
HBase常用shell操作
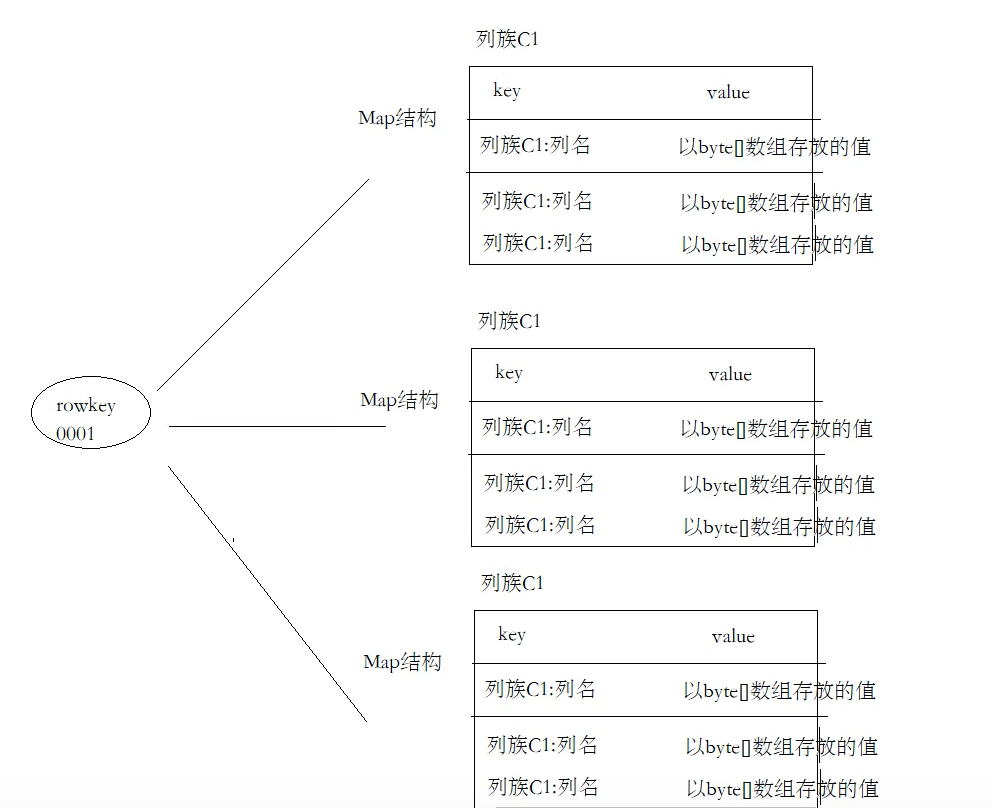
行(row),列(Column),列蔟(Column Family),列标识符(Column Qualifier)和单元格(Cell)
行:由一个个行键(rowkey)和一个多个列组成。其中rowkey是按照字典顺序排序
列:列由列蔟(Column Family)和列限定符(Column Qualifier)组成 例如:C1:ID
列蔟:创建表时就已经创建,是固定的,所有表中的每一行都有相同的列蔟,列蔟和列标识符通过绑定在一起用:连接
列标识符(列名):为存储的values数据提供索引,不同的行可能存在不同的列标识符
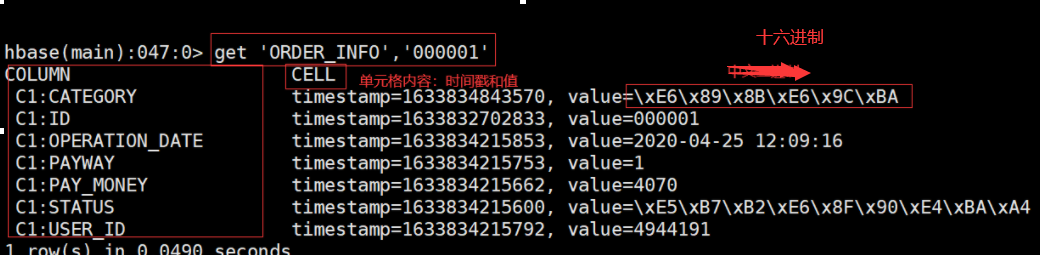
单元格:是行、列蔟和列标识符的组合,包含一个值和一个时间戳,以十六进制进制进行显示存储

创建表
首先先启动hbase shell
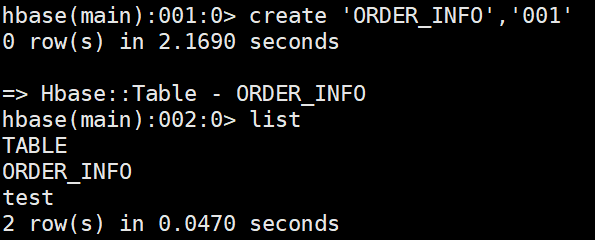
create '表名','列蔟名'... (一个表可以包含若干个列蔟)
create 'ORDER_INFO','001'
查看表
list '表名'
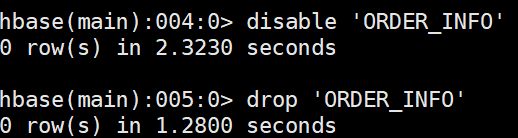
删除表(先禁用表才能删除)
disable '表名 '
drop '表名'
添加数据
put '表名','ROWKEY','列蔟名(Column Family):列限定符(Column Qualifier)','值'
put 'ORDER_INFO','000001','C1:ID','000001'
put 'ORDER_INFO','000001','C1:STATUS','已提交'
put 'ORDER_INFO','000001','C1:PAY_MONEY',4070
put 'ORDER_INFO','000001','C1:PAYWAY',1
put 'ORDER_INFO','000001','C1:USER_ID',4944191
put 'ORDER_INFO','000001','C1:OPERATION_DATE','2020-04-25 12:09:16'
put 'ORDER_INFO','000001','C1:CATEGORY','手机'

查看添加的数据
get '表名','rowkey'
get 'ORDER_INFO','000001'
get 'ORDER_INFO','000001','C1:ID'
显示中文:get命令最后添加 {FORMATTER => 'toString'} FORMATTER要大写
查看表结构
describe 'ORDER_INFO'
更新操作
更新指定的列(每执行一次put,时间戳都会发生改变)
put 'ORDER_INFO', '000001', 'C1:STATUS', '已付款'
删除操作
删除指定的列
delete '表名', 'rowkey', '列蔟:列'
delete 'ORDER_INFO','000001','C1:STATUS'
注意:此处HBase默认会保存多个时间戳的版本数据,所以这里的delete删除的是最新版本的列数据。
删除前

删除后

删除整行数据
deleteall '表名','rowkey'
deleteall 'ORDER_INFO','000001'
清空表
truncate "表名"
truncate 'ORDER_INFO'
扫描操作
scan '表名' (注意避免扫描大表)
scan 'ORDER_INFO'

扫描前两条
scan 'ORDER_INFO',{LIMIT=>2}
按固定rowkey扫描
hbase(main):079:0> scan 'ORDER_INFO',{ROWPREFIXFILTER=>'000001'}
范围查询 STARTROW(开始rowkey) ENDROW(结束rowkey)
scan 'ORDER_INFO', {STARTROW => 'row2'}
scan 'ORDER_INFO', {STARTROW => 'row2',ENDROW => 'row2'}
scan 'ORDER_INFO', {STARTROW => 'row2',ENDROW => 'row3'}
加载表,统计表记录数,禁用启用表
加载表
在linux中直接执行hbase shell 文件路径 (不要在shell中执行)
统计表记录数
count ‘表名’, {INTERVAL => intervalNum, CACHE => cacheNum} (每intervalNum告诉一次,每次刷cacheNum条)
INTERVAL设置多少行显示一次及对应的rowkey,默认1000;CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
当有大量数据时可以进行MapReduce程序统计
启动yarn集群
start-yarn.sh
启动history server
mr-jobhistory-daemon.sh start historyserver
执行命令:$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'ORDER_INFO'
禁用启用表
禁用表:disable ‘表名’
启动表:enable ‘表名’
测试表是否存在:exists ‘表名’
Hbase计数器
要使用incr来初始化一个列,不能用put操作
可以使用get_counter的指令来获取计数器的操作,使用get是获取不到的
get_counter 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT'

![]()
incr '表名','rowkey','列蔟:列名',xxx(xxx是增加的值,不写就是默认加1)
incr 'NEWS_VISIT_CNT','0000000020_01:00-02:00','C1:CNT',2

shell管理命令
status:显示服务器状态
![]()
whoaim:显示HBase当前用户
describe:展示表结构信息

exists:检查表是否存在,适用于表量特别多的情况

Hive整合HBase
create external table students_hbase
(
id string,
name string,
age string,
gender string,
clazz string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" = "
:key,
info:name,
info:age,
info:gender,
info:clazz
")
tblproperties("hbase.table.name" = "default:students");

 浙公网安备 33010602011771号
浙公网安备 33010602011771号