
Hive大全
Hive是基于Hadoop的一个数据仓库,可将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。其实,Hive的本质是将HiveSQL语句转化成MapReduce任务执行。
count(*)、count(1) 、count('字段名') 区别:
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计
创建表语法
create [external] table [if not exists ] table_name( //external外部表,删除表,内部表元数据和数据会被一起删除,外部表只删除元数据,不删除数据,数据仍在hdfs上
col_name data_type [comment '字段描述信息']
col_name data_type [comment '字段描述信息']
[comment '表的描述信息']
[partitioned by (col_name data_type, ...)] //表分区,一个表可以有多个分区,每个分区单独存在一个目录下
[clustered by (col_name.col_name, ...)] //分桶,分文件
[sorted by (col_name [asc|desc], ... ) into num_buckets buckets] //排序
[row format row_format] //指定表数据的分隔符
[storted as ...] //指定表数据存储类型 纯文本时:storted as textfile 需要压缩: storted as sequencefile
[location '指定表的存储路径' ]
创建表并指定字段之间的分隔符(hive默认分隔符是一个 框)
create table stu(id int,name string) row format delimited fields terminated by '\t'
创建表并指定表文件存放路径
create table stu(id int,name string) row format delimited fields terminated by '\t' location 'usr/students' //hdfs中的文件路径
根据已经存在的表结构创建表
create table stu1 like students
ACID:原子性,一致性,隔离性,持久性
加载数据
从liunx本地
load data local inpath '文件路径' into table students
load data local inpath '文件路径' overwrite into table students //加载数据并覆盖
从hdfs中(剪切操作)
load data inpath '文件路径' into table students
分区表的操作
创建分区表
create table score(id int,subject int,score int) partitioned by (year string,month string,day string) row format delimited fields terminated by ',';
增加分区
alter table score add partition(year='',month='',day='')
删除分区
alter table score drop partition(year='',month='',day='')
查看表的分区
show partitions score
插入 加载数据到分区表中
insert into table score partition(year='',month='',day='') select * from students
load data local inpath '/usr/local/data/score.txt' into table score partition (year='2021',month='9',day='26');
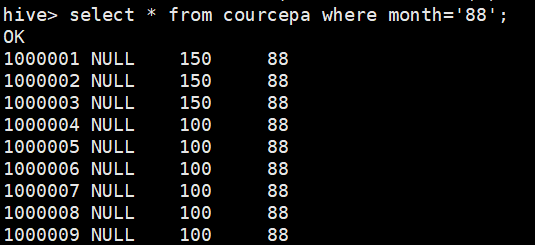
查找分区
select count(*) from score where month='88';

分区的过程以及结果


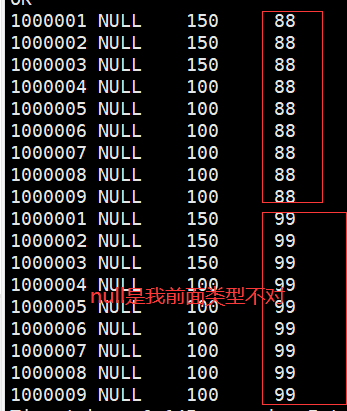

动态分区(根据原始表的字段进行创建分区表,insert操作分区)
开启动态分区:
set hive.exec.dynamic.partition=true;
表示动态分区模式(strict(需要配合静态分区一起使用)、nostrict):
set hive.exec.dynamic.partition.mode=nostrict;
表示支持的最大的分区数量为1000,可以根据业务自己调整:
set hive.exec.max.dynamic.partitions.pernode=1000;
分区字段需要放在 select 的最后,如果有多个分区字段 同理,它是按位置匹配,不是按名字匹配
比如下面这条语句会使用age作为分区字段,而不会使用student_dt中的dt作为分区字段
insert into table students_dt_p partition(dt) select id,name,age,gender,dt,age from students_dt;
创建好了两张表
分区insert操作,这时的partition(dt)是按位置进行查找,找最后一个,只是刚好select * from students_dt的最后一个字段也是dt

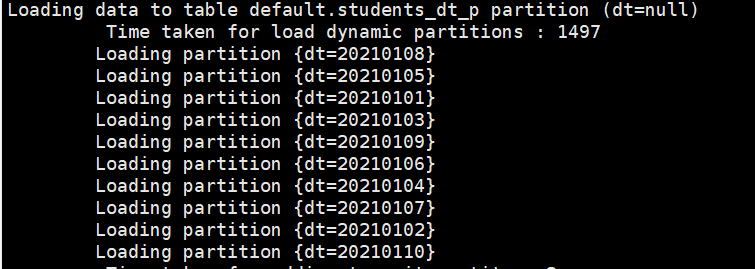
多级分区
创表导入数据
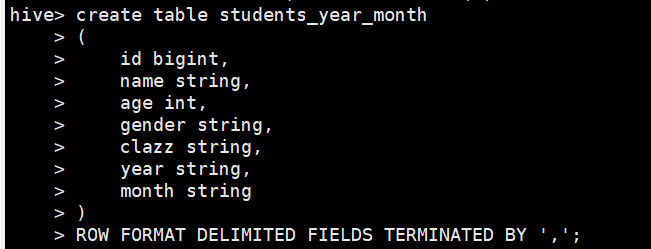
![]()
insert分区
![]()
结果
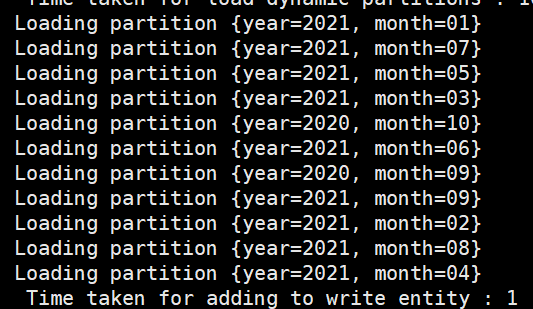
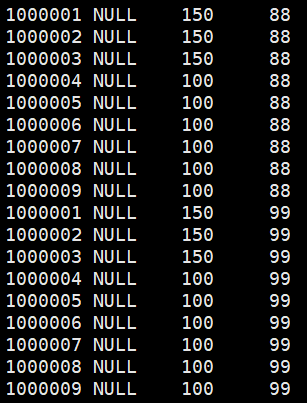
多分区表联合查询
union和union all的区别是:union会自动去重
这时会走MapReduce操作,出现union操作
分区表先有数据然后再有表的操作,是将数据加载到表中
创建文件目录:hadoop dfs -mkdir -p /datacource/month=8888
上传文件:hadoop dfs -put /usr/local/data/cource.txt /datacource/month=8888
hive建外部表(可以保留数据):hive> create external table courcepa1 (id int,subject string,score int) partitioned by (month string) row format delimited fields terminated by ',' location '/datacource';
进行表的修复:msck repair table courcepa1
分桶表的操作
在往分桶表中插入数据的时候,会根据 clustered by 指定的字段 进行hash分区(.hashcode获取int类型值) 对指定的buckets个数 进行取余,进而可以将数据分割成buckets个数个文件,以达到数据均匀分布,可以解决Map端的“数据倾斜”问题,方便我们取抽样数据,提高Map join效率。
MR:按照key的hash值除以reduceTask个数进行取余(reduce_id = key.hashcode % reduce.num)
Hive:按照分桶字段(列)的hash值除以分桶的个数进行取余(bucket_id = column.hashcode % bucket.num)
1.开启hive的分桶功能
set hive.enforce.bucketing=true;
2.设置reduce的个数
set mapreduce.job.reduces=3;
3.创建分桶表
create table coursecl (id int,subject string,score int) clustered by (id) into 3 buckets row format delimited fields terminated by ','
4.分桶表加载数据
4.1创建普通表
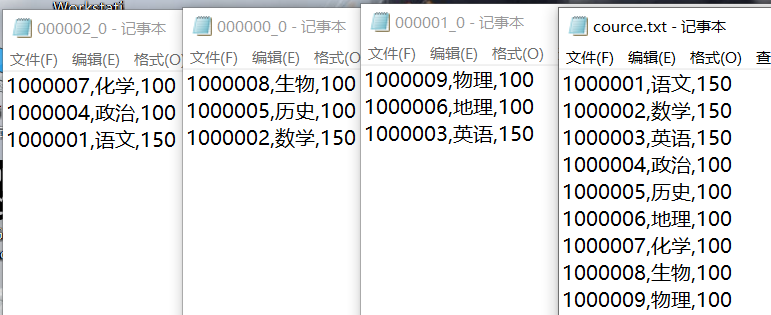
create table common_coursecl (id int,subject string,score int) row format delimited fields terminated by ',';
4.2普通表加载数据
load data local inpath '/usr/local/data/cource.txt' into table common_coursecl;
4.3通过普通表加载数据到分桶表(insert overwrite)
insert overwrite table coursecl select * from common_coursecl cluster by(id); //会启动MapReduce任务
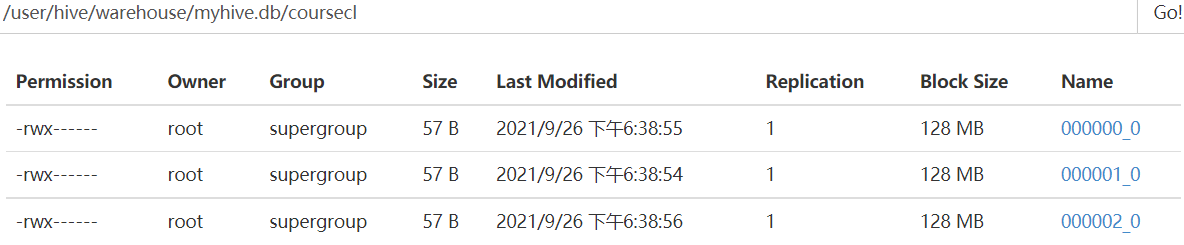
(这次实验我的数据有十个但是分了3个桶最后只有九个数据,缺少了第一行的数据)
JBDC连接Hive
启动hiveserver2
hive --service hiveserver2 &
或者
hiveserver2 &
两个依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
package hive; import java.sql.*; public class HiveTest { public static void main(String[] args) throws Exception { Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection con = DriverManager.getConnection("jdbc:hive2://master:10000/myhive"); //如果需要执行MapReduce,则需要增加用户 root,无密码 Statement statement = con.createStatement(); String sql="select * from students"; ResultSet rs = statement.executeQuery(sql); while (rs.next()){ String id = rs.getString("id"); String name = rs.getString("name"); String age = rs.getString("age"); String sex = rs.getString("sex"); String clazz = rs.getString("clazz"); System.out.println(id+"--"+name+"--"+age+"--"+sex+"--"+clazz); } rs.close(); statement.close(); con.close(); } }
修改表结构
修改表名
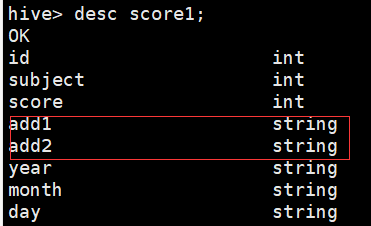
alter table score rename to score1;
添加列(add columns)
alter table score1 add columns(add1 string,add2 string);
更新列
alter table score1 change column add2 add2new int;

排序
join
大表在前,小表在后,将小表copyfile到所有节点,叫全表广播
SORT BY(单reduce排序)
1.设置reduce个数
set mapreduce.job.reduces=3
查看reduce个数
set mapreduce.job.reduces
2.进行降序排序
select * from score1 sort by score;
3.将查询结果加载到文件(linux中)
insert overwrite local directory '/usr/local/data/sort' select * from score1 sort by score
DISTRIBUTE BY 分区排序
1.设置reduce个数
set mapreduce.job.reduces=7
2.分区排序
insert overwrite local directory '/sort' select * from score1 distribute by id sort by score;
CLUSTER BY 只能倒序排序
select * from score1 cluster by id
等价于 select * from score1 distribute by id sort by id
Hive Shell
Hive参数配置: 参数声明>命令行参数>配置文件参数(hive)
复杂数据类型
arrays
hive> create table scorearr (name string,score array<string>) row format delimited fields terminated by ' ' collection items terminated by ','
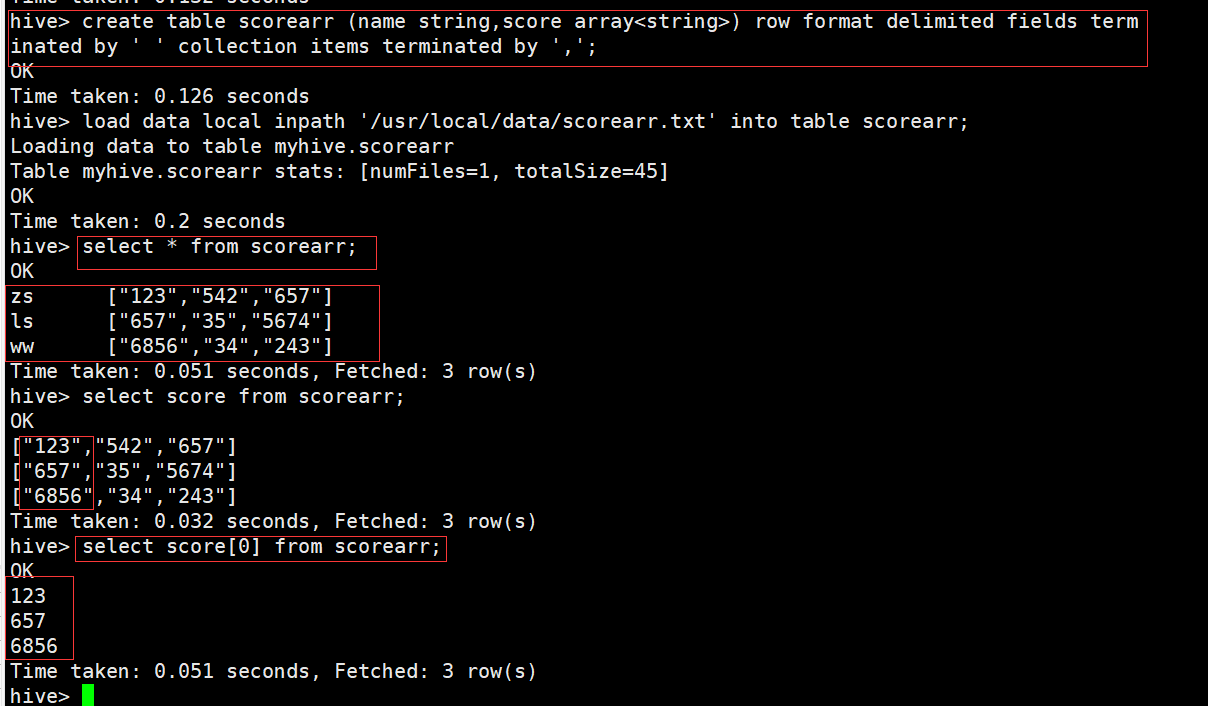
Maps
create table scoremap (name string,score map<string,int>) row format delimited fields terminated by ' ' collection items terminated by ',' map keys terminated by ':';
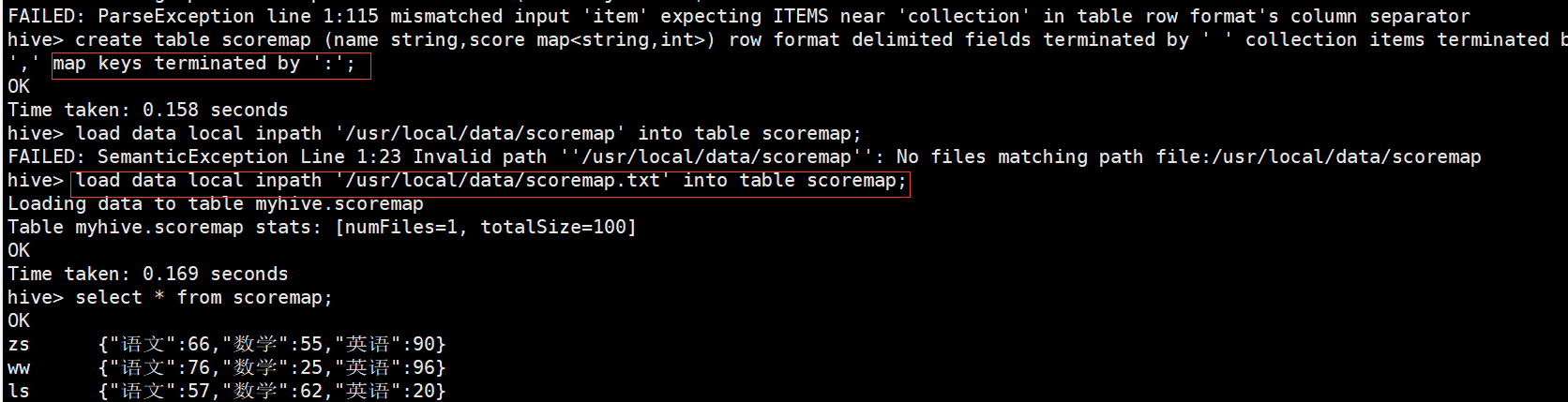
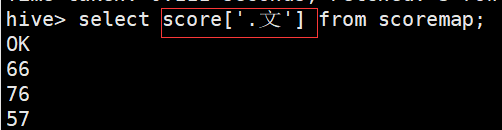
还是通过 [ ] 来通过key找value
Structs
hive> create table struct(name string,score struct<high:int,weight:int,age:int,sex:int,clazz:string>) row format delimited fields terminated by ' ' collection items terminated by ',';
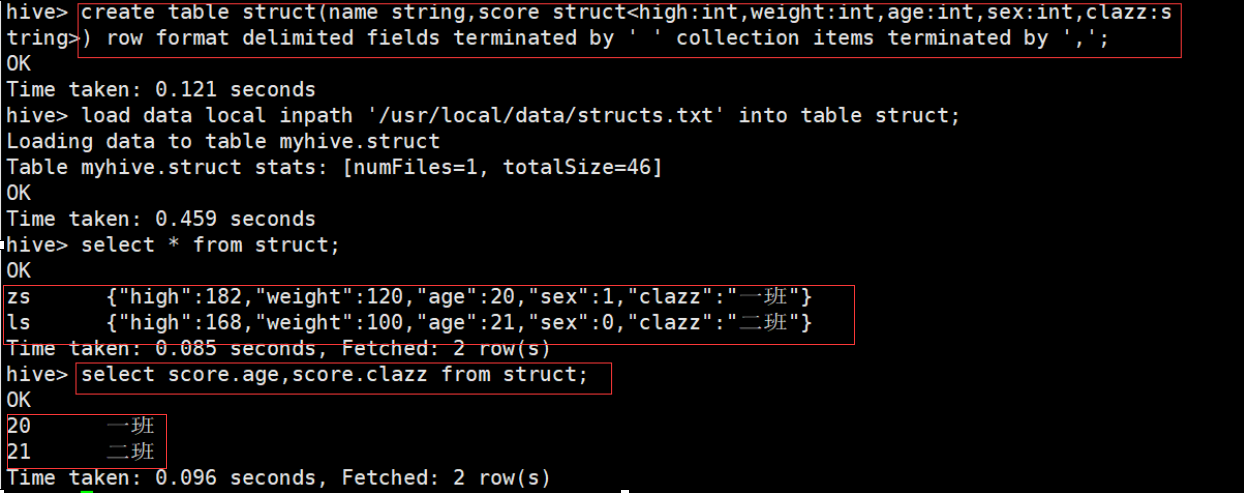
Hive 函数
内置函数
1.查看系统自带的函数
hive> show functions;
2.显示自带的函数用法
hive> desc function in;
3.详细显示自带函数的用法
hive> desc function extended in;
4.常用函数
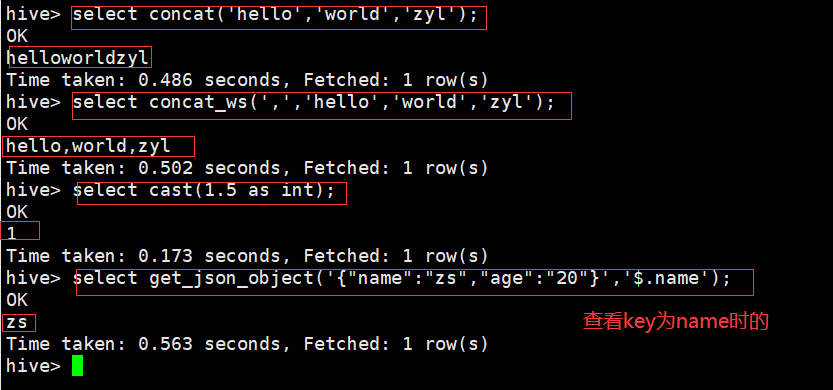
hive> select concat('hello','world','zyl'); //字符串连接
hive> select concat_ws(',','hello','world','zyl'); //指定分隔符拼接
select cast(1.5 as int); //类型转换
hive> select explode(score) from scorearr; //复杂数据扁平化,行转列,列转行
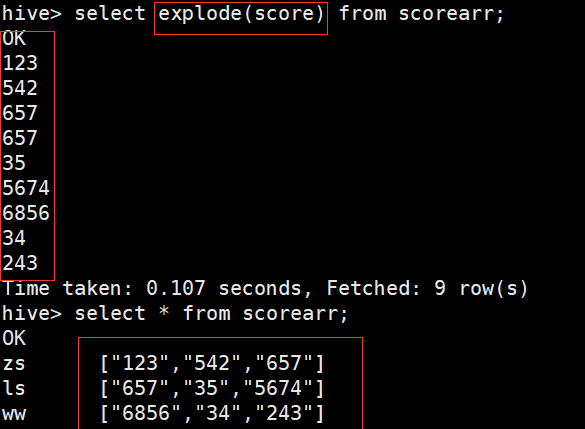
hive> select get_json_object('{"name":"zs","age":"20"}','$.name'); //josn字符串的解析
hive> select from_unixtime(1633071826);
![]()
hive> select unix_timestamp('2021-10-01 15:10:22');
![]()
hive> select date_format('2021-10-01','yyyy:MM:dd');
![]()
hive> select date_add('2021-09-06 20:02:39',10);
![]()
hive> select datediff('2021-09-06','2021-10-06');
![]()
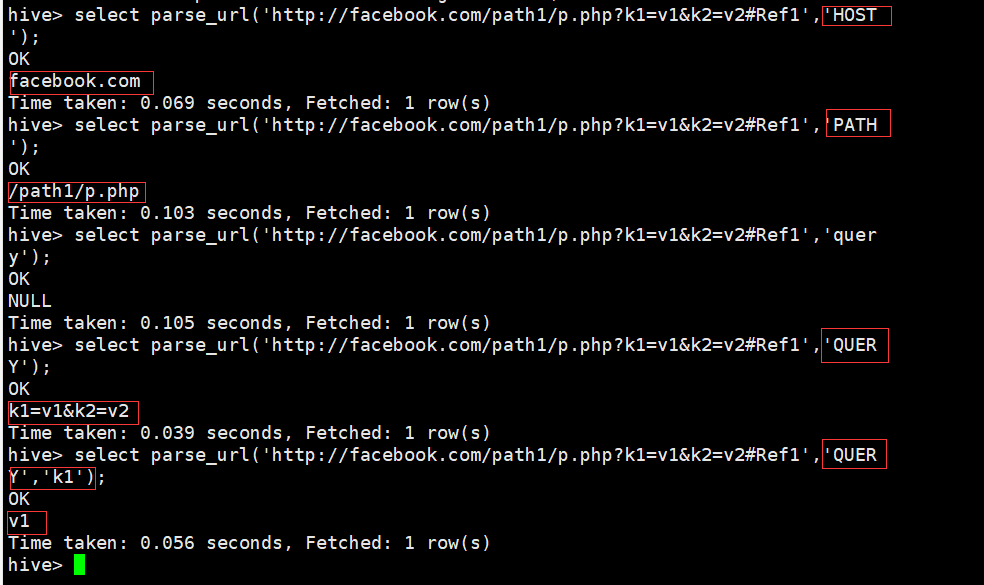
URL解析函数
hive> select parse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1','HOST');
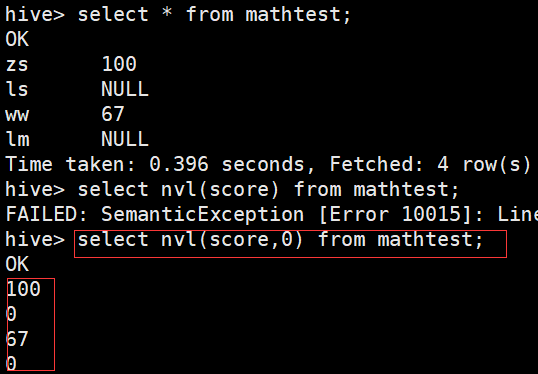
遇到值为null时进行计算操作,会对结果产生影响
nvl() , if , case when then end函数(对null值的处理)
nvl(字段名,0)
if(字段名 is null , 0 ,字段名)
case when 字段名 is null then 0 else 字段名 end

开窗函数 (对函数进行重写)
求wordcount
hive> select a.wordname,count(*) from (select explode(split(word,',')) as wordname from wordcount) as a group by a.wordname;
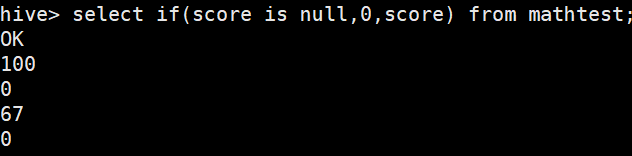
count(*)重写实现统计班级人数在每条数据之后
select *,count(*) over (partition by clazz) from new_score;
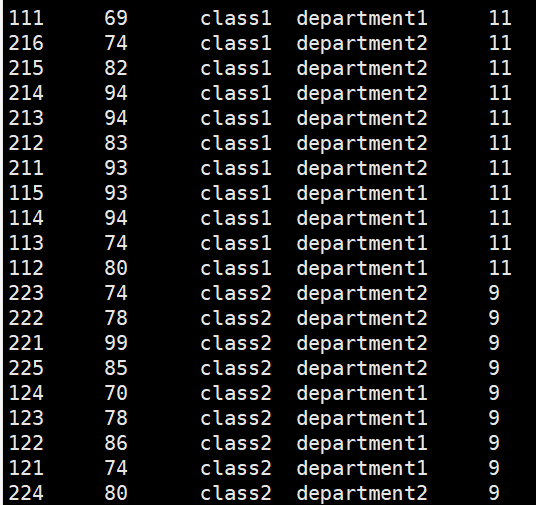
max(score) 重写求每个班级的最高分,每个学生的分和最高分的差值
hive> select *,max(score) over (partition by clazz) from new_score;
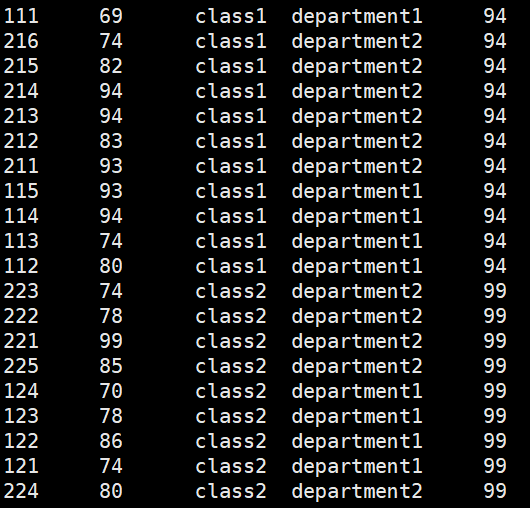
hive> select a.*,b.num,b.num-a.score from (select * from new_score) a join (select id,max(score) over (partition by clazz) as num from new_score) b on a.id=b.id;
hive> select a.*,a.num-a.score from (select *,max(score) over (partition by clazz) as num from new_score) a;
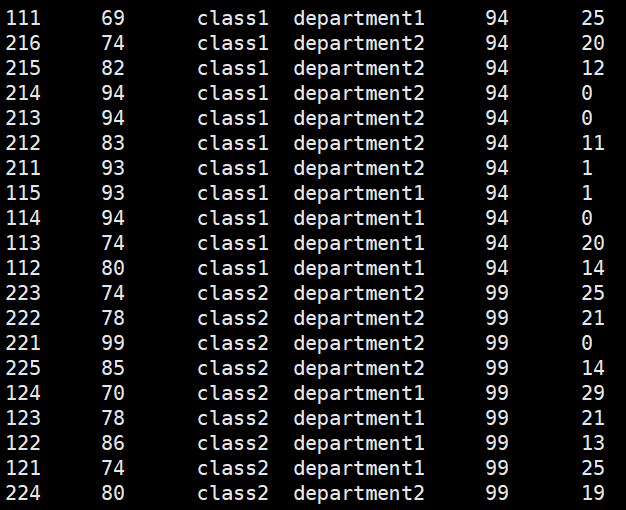
row_number() 根据排序的结果进行计数,不能单用,求TOP N
hive> select *,row_number() over (partition by clazz order by score) from new_score;
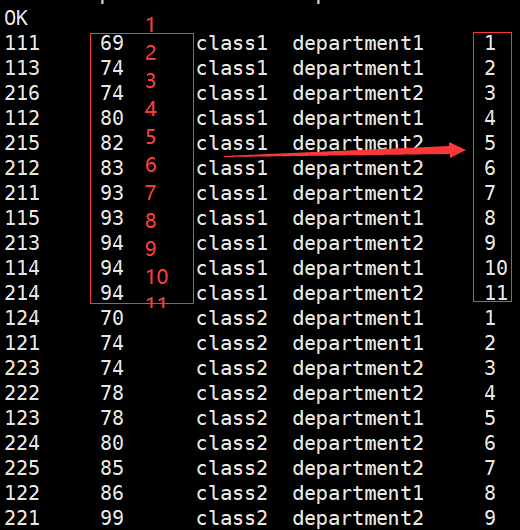
hive> select a.* from (select *,row_number() over (partition by clazz order by score desc) as num from new_score) a where a.num<=3;
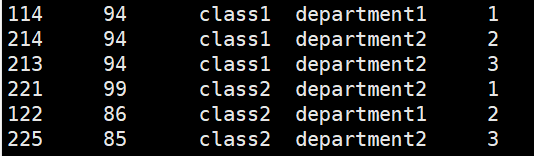
row_number:无并列排名
dense_rank:有并列排名,并且依次递增 rank:有并列排名,不依次递增
percent_rank:(rank的结果-1)/(分区内数据的个数-1)
cume_dist:计算某个窗口或分区中某个值的累积分布
NTILE(n):对分区内数据再分成n组,然后打上组号
hive> select *,row_number() over (partition by clazz order by score desc),dense_rank() over (partition by clazz order by score desc),rank() over (partition by clazz order by score desc),percent_rank() over (partition by clazz order by score desc),cume_dist() over (partition by clazz order by score desc) from new_score;
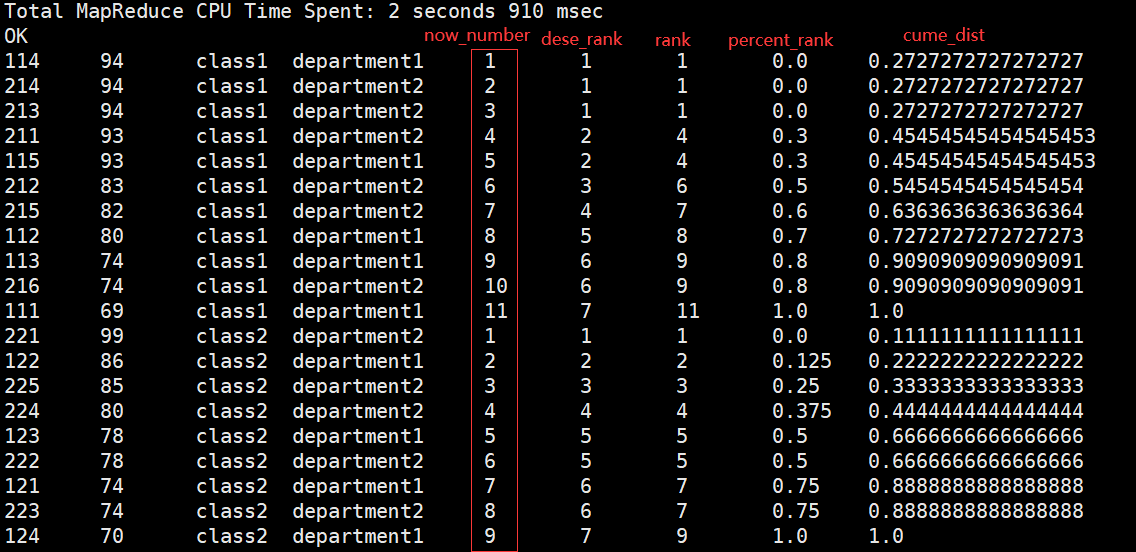
hive> select *,ntile(3) over (partition by clazz order by score desc) from new_score;
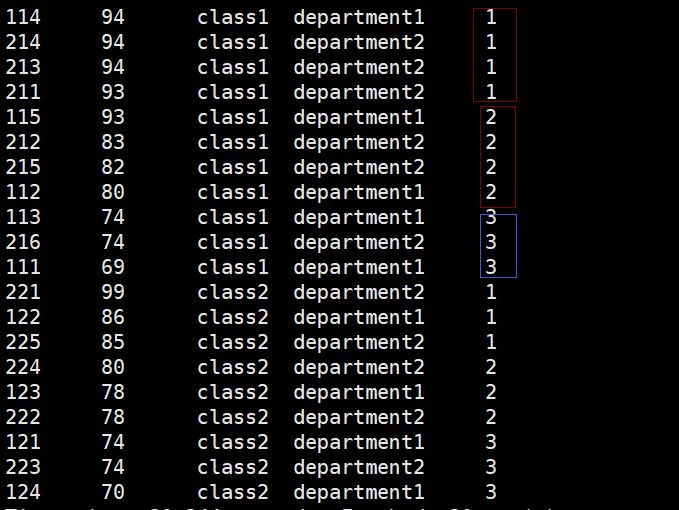
窗口帧
格式1:按照行的记录取值
ROWS BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
格式2:当前所指定值的范围取值
RANGE BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
rows格式1:前2行+当前行+后两行
sum(score) over (partition by clazz order by score desc rows between 2 PRECEDING and 2 FOLLOWING)
rows格式2:前记录到最末尾的总和
sum(score) over (partition by clazz order by score desc rows between CURRENT ROW and UNBOUNDED FOLLOWING)
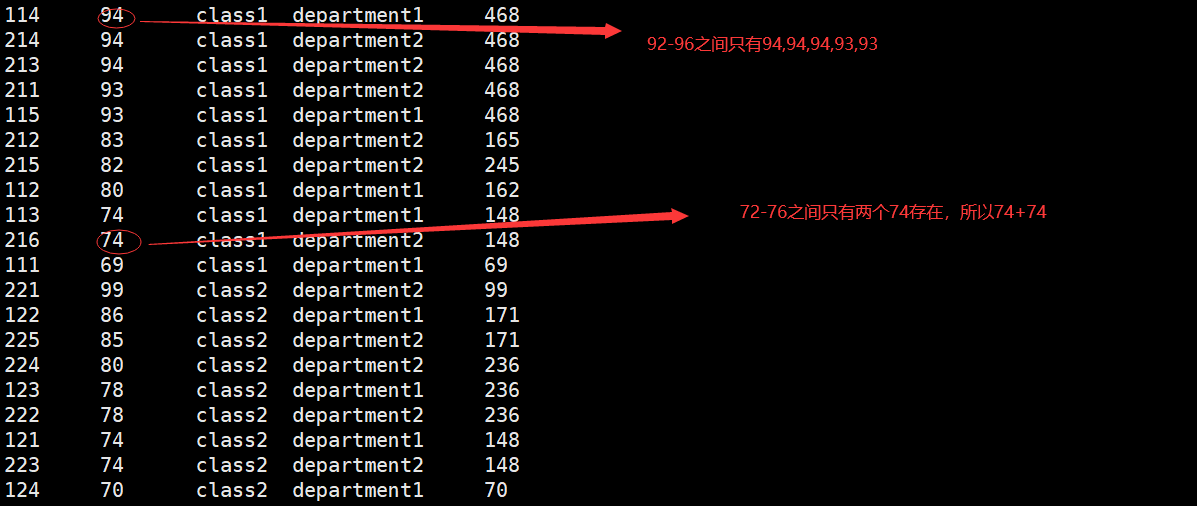
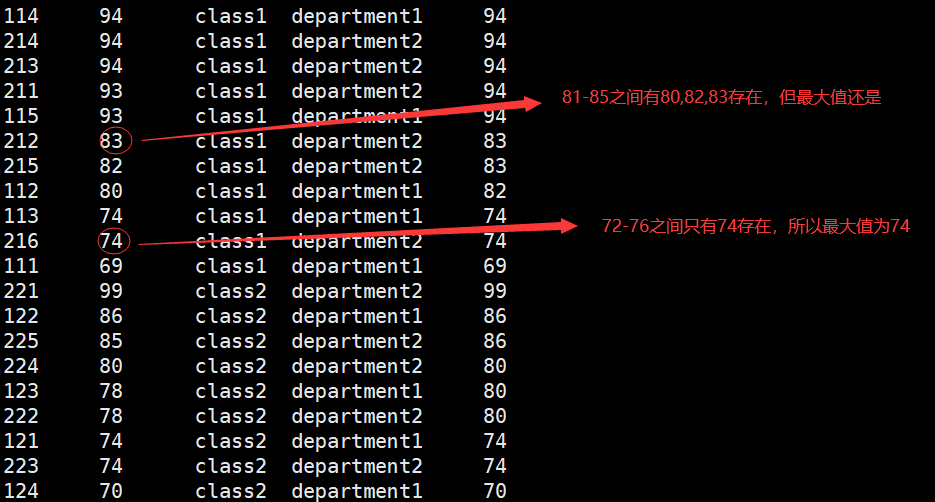
range格式1: 如果当前值在80,取值就会落在范围在80-2=78和80+2=82组件之内的行
max(score) over (partition by clazz order by score desc range between 2 PRECEDING and 2 FOLLOWING)
hive> select *,sum(score) over (partition by clazz order by score desc rows between 2 preceding and 2 following) from new_score
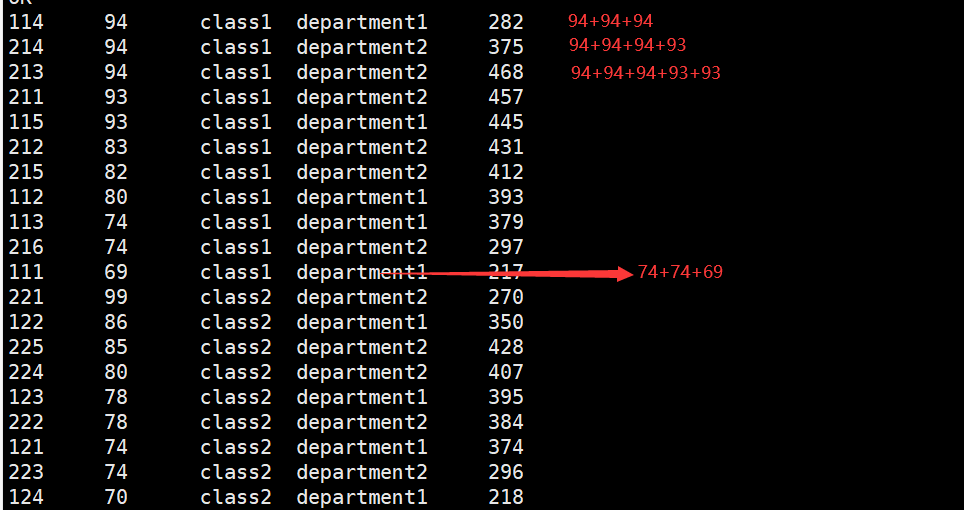
hive> select *,sum(score) over (partition by clazz order by score desc rows between current row and unbounded following) from new_score;
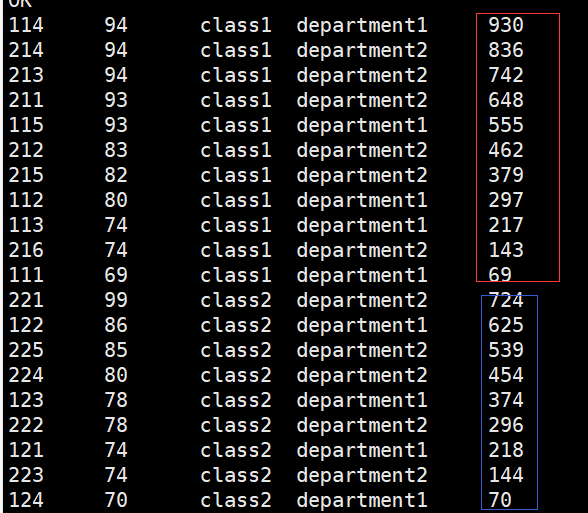
hive> select *,sum(score) over (partition by clazz order by score desc range between 2 preceding and 2 following) from new_score;
hive> select *,max(score) over (partition by clazz order by score desc range between 2 preceding and 2 following) from new_score;
window as(开窗函数)和with as(表连接)的使用
hive> select *,sum(score) over x,min(score) over x,max(score) over x from new_score window x as (partition by clazz order by score desc);
hive> with t1 as (select * from emp),t2 as (select * from dept) select * from t1 join t2 on t1.deptno=t2.deptno;
LAG(col,n):往前第n行数据
LEAD(col,n):往后第n行数据
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
LAST_VALUE:取分组内排序后,截止到当前行,最后一个值,对于并列的排名,取最后一个
hive> select id
> ,score
> ,clazz
> ,department
> ,lag(id,2) over (partition by clazz order by score desc) as lag_num
> ,LEAD(id,2) over (partition by clazz order by score desc) as lead_num
> ,FIRST_VALUE(id) over (partition by clazz order by score desc) as first_v_num
> ,LAST_VALUE(id) over (partition by clazz order by score desc) as last_v_num
> ,NTILE(3) over (partition by clazz order by score desc) as ntile_num
> from new_score;
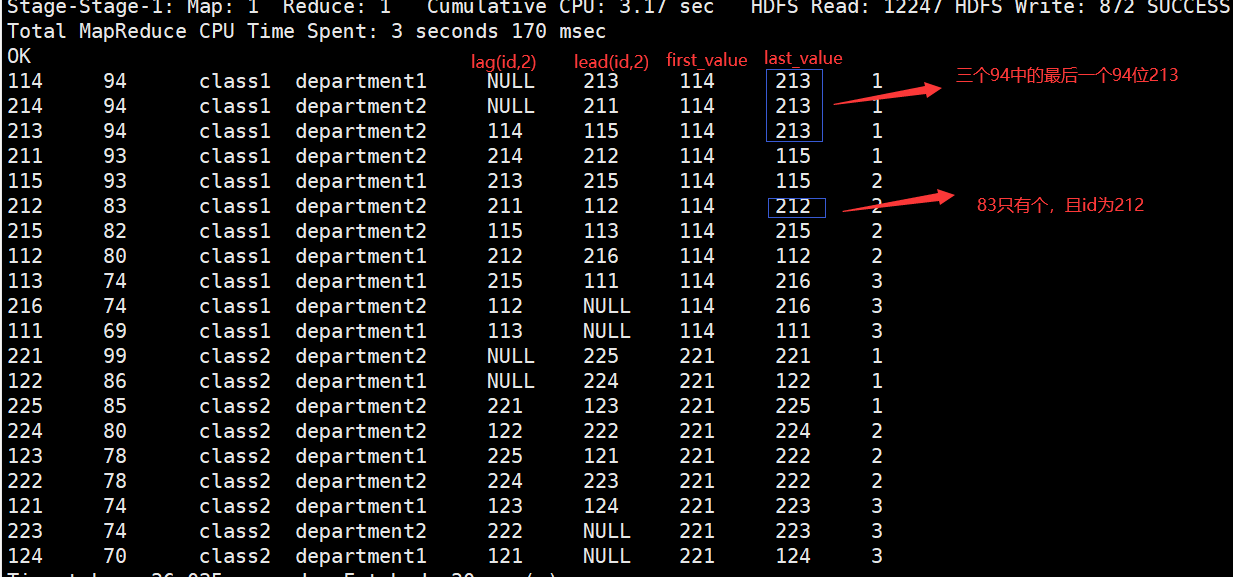
Hive行转列
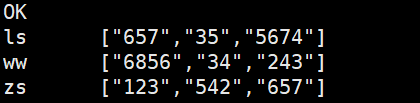
hive> select name,c from scorearr lateral view explode(score) t as c; (list集合)
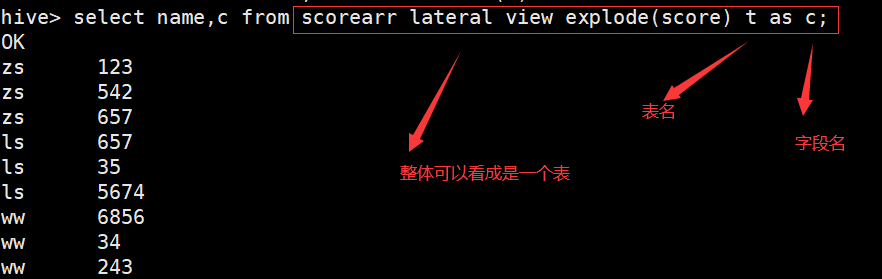
hive> select name,x,y from scoremap lateral view explode(score) t as x,y; (map集合)
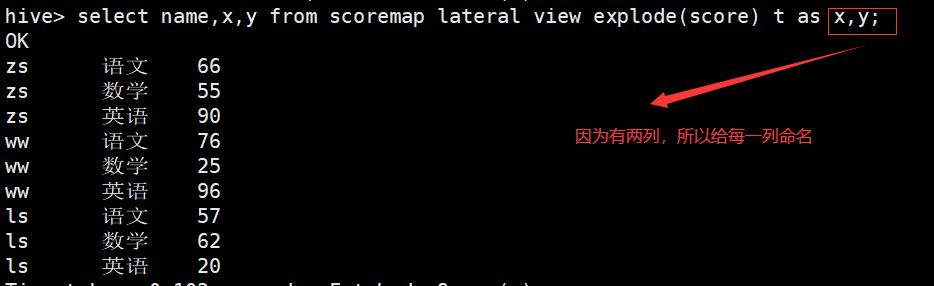
Hive列转行(Collect_list) collect_list不去重而collect_set去重
hive> select tt.name,collect_list(tt.c) from (select name,c from scorearr lateral view explode(score) t as c) tt group by tt.name;
自定义函数(UDF一进一出)
1.自定义UDF需要继承org.apache.hadoop.hive.ql.exec.UDF。
2.需要evaluate函数。
3.把程序打包放到目标机器上去;
4.进入hive客户端,添加jar包:hive> add jar /usr/local/moudle/tttt-1.0-SNAPSHOT.jar;
5.创建临时函数:hive> create temporary function a as 'hive.HiveUDF';
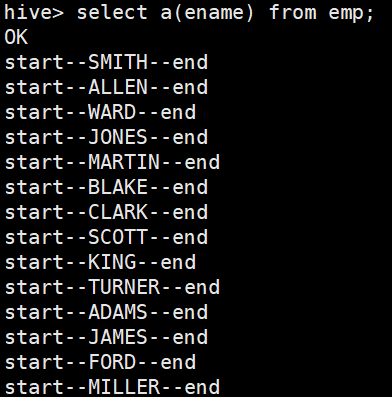
查询HQL语句:hive> select a(ename) from emp;
销毁临时函数: DROP TEMPORARY FUNCTION f_up;
import org.apache.hadoop.hive.ql.exec.UDF; public class HiveUDF extends UDF { public String evaluate(String str){ String s = "start--"+str+"--end"; return s; } }
UDTF(一进多出)
hive> add jar /usr/local/moudle/tttt-1.0-SNAPSHOT.jar;
hive> create temporary function b as 'hive.HiveUDTF';
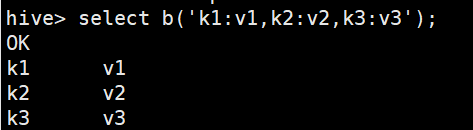
package hive; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory; import java.util.ArrayList; public class HiveUDTF extends GenericUDTF { //当前列的输出数量和输出格式(1.3.1之后隐藏) @Override public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException { //操作列的数量和名称 ArrayList<String> filedNames = new ArrayList<String>(); //操作列的类型 ArrayList<ObjectInspector> filedObj = new ArrayList<ObjectInspector>(); //第一列 filedNames.add("x"); filedObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); filedNames.add("y"); filedObj.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); return ObjectInspectorFactory.getStandardStructObjectInspector(filedNames, filedObj); } public void process(Object[] objects) throws HiveException { String s = objects[0].toString(); String[] rows = s.split(","); for (String row : rows) { String[] split = row.split(":"); forward(split); //这里需要给数组因为是一进多出 } } public void close() throws HiveException { } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号