
Spark Shuffle
求PI,运用概率模型
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
object PIDemo {
def main(args: Array[String]): Unit = {
// local[*] 表示将并行度设置为跟电脑的cpu线程数一致
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("PIDemo")
val sc: SparkContext = new SparkContext(conf)
// slices表示生成多少个任务,cnt表示每个任务内生成多少个点
val cnt: Int = 100000
val slice = 100
// seqRDD的分区数等于slices
// parallelize 支持在传入一个参数numSlices 默认是同并行度一致,可以手动指定 表示最后生成的RDD分区数是多少
// 最终会决定task的数量
val seqRDD: RDD[Int] = sc.parallelize(0 to cnt*slice, slice)
// 随机生成-1到1的x,y
val pointRDD: RDD[(Double, Double)] = seqRDD.map(s => {
val x: Double = Random.nextDouble() * 2 - 1
val y: Double = Random.nextDouble() * 2 - 1
(x, y)
})
// 过滤出圆内的点
val circleNum: Long = pointRDD.filter {
case (x: Double, y: Double) =>
(x * x + y * y) <= 1
}.count()
val pi: Double = circleNum.toDouble / cnt / slice * 4
println("PI is"+pi)
}
}
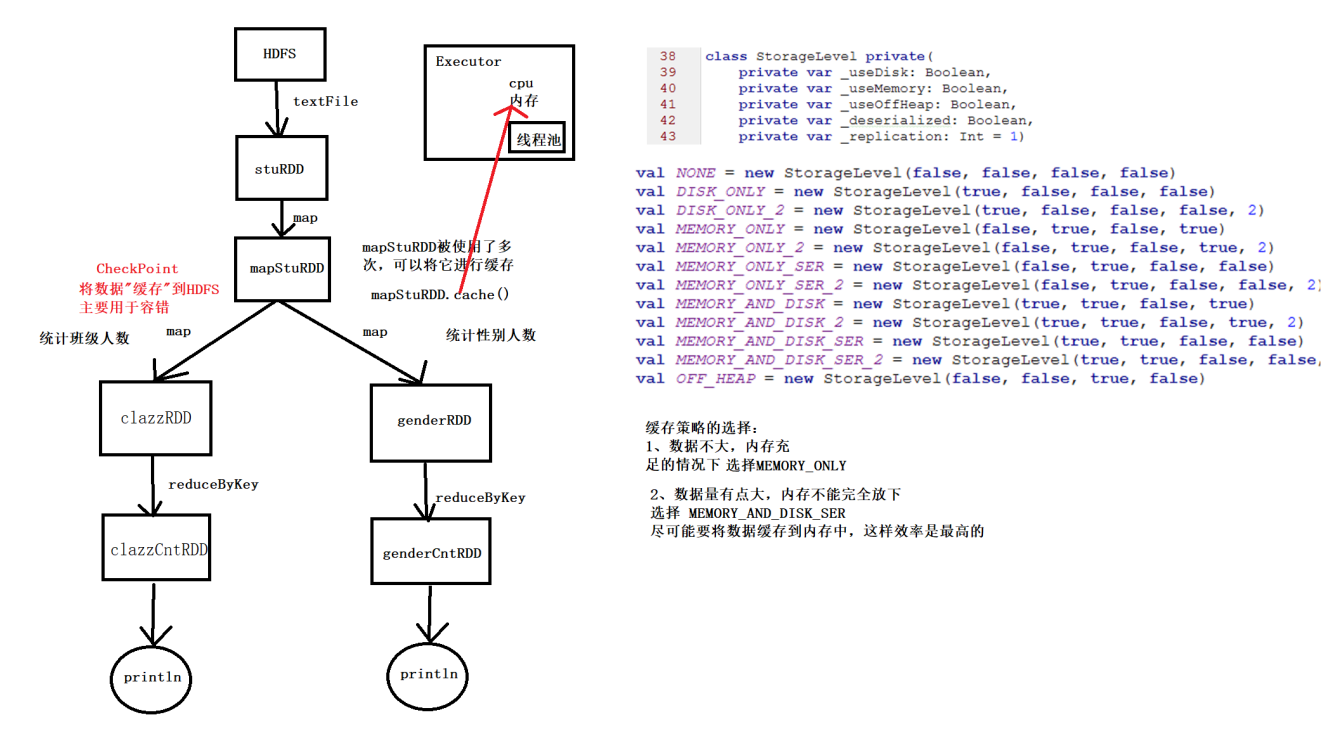
Spark Cache
Cache机制用于多次使用的RDD,通常选用MEMORY_AND_DISK_SER,基于内存和磁盘的序列化
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object CacheDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("CacheDemo").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// stuRDD后面多次使用,那么会多次从头开始,可以增加缓存机制
val stuRDD: RDD[String] = sc.textFile("scala/data/students.txt")
// 对使用了多次的RDD进行缓存
// cache() 默认将数据缓存到内存当中
// mapStuRDD.cache()
// 如果想要选择其他的缓存策略 可以通过persist方法手动传入一个StorageLevel
// 选择基于磁盘和内存序列化的,ser会进行压缩,尽可能将数据缓存到内存中,效率更高
stuRDD.persist(StorageLevel.MEMORY_AND_DISK_SER)
// 统计班级人数
val clazzRDD: RDD[(String, Int)] = stuRDD.map(s=>(s.split(",")(4),1))
val clazz_sum_RDD: RDD[(String, Int)] = clazzRDD.reduceByKey(_+_)
clazz_sum_RDD.foreach(println)
// 统计性别人数
val genderRDD: RDD[(String, Int)] = stuRDD.map(s=>(s.split(",")(3),1))
val gender_sum_RDD: RDD[(String, Int)] = genderRDD.reduceByKey(_+_)
gender_sum_RDD.foreach(println)
// 用完记得释放缓存
stuRDD.unpersist()
}
}
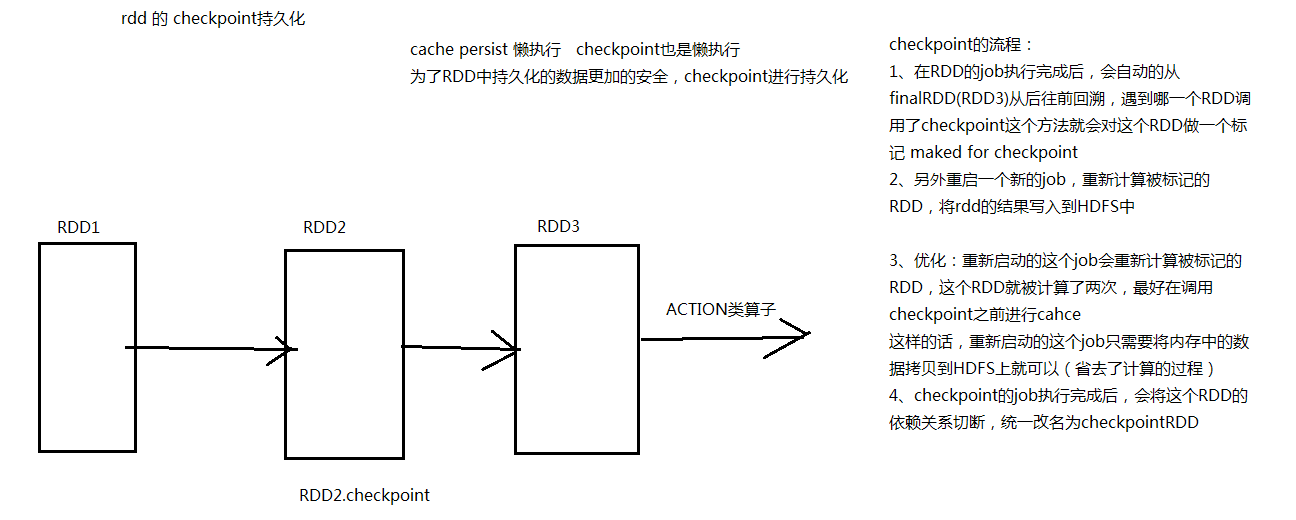
CheckPoint持久化
将RDD缓存在hdfs中,使数据更加安全
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object CheckPointDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("CheckPointDemo").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
sc.setCheckpointDir("spark/data/checkpoint")
// stuRDD后面多次使用,那么会多次从头开始,可以增加缓存机制
val stuRDD1: RDD[String] = sc.textFile("scala/data/students.txt")
val stuRDD: RDD[String] = stuRDD1.map(s => {
println("----------")
s
})
// 对使用了多次的RDD进行缓存
// cache() 默认将数据缓存到内存当中
stuRDD.cache()
// 如果想要选择其他的缓存策略 可以通过persist方法手动传入一个StorageLevel
// 选择基于磁盘和内存序列化的,ser会进行压缩,尽可能将数据缓存到内存中,效率更高
// stuRDD.persist(StorageLevel.MEMORY_AND_DISK_SER)
// 将数据缓存到 HDFS
// checkpoint主要运用在SparkStreaming中的容错
stuRDD.checkpoint()
// 统计班级人数
val clazzRDD: RDD[(String, Int)] = stuRDD.map(s=>(s.split(",")(4),1))
val clazz_sum_RDD: RDD[(String, Int)] = clazzRDD.reduceByKey(_+_)
clazz_sum_RDD.foreach(println)
// 统计性别人数
val genderRDD: RDD[(String, Int)] = stuRDD.map(s=>(s.split(",")(3),1))
val gender_sum_RDD: RDD[(String, Int)] = genderRDD.reduceByKey(_+_)
gender_sum_RDD.foreach(println)
// 用完记得释放缓存
// stuRDD.unpersist()
}
}
累加器和广播变量
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object AccDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("CheckPointDemo").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("scala/data/students.txt")
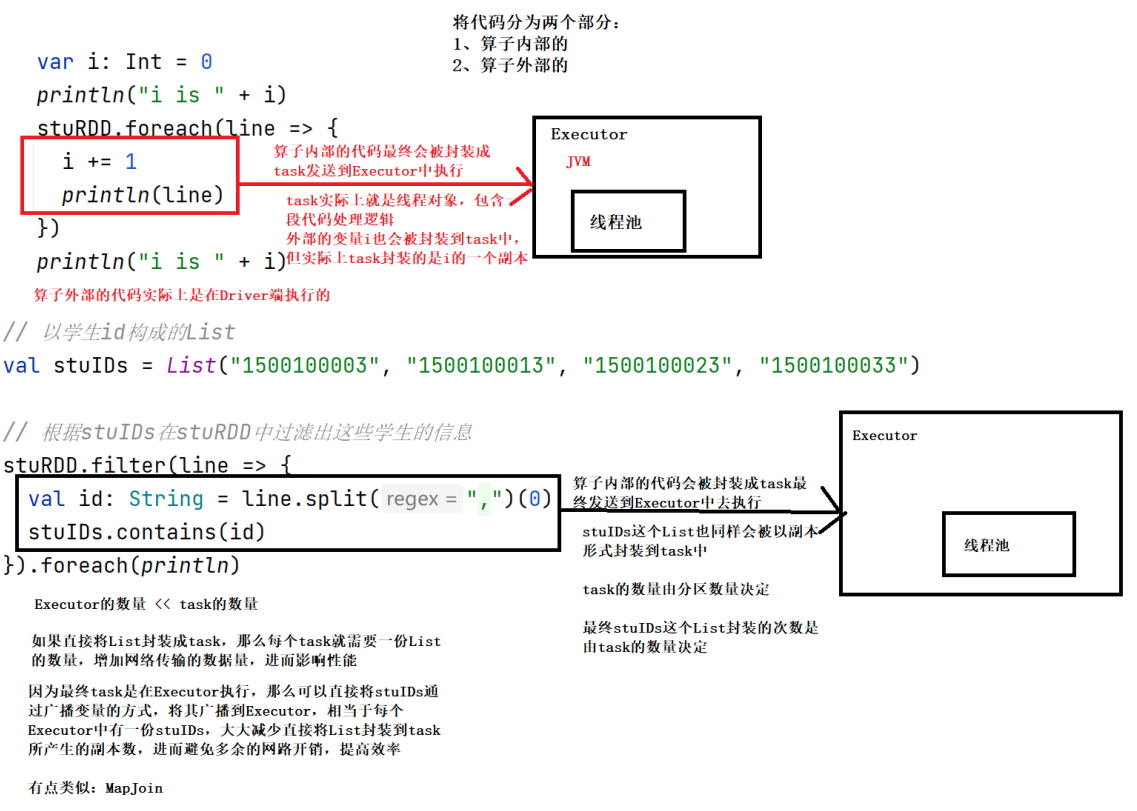
var i:Int=0
// 算子内部的代码 使用了外部变量i
// 实际上最终封装到task中的是i的一个副本,在外部的i回到外部还是不会发生改变
stuRDD.foreach(s=>{
i+=1
println(s)
})
println(i) //0
// 如果想在算子内部 对外部的变量做一个累加操作
// 累加器
// 在算子外面 即Driver端 通过累加器创建一个变量l
val ii: LongAccumulator = sc.longAccumulator
stuRDD.foreach(s=>{
ii.add(1)
println(s)
})
println(ii) //LongAccumulator(id: 25, name: None, value: 1000)
println(ii.value) //1000
// RDD内部不能再套RDD
/**
* 首先RDD是一种抽象的编程模型,并没有实现序列化所以不能进行网络传输
* 其次就算RDD能够进行网络传输,那如果RDD中还有RDD,
* 那么需要再task再去申请资源启动Driver、Executor?
*
* 如果RDD中套了RDD 就要去整理一下思路,是不是可以转换为其他方式去实现你的逻辑
*/
// stuRDD.foreach(line=>{
// stuRDD.foreach(l2=>{
// println(l2)
// })
// })
}
}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("BroadcastDemo").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val stuRDD: RDD[String] = sc.textFile("scala/data/students.txt")
val stuIDs: List[String] = List("1500100003", "1500100013", "1500100023", "1500100033")
// 根据stuIDs在stuRDD中过滤出这些学生的信息
// 算子内部的代码会被封装成task
// 相当于每个task中都有一份stuIDs 很明显造成了资源浪费
val filterRDD1: RDD[String] = stuRDD.filter(s => {
val id: String = s.split(",")(0)
stuIDs.contains(id)
})
filterRDD1.foreach(println)
// 使用广播变量
// 在Driver端 将stuIDs广播到每一个Executor中
val stuIdsBro: Broadcast[List[String]] = sc.broadcast(stuIDs)
val filterRDD2: RDD[String] = stuRDD.filter(s => {
val id: String = s.split(",")(0)
stuIdsBro.value.contains(id)
})
filterRDD2.foreach(println)
}
}
分区数量判定
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ShuffleDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("ShuffleDemo").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
// 读取单词数据构建RDD
// 如果在集群中运行的时候 默认最少是 2个分区
// local本地默认一个
val stuRDD: RDD[String] = sc.textFile("scala/data/words.txt",3)
println(stuRDD.getNumPartitions) //3
// 如果没有产生shuffle 那么子RDD的分区数由父RDD的分区数决定
val wordsRDD: RDD[String] = stuRDD.flatMap(s=>s.split(","))
println(wordsRDD.getNumPartitions) //3
val mapRDD: RDD[(String, Int)] = wordsRDD.map(s=>(s,1))
println(mapRDD.getNumPartitions) //3
// repartition 可以通过shuffle改变分区的数量
// 相当于一个转换算子 但是不做任何逻辑上的处理
val repRDD: RDD[(String, Int)] = mapRDD.repartition(4)
println(repRDD.getNumPartitions) //4
// coalesce 也是一个转换算子,也可以调整分区数
// 一般用于 减少分区数量 而且不会产生shuffle
// 也可以接受一个参数 shuffle 默认是false
// 如果shuffle = true 相当于 repartition
// 分区规则默认是 hash分
val coaRDD: RDD[(String, Int)] = mapRDD.coalesce(2)
println(coaRDD.getNumPartitions) //2
// shuffle类的算子可以手动调整分区数
// 相当于手动设置reduce任务的个数
val wordcountRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_,5)
println(wordcountRDD.getNumPartitions) //5
/**
* shuffle类算子产生的RDD的分区数决定因素:
* 1、如果没有指定,默认等与父RDD的分区数
* 2、可以手动指定修改分区数量
* 3、通过默认参数设置 spark.default.parallelism
*
* 手动设置的 > 默认参数(spark.default.parallelism) > 父RDD的分区数
*/
wordcountRDD.foreach(println)
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号