
Hadoop的高可用搭建
在已经安装完hadoop单机和zookeeper前提下
1.免密钥
在node1下。因为node1作为备用主机,并且master我已经实现了免密
ssh-keygen -t rsa
分发秘钥
ssh-copy-id -i master
ssh-copy-id -i node1
ssh-copy-id -i node2
2.修改hadoop配置文件(我在master中修改)
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
我是直接导入文件覆盖
3.同步到其他节点
scp * node1:/usr/local/soft/hadoop-2.7.6/etc/hadoop/
scp * node1:/usr/local/soft/hadoop-2.7.6/etc/hadoop/
4.删除hadoop数据存储目录下的文件 每个节点都需要删除
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
5.启动zookeeper 三台都需要启动
zkServer.sh start
zkServer.sh status
此时一台一个zk的节点
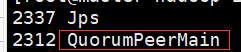
6.启动JN 存储hdfs元数据
三台JN上执行 启动命令: hadoop-daemon.sh start journalnode
此时一台一个zk节点,一个jn日志节点
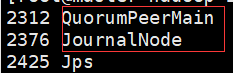
7.格式化 在一台NN上执行
hdfs namenode -format
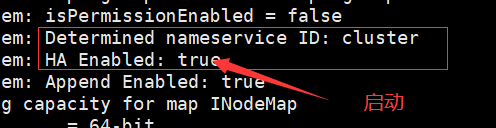
启动当前的NN
hadoop-daemon.sh start namenode
此时master上多了个namenode节点
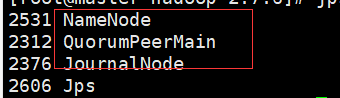
8.执行同步 没有格式化的NN上执行 在另外一个namenode上面执行
hdfs namenode -bootstrapStandby
这是node1上还没有namenode节点很正常,还没有启动hdfs
9.格式化ZK
在已经启动的namenode上面执行 !!一定要先 把zk集群正常 启动起来 hdfs zkfc -formatZK
10.启动hdfs集群,在启动了namenode的节点上执行
start-dfs.sh
master上:

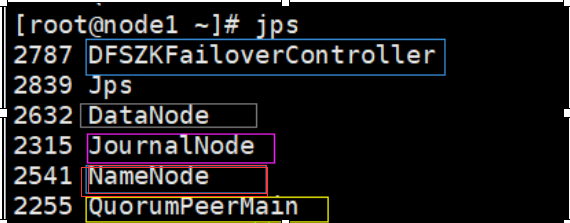
node1上:
node2上:
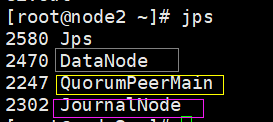
黄色:QuorumPeerMain:zk的节点,三台都有 3个
粉色:JournalNode:jn日志节点,三台都头 3个
红色:Namenode:管理节点:出现在master和node1上 2个
蓝色:DFSZKFailoverController:ZKFC:用来观察master和node1,防止宕机时可以替代 2个
灰色:DataNode:工作节点,用于存储hdfs数据,出现在node1和node2上 2个
一共12个节点此时
11.启动yarn 在master启动
start-yarn.sh
master:多了一个ResourceManager节点,用于处理整个集群资源的总节点
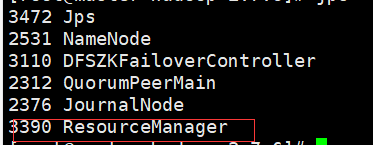
node1和node2上:多个NodeManger节点,用于跟踪监视资源
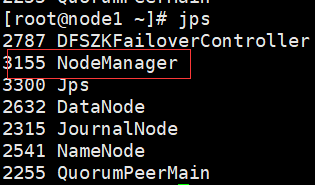
此时多了一个ResourceManager节点和2个NodeManager节点
12.在另外一台主节点上启动RM
yarn-daemon.sh start resourcemanager
此时node1上:多个一个nNodeManager节点,用于备份
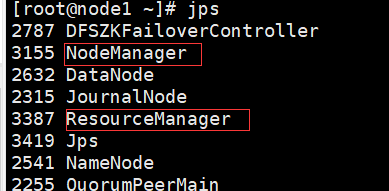
此时node1多了个 ResourceManager节点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号