
Flink基础
目录
1、Flink模型
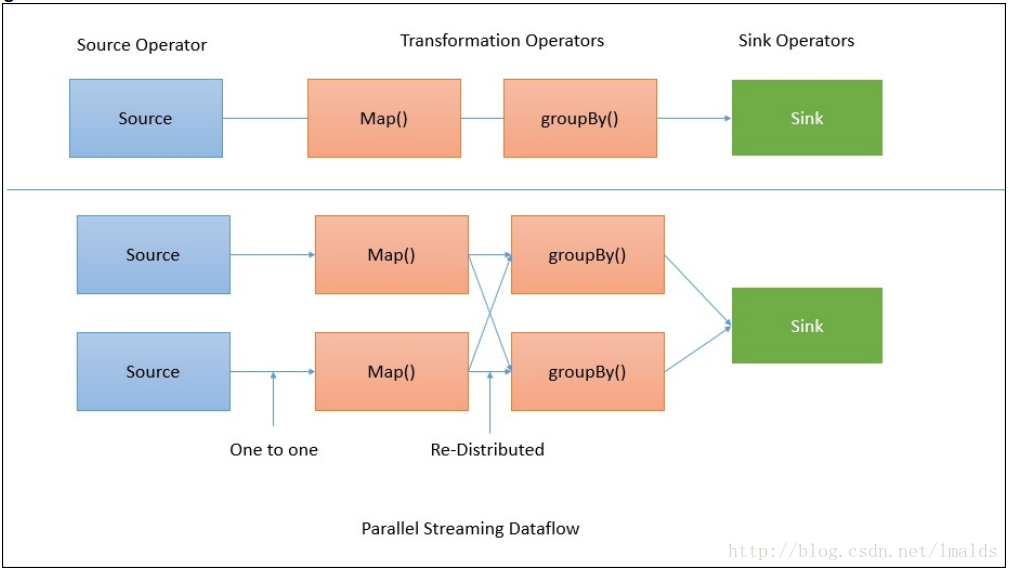
2、持续流模型
Flink的算子不是懒执行的,Spark算子在遇到Action算子才会执行
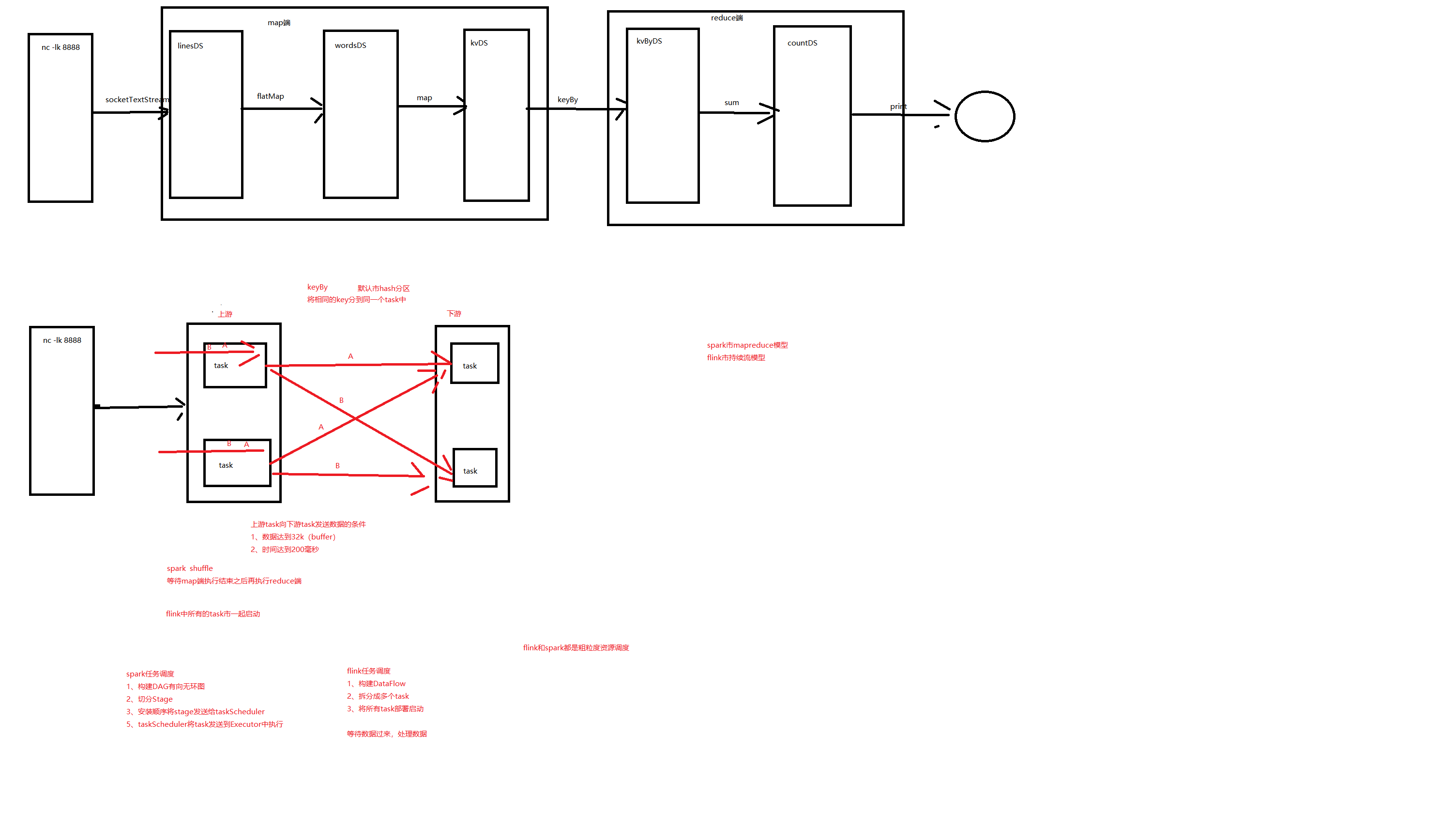
3、WordCount实例
package core
import org.apache.flink.streaming.api.scala._
object Demo1WordCount {
def main(args: Array[String]): Unit = {
//创建flink的环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度一核
env.setParallelism(1)
//读取socker数据
//nc -lk 8888
val lineDS: DataStream[String] = env.socketTextStream("master2",8888)
//将单词拆分出来
val wordDS: DataStream[String] = lineDS.flatMap(_.split(","))
//转换成kv格式
val kvDS: DataStream[(String, Int)] = wordDS.map(s=>(s,1))
//安装单词分组
val keyByDS: KeyedStream[(String, Int), String] = kvDS.keyBy(_._1)
//统计单词的数量
/**
* sum算子内部市有状态计算,累加统计
*/
val countDS: DataStream[(String, Int)] = keyByDS.sum(1)
countDS.print()
env.execute()
}
}
4、Source:数据源
1、四种Source
基于本地集合的 source基于文件的 source、基于网络套接字的 source、自定义的 source。
package source
import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala._
object Demo1Source {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
/**
* 基于本地集合构建DataStream -- 有界流
*
*/
val listDS: DataStream[Int] = env.fromCollection(List(1,2,3,4,5))
listDS.print()
/**
* 基于文件构建DataStream -- 有界流
*
*/
val stuDS: DataStream[String] = env.readTextFile("data/students.txt")
stuDS.map(stu=>(stu.split(",")(4),1))
.keyBy(_._1)
.sum(1)
.print()
/**
* 基于socket构建DataStream-- 无界流
*
*/
// val socketDS: DataStream[String] = env.socketTextStream("master2",8888)
// socketDS.print()
val myDS: DataStream[Int] = env.addSource(new MySource)
myDS.print()
env.execute()
}
}
/**
* 自定义source, 实现SourceFunction接口
* 实现run方法,
*
*/
class MySource extends SourceFunction[Int] {
/**
* run方法只执行一次
*
* @param sourceContext: 用于发送数据到下游task
*/
override def run(sourceContext: SourceFunction.SourceContext[Int]): Unit = {
var i=0
while (i<100){
//数据发送到下游
sourceContext.collect(i)
Thread.sleep(50)
i+=1
}
}
override def cancel(): Unit = {
}
}
2、自定义Source读取Mysql
SourceFunction - 单一的source , run方法只会执行一次
ParallelSourceFunction - 并行的source ,有多少个并行度就会有多少个source
RichSourceFunction 多了open和close方法
RichParallelSourceFunction
package source
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala._
object Demo2MysqlSource {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//使用自定义的source
val mysqlDS: DataStream[String] = env.addSource(new MysqlSource)
mysqlDS.print()
env.execute()
}
}
/**
* 自定义读取mysql --- 有界流
* SourceFunction - 单一的source , run方法只会执行一次
* ParallelSourceFunction - 并行的source ,有多少个并行度就会有多少个source
* RichSourceFunction 多了open和close方法
* RichParallelSourceFunction
*/
class MysqlSource extends RichSourceFunction[String] {
var con:Connection =_
/**
*
* open 方法会再run方法之前执行
*
* @param parameters flink 配置文件对象
*/
override def open(parameters: Configuration): Unit = {
Class.forName("com.mysql.jdbc.Driver")
con = DriverManager.getConnection("jdbc:mysql://master2:3306/tourist","root","123456")
}
/**
* 在run方法之后执行
*
*/
override def close(): Unit = {
con.close()
}
override def run(sourceContext: SourceFunction.SourceContext[String]): Unit = {
val statement: PreparedStatement = con.prepareStatement("select * from usertag limit 20")
val rs: ResultSet = statement.executeQuery()
while (rs.next()){
val mdn: String = rs.getString("mdn")
val name: String = rs.getString("name")
val id_number: String = rs.getString("id_number")
val packg: String = rs.getString("packg")
// 数据发送到下游
sourceContext.collect(mdn+","+name+","+id_number+","+packg)
}
}
override def cancel(): Unit = {
}
}
5、Transformation:数据转换的各种操作
1、Map
package ts
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala._
object Demo1Map {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val DS: DataStream[String] = env.socketTextStream("master2",8888)
val mapDS: DataStream[String] = DS.map(new MapFunction[String, String] {
override def map(t: String): String = {
t + "map"
}
})
mapDS.print()
env.execute()
}
}
2、FlatMap
相比scala需要collect方法来发送
RichFlatFunction会多了open和close方法
package ts
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.datastream.{DataStreamSource, SingleOutputStreamOperator}
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object Demo2FlatMap {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val DS: DataStreamSource[String] = env.socketTextStream("master2",8888)
val MfDS: SingleOutputStreamOperator[String] = DS.flatMap(new RichFlatMapFunction[String, String] {
override def open(parameters: Configuration): Unit = {
println("open")
}
override def close(): Unit = {
println("close")
}
override def flatMap(in: String, collector: Collector[String]): Unit = {
in.split(",")
.foreach(s=>{
collector.collect(s)
})
}
})
MfDS.print()
env.execute()
}
}
3、Filter
package ts
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala._
object Demo3Filter {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val DS: DataStream[String] = env.readTextFile("data/students.txt")
val filterDS: DataStream[String] = DS.filter(new FilterFunction[String] {
override def filter(t: String): Boolean = {
t.split(",")(3) =="女"
}
})
filterDS.print()
env.execute()
}
}
4、KeyBY 相同的key发送到同一个task中
package ts
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.streaming.api.scala._
object Demo4KeyBy {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val DS: DataStream[String] = env.socketTextStream("master2",8888)
DS.keyBy(new KeySelector[String,String] {
override def getKey(in: String): String = {
in
}
}).print()
env.execute()
}
}
5、Reduce 对keyBy之后对数据进行聚合
Reduce 返回单个的结果值,并且 reduce 操作每处理一个元素总是创建一个新值。常用的方法有 average、sum、min、max、count,使用 Reduce 方法都可实现。
package ts
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.streaming.api.scala._
object Demo5Reduce {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val DS: DataStream[String] = env.socketTextStream("master2",8888)
val keyByDS: KeyedStream[(String, Int), String] = DS.flatMap(_.split(","))
.map((_, 1))
.keyBy(_._1)
// val reduceDS: DataStream[(String, Int)] = keyByDS.reduce((x, y) => {
// (x._1, x._2 + y._2)
// })
keyByDS.reduce(new ReduceFunction[(String, Int)] {
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
(t._1,t1._2+t1._2)
}
}).print()
env.execute()
}
}
6、Agg
max和maxby的区别是max只是max的那个字段是最大的,其他字段是错的,而maxby都是正确的
package ts
import org.apache.flink.streaming.api.scala._
object Demo5Agg {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val stuDS: DataStream[String] = env.readTextFile("data/students.txt")
val Stu: DataStream[Student] = stuDS.map(s => {
val splits: Array[String] = s.split(",")
Student(splits(0), splits(1), splits(2).toInt, splits(3), splits(4))
})
Stu.keyBy(_.clazz)
.sum("age")
.print()
/**
* max 和 maxBy 之间的区别在于 max 返回流中的最大值,但 maxBy 返回具有最大值的键,
*/
Stu.keyBy(_.clazz)
.max("age")
.print()
Stu.keyBy(_.clazz)
.maxBy("age")
.print()
env.execute()
}
}
case class Student(id:String,name:String,age:Int,gender:String,clazz:String)
7、Window
package ts
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object Demo7Window {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val DS: DataStream[String] = env.socketTextStream("master2",8888)
val kyDS: DataStream[(String, Int)] = DS.flatMap(_.split(",").map((_,1)))
kyDS.keyBy(_._1)
.timeWindow(Time.seconds(5))
.sum(1)
.print()
env.execute()
}
}
8、union
package ts
import org.apache.flink.streaming.api.scala._
object Demo8Union {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val list1: DataStream[Int] = env.fromCollection(List(1,2,3,4))
val list2: DataStream[Int] = env.fromCollection(List(5,6,7))
list1.union(list2)
.print()
env.execute()
}
}
9、Side Outputs 旁路输出
package ts
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
object Demo9SideOutputs {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val stu: DataStream[String] = env.readTextFile("data/students.txt")
/**
* 将性别为男和性别为女学生单独拿出来
*
*/
val nan: OutputTag[String] = OutputTag[String]("男")
val nv: OutputTag[String] = OutputTag[String]("女")
val processDS: DataStream[String] = stu.process(new ProcessFunction[String, String] {
override def processElement(i: String, context: ProcessFunction[String, String]#Context, collector: Collector[String]): Unit = {
val gender: String = i.split(",")(3)
gender match {
case "男" => context.output(nan, i)
case "女" => context.output(nv, i)
}
}
})
processDS.getSideOutput(nan).print()
processDS.getSideOutput(nv)
env.execute()
}
}
6、Sink:接收器
1、写入文件
2、打印出来
3、写入 socket
4、自定义的 sink
1、打印出来
package sink
import org.apache.flink.streaming.api.functions.sink.SinkFunction
import org.apache.flink.streaming.api.scala._
object Demo1Sink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val stuDS: DataStream[String] = env.readTextFile("data/students.txt")
stuDS.addSink(new MySink)
env.execute()
}
}
class MySink extends SinkFunction[String]{
override def invoke(value: String): Unit = {
println(value.split(",")(1))
}
}
2、自定义sink写入mysql
package sink
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction
import org.apache.flink.streaming.api.scala._
object Demo2SinkMysql {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val stuDS: DataStream[String] = env.readTextFile("data/students.txt")
stuDS.addSink(new MySink2)
env.execute()
}
}
class MySink2 extends RichSinkFunction[String]{
var con:Connection=_
override def open(parameters: Configuration): Unit = {
Class.forName("com.mysql.jdbc.Driver")
con = DriverManager.getConnection("jdbc:mysql://master2:3306/tourist?useUnicode=true&characterEncoding=utf-8","root","123456")
}
override def close(): Unit = {
con.close()
}
override def invoke(value: String): Unit = {
val statement: PreparedStatement = con.prepareStatement("insert into students(id,name,age,gender,clazz) values (?,?,?,?,?)")
val splits: Array[String] = value.split(",")
statement.setString(1,splits(0))
statement.setString(2,splits(1))
statement.setInt(3,splits(2).toInt)
statement.setString(4,splits(3))
statement.setString(5,splits(4))
statement.execute()
}
}
7、Spark和Flink任务调度
Spark:
1、构建DAG有向无环图
2、切分Stage
3、按照顺序将stage发送给taskScheduler
4、taskScheduler将task发送到Executor中执行
Flink:
1、构建DataFlow
2、拆分成多个Task
3、将所有Task部署启动
4、等待数据过来,处理数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号