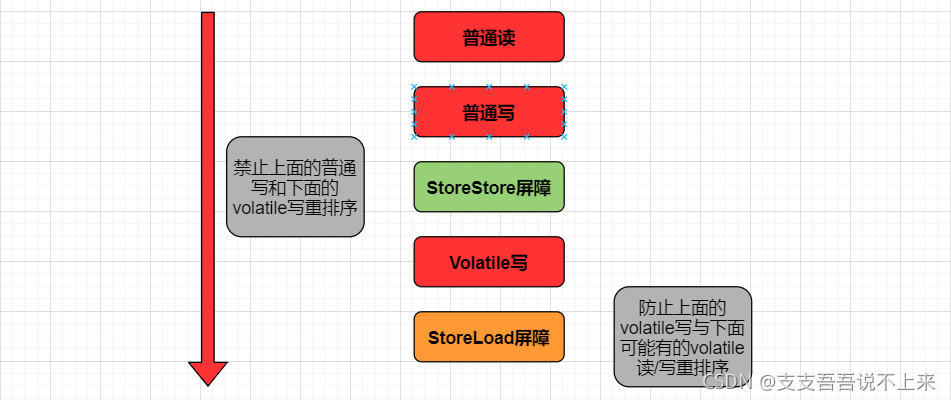
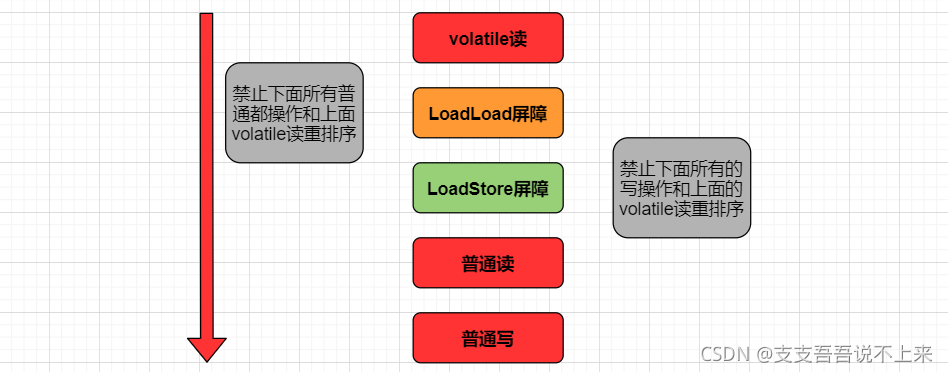
}volatile的可见性是通过加入内存屏障和禁止重排序来实现。
|
对volatile进行写操作时,会在写操作后加入一条store屏障指令,将本地内存中的共享变量值刷新到主内存。 |
|
对volatile进行读操作时,会在写操作后加入一条load屏障指令,从主内存中读取共享变量。 |
可见性-volatile写示意图:
可见性-volatile读示意图:
注意:volatile不能保证原子性;
|
对变量的写操作不依赖于当前值。 |
|
对于该变量的值没有包含在具有其他变量的不变的式子在中。 |
可见性--volatile的使用:(作为状态标识量)
volatile boolean inited = false;
//线程1
context = loadContext();
inited = true;
//线程2
while(!inited){
sleep;
}
doSomethingWithConfig(context);有序性
|
Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程的执行,但却会影响到多线程并发执行的正确性。 |
|
通过 volatile、synchronized、lock保证可见性,synchronized、lock保证同一时刻只有一个线程执行代码,从而保证有序性。 |
先天有序性-- happens-before原则:
|
程序次序规则 |
一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作。 |
|
锁定规则 |
一个unlock操作先行发生于后面对同一个锁的lock操作。 |
|
volatile变量规则 |
对一个变量的写操作先行发生于后面对这个变量的读操作。 |
|
传递规则 |
如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C。 |
|
线程启动规则 |
Thread对象的start()方法先行发生于此线程的每一个动作。 |
|
线程中断规则 |
对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生。 |
|
线程中断规则 |
线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行。 |
|
对象终结规则 |
一个对象的初始化完成先行发生于他的finalize()方法开始。 |
安全发布对象
发布对象
使一个对象能够被当前范围之外的代码所使用。
//NotThreadSafe
public class UnsafePublish {
private String[] states = {"a", "b", "c"};
public String[] getStates() {//public 其他线程可修改该域
return states;
}
public static void main(String[] args) {
UnsafePublish unsafePublish = new UnsafePublish();
System.out.println(Arrays.toString(unsafePublish.getStates()));
unsafePublish.getStates()[0] = "d";//对私有属性修改
System.out.println(Arrays.toString(unsafePublish.getStates()));
}
}对象逸出
一种错误的发布,当一个对象还没有构造完成时,就使它被其他线程所见。
//对象在没有正确完成构造之前被发布
//NotThreadSafe
//NotRecommend
public class Escape {
private int thisCanBeEscape = 0;
public Escape () {
new InnerClass();//启动一个线程,新线程在所属对象构造完成之前已经看到this
}
private class InnerClass {
public InnerClass() {
System.out.println(Escape.this.thisCanBeEscape);//this引用逸出
}
}
public static void main(String[] args) {
new Escape();
}
}安全发布对象的四种方法
|
在静态初始化函数中初始化一个对象引用。 |
|
将对象的引用保存到volatile类型域或者AtomicReference对象中。 |
|
将对象的引用保存到某个正确构造对象的final类型域中。 |
|
将对象的引用保存到一个由锁保护的域中。 |
代码参考设计模式单例模式。
线程安全策略
不可变对象
只要对象发布,它就是线程安全的。
不可变需要满足的条件:
|
条件 |
实现 |
|
对象创建以后其状态就不能修改; 对象所有域都是final类型; 对象是正确创建的(在创建期间,this引用没有逸出); |
将类声明为final,不可以被继承。 将所有成员声明为私有,不允许直接访问成员。 对变量不提供set方法,将所有可变的成员声明为final。 通过构造器初始化所有成员,进行深度拷贝。 在get方法中不返回对象的本身,而是克隆对象,并返回对象的引用。 |
final关键字:修饰类、方法、变量
|
修饰类 |
不能被继承。 |
|
|
修饰方法 |
锁定方法不能被继承类修改。 |
|
|
修饰变量 |
基本数据类型变量 |
变量初始化以后要不可以被修改。 |
|
引用类型变量 |
初始化之后不可以指向新的引用,但是可以修改对象内的值(线程不安全)。 |
|
Collections提供的不可变对象
Collections.unmodifiableXXX:Collection、List、Set、Map...
根据原来的集合创建一个新的Unmodifiable集合,并且Unmodifiable集合的操作方法throw new UnsupportedOperationException()。
//ThreadSafe
public class CollectionsTest {
private static Map<Integer, Integer> map = new HashMap();
static {
map.put(1, 2);
map.put(3, 4);
map.put(5, 6);
map = Collections.unmodifiableMap(map);
}
public static void main(String[] args) {
map.put(1, 3);
System.out.print(map.get(1));
}
}Guava提供的不可变对象
ImmutableXXX:Collection、List、Set、Map...
通过重写集合的操作方法抛出异常UnsupportedOperationException。
//ThreadSafe
public class ImmutableTest{
private final static ImmutableList<Integer> list = ImmutableList.of(1, 2, 3);
private final static ImmutableSet set = ImmutableSet.copyOf(list);
private final static ImmutableMap<Integer, Integer> map = ImmutableMap.of(1, 2, 3, 4);
private final static ImmutableMap<Integer, Integer> map2 = ImmutableMap.<Integer, Integer>builder()
.put(1, 2).put(3, 4).put(5, 6).build()
public static void main(String[] args) {
System.out.println(map2.get(3));
}
}线程封闭
当访问共享的可变数据时,通常需要同步。一种避免同步的方式就是不共享数据。如果仅在单线程内访问数据,就不需要同步,这种技术称为线程封闭(thread confinement)。(把对象封装到一个线程里,只有一个线程可以看到这个对象。就算 对象不是线程安全的,也不会出现任何线程安全仿方面的问题)。
|
Ad-hoc线程封闭 |
程序控制实现、最糟糕。 |
|
堆栈封闭 |
局部变量、无并发问题(局部变量被拷贝至线程栈中,因此局部变量不会被线程共享)。 |
|
ThreadLocal类 |
特别好的线程封闭。 |
ThreadLocal线程封闭
每个Thread线程内部都有一个Map,这个Map以线程本地对象作为key,以线程的对象副本作为value,同时这个Map由ThreadLocal来维护,ThreadLocal来负责向Map设置线程的变量值及获取值,所以对于不同的线程每次获取副本值的时候,别的线程并不能获取当前线程的副本值,于是就形成了副本的隔离,做到了多个线程互不干扰。
三个理论基础
|
每个线程都有一个自己的ThreadLocal.ThreadLocalMap对象。 |
|
每一个ThreadLocal对象都有一个循环计数器。 |
|
ThreadLocal.get()取值,就是根据当前的线程,获取线程中自己的ThreadLocal.ThreadLocalMap,然后在这个Map中根据第二点中循环计数器取得一个特定value值。 |
两个数学问题
|
ThreadLocal.ThreadLocalMap规定了table的大小必须是2的N次幂。 |
|
Hash增量设置为0x61c88647,也就是说ThreadLocal通过取模的方式取得table的某个位置的时候,会在原来的threadLocalHashCode的基础上加上0x61c88647。 |
总结
|
ThreadLocal不需要key,因为线程里面自己的ThreadLocal.ThreadLocalMap不是通过链表法实现的,而是通过开地址法实现的。 |
|
每次set的时候往线程里面的ThreadLocal.ThreadLocalMap中的table数组某一个位置塞一个值,这个位置由ThreadLocal中的threadLocaltHashCode取模得到,如果位置上有数据了,就往后找一个没有数据的位置。 |
|
每次get的时候也一样,根据ThreadLocal中的threadLocalHashCode取模,取得线程中的ThreadLocal.ThreadLocalMap中的table的一个位置,看一下有没有数据,没有就往下一个位置找。 |
|
既然ThreadLocal没有key,那么一个ThreadLocal只能塞一种特定数据。如果想要往线程里面的ThreadLocal.ThreadLocalMap里的table不同位置塞数据 ,比方说想塞三种String、一个Integer、两个Double、一个Date,请定义多个ThreadLocal,ThreadLocal支持泛型"public class ThreadLocal<T>"。 |
ThreadLocal的作用
|
ThreadLocal不是用来解决共享对象的多线程访问问题的。 |
|
通过ThreadLocal的set()方法设置到线程的ThreadLocal.ThreadLocalMap里的是是线程自己要存储的对象,其他线程不需要去访问,也是访问不到的。各个线程中的ThreadLocal.ThreadLocalMap以及ThreadLocal.ThreadLocal中的值都是不同的对象。 |
总结
|
ThreadLocal不是集合,它不存储任何内容,真正存储数据的集合在Thread中。ThreadLocal只是一个工具,一个往各个线程的ThreadLocal.ThreadLocalMap中table的某一位置set一个值的工具而已。 |
|
同步与ThreadLocal是解决多线程中数据访问问题的两种思路,前者是数据共享的思路,后者是数据隔离的思路。 |
|
同步是一种以时间换空间的思想,ThreadLocal是一种空间换时间的思想。 |
|
ThreadLocal既然是与线程相关的,那么对于Java Web来讲,ThreadLocal设置的值只在一次请求中有效。 |
线程安全的类与线程不安全的类
线程安全的类
|
线程不安全的类 |
对应的线程安全的类 |
|
StringBuilder |
StringBuffer |
|
SimpleDateFormat |
JodaTime |
线程不安全的类
线程不安全的类:如果一个类的对象同时可以被多个线程访问,如果不做同步或者特殊的并发处理,那么它就很容易表现出线程不安全的现象(抛出异常,逻辑处理错误等等)。
先检查再执行:线程不安全的点在于分成两个操作之后,即使每一个操作是线程安全的,但是在间隙过程中不是原子性的。
if (condition(a)){//如果两个线程同时访问到该条件就会出现线程不安全问题
handle(a);
}String、StringBuilder、StringBuffer
public class StringBuilderBufferTest {
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
public static StringBuilder stringBuilder = new StringBuilder();//@NotThreadSafe
//public static StringBuffer stringBuilder = new StringBuffer();//@ThreadSafe
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
update();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", stringBuilder.length());
}
private static void update() {
stringBuilder.append("1");
}
}这三个类之间的区别主要是在两个方面,即运行速度和线程安全这两方面:
运行速度快慢为:StringBuilder > StringBuffer > String
String最慢的原因
String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,而StringBuilder和StringBuffer的对象是变量,对变量进行操作就是直接对该对象进行更改,而不进行创建和回收的操作,所以速度要比String快很多。
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的。
如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder。
|
String |
适用于少量的字符串操作的情况。 |
|
StringBuilder |
适用于单线程下在字符缓冲区进行大量操作的情况。 |
|
StringBuffer |
适用多线程下在字符缓冲区进行大量操作的情况 |
SimpleDateFormat、JodaTime、FastDateFormat
public class DateFormatTest {
//@NotThreadSafe
private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMdd");
//@ThreadSafe
//private static DateTimeFormatter dateTimeFormatter = DateTimeFormat.forPattern("yyyyMMdd");
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal ; i++) {
executorService.execute(() -> {
try {
semaphore.acquire();
update();
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
}
private static void update() {
try {
//@ThreadSafe 堆栈封闭
//SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMdd");
simpleDateFormat.parse("20180208");
} catch (Exception e) {
log.error("parse exception", e);
}
}
}总结
|
SimpleDateFormat是线程不安全的,不能多个线程公用。 |
|
FastDateFormat是线程安全的,可以直接使用,不必考虑多线程的情况。 |
|
Joda-Time与以上两种有所区别,不仅仅可以对时间进行格式化输出,而且可以生成瞬时时间值,并与Calendar、Date等对象相互转化,极大的方便了程序的兼容性。 |
|
Joda-Time的类具有不可变性,因此他们的实例是无法修改的,就跟String的对象一样。 |
ArrayList, HashSet, HashMap均为线程不安全类
同步容器
|
线程不安全 |
线程安全 |
|
ArrayList |
Vector, Stack |
|
HashMap |
HashTable(key、value不能为null) |
|
Collection.synchronizedXXX(List、Set、Map) |
同步容器中主要使用synchronized实现同步。
//ThreadSafe
public class CollectionsSyncTest {
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
private static Map<Integer, Integer> map = Collections.synchronizedMap(new HashMap<>());
private static List<Integer> list = Collections.synchronizedList(Lists.newArrayList());
private static Set<Integer> set = Collections.synchronizedSet(Sets.newHashSet());
private static Map<Integer, Integer> map = new Hashtable<>();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", list.size());
}
private static void update(int i) {
list.add(i);
//set.add(i);
//map.put(i,i);
}
}同步容器不能保证线程安全,在某些情况下也会表现出线程不安全的状态(Vector增加与删除同步进行,会导致数组下标越界)。
对于集合类型的变量再遍历的时候不要做更新操作,如果需要更新,则建议做好标记,遍历完之后在做跟新操作;
推荐使用for循环做遍历时跟新操作。
并发容器
|
线程不安全 |
线程安全 |
|
ArrayList |
CopyOnWriteArrayList |
|
HashSet |
CopyOnWriteArraySet |
|
TreeSet |
ConcurrentSkipListSet |
|
HashMap |
ConcurrentHashMap |
|
TreeMap |
ConcurrentSkipListMap |
CopyOnWriteArrayList
CopyOnWriteArrayList 类的所有可变操作(add,set等等)都是通过创建底层数组的新副本来实现的。当 List 需要被修改的时候,并不直接修改原有数组对象,而是对原有数据进行一次拷贝,将修改的内容写入副本中。写完之后,再将修改完的副本替换成原来的数据,这样就可以保证写操作不会影响读操作了。
//ThreadSafe
public class CopyOnWriteArrayListTest {
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200; // 同时并发执行的线程数
private static List<Integer> list = new CopyOnWriteArrayList<>();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", list.size());
}
private static void update(int i) {
list.add(i);
}
}从 CopyOnWriteArrayList 的名字可以看出,CopyOnWriteArrayList 是满足 CopyOnWrite 的 ArrayList,所谓 CopyOnWrite 的意思:就是对一块内存进行修改时,不直接在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后,再将原来指向的内存指针指到新的内存,原来的内存就可以被回收。
|
CopyOnWriteArrayList 读取操作的实现 |
读取操作没有任何同步控制和锁操作,理由就是内部数组 array 不会发生修改,只会被另外一个 array 替换,因此可以保证数据安全。 |
|
CopyOnWriteArrayList 写入操作的实现 |
CopyOnWriteArrayList 写入操作 add() 方法在添加集合的时候加了锁,保证同步,避免多线程写的时候会 copy 出多个副本。 |
CopyOnWriteArraySet
HashSet的底层存储结构是一个HashMap,并且HashSet的元素作为该Map的Key进行存储,HashMap的Key的存储是无序并且不可重复,这就解释了HashSet中如何保证元素不重复;
CopyOnWriteArraySet的底层存储结构其实是CopyOnWriteArrayList,它支持并发的原理跟CopyOnWriteArrayList是一样的。
@ThreadSafe
public class CopyOnWriteArraySetExample {
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
private static Set<Integer> set = new CopyOnWriteArraySet<>();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", set.size());
}
private static void update(int i) {
set.add(i);
}
}ConcurrentSkipListSet
ConcurrentSkipListSet是线程安全的有序的集合,适用于高并发的场景。
ConcurrentSkipListSet和TreeSet,它们虽然都是有序的集合。它们有以下区别:
|
它们的线程安全机制不同,TreeSet是非线程安全的,而ConcurrentSkipListSet是线程安全的。 |
|
ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,而TreeSet是通过TreeMap实现的。 |
ConcurrentSkipListSet的批量操作不保证线程安全,批量操作底层调用的还是add().remove()等方法,不能保证操作时不会被其他线程打断;
//ThreadSafe
public class ConcurrentSkipListSetTest {
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
private static Set<Integer> set = new ConcurrentSkipListSet<>();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", set.size());
}
private static void update(int i) {
set.add(i);
}
}ConcurrentHashMap
ConcurrentHashMap采取了“锁分段”技术来细化锁的粒度:把整个map划分为一系列被成为segment的组成单元,一个segment相当于一个小的hashtable。
这样,加锁的对象就从整个map变成了一个更小的范围——一个segment。ConcurrentHashMap线程安全并且提高性能原因就在于:对map中的读是并发的,无需加锁;
只有在put、remove操作时才加锁,而加锁仅是对需要操作的segment加锁,不会影响其他segment的读写,由此,不同的segment之间可以并发使用,极大地提高了性能。
//ThreadSafe
public class ConcurrentHashMapExample {
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
private static Map<Integer, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", map.size());
}
private static void update(int i) {
map.put(i, i);
}
}ConcurrentSkipListMap
TreeMap使用红黑树按照key的顺序(自然顺序、自定义顺序)来使得键值对有序存储,但是只能在单线程下安全使用;多线程下想要使键值对按照key的顺序来存储,则需要使用ConcurrentSkipListMap。
ConcurrentSkipListMap的底层是通过跳表来实现的。跳表是一个链表,但是通过使用“跳跃式”查找的方式使得插入、读取数据时复杂度变成了O(logn)。
//ThreadSafe
public class ConcurrentSkipListMapTest {
public static int clientTotal = 5000;// 请求总数
public static int threadTotal = 200;// 同时并发执行的线程数
private static Map<Integer, Integer> map = new ConcurrentSkipListMap<>();
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
final Semaphore semaphore = new Semaphore(threadTotal);
final CountDownLatch countDownLatch = new CountDownLatch(clientTotal);
for (int i = 0; i < clientTotal; i++) {
final int count = i;
executorService.execute(() -> {
try {
semaphore.acquire();
update(count);
semaphore.release();
} catch (Exception e) {
log.error("exception", e);
}
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
log.info("size:{}", map.size());
}
private static void update(int i) {
map.put(i, i);
}
}跳表(SkipList):使用“空间换时间”的算法,令链表的每个结点不仅记录next结点位置,还可以按照level层级分别记录后继第level个结点。在查找时,首先按照层级查找,比如:当前跳表最高层级为3,即每个结点中不仅记录了next结点(层级1),还记录了next的next(层级2)、next的next的next(层级3)结点。
现在查找一个结点,则从头结点开始先按高层级开始查:head->head的next的next的next->。。。直到找到结点或者当前结点q的值大于所查结点,则此时当前查找层级的q的前一节点p开始,在p~q之间进行下一层级(隔1个结点)的查找......直到最终迫近、找到结点。此法使用的就是“先大步查找确定范围,再逐渐缩小迫近”的思想进行的查找。
线程安全策略-总结:
|
线程限制 |
一个线程被限制的对象,由线程独占,并且只能被占有它的线程修改; |
|
共享只读 |
一个共享只读的对象,在没有额外同步的情况下,可以被多个线程并发访问,但任何线程都不能修改它; |
|
线程安全对象 |
一个线程安全的对象或者容器,在内部通过同步机制来保证线程安全,所以其他线程无需额外的同步就可以通过公共接口随意访问它; |
|
被守护对象 |
被守护对象只能通过获取特定的锁来访问; |
JUC


 浙公网安备 33010602011771号
浙公网安备 33010602011771号