
redis命令
基本命令
进入redis下的bin目录启动redis-cli
Ctrl+C便可以退出redis模式
ps -aux|grep redis:查看当前redis当前进程
kill -9 xxx(端口号):关闭进程
./redis-server redis.conf:开启进程(在bin目录下)
nohup redis-server redis.conf &:后台启动(bin目录下)
flushad:清空当前数据库
flushall:清空所有数据库
keys * :查看当前数据库key值
exists name:判断name的key是否存在,存在返回1,不存在返回0
![]()
expire name 10:倒计时10秒钟后过期
ttl name:查看当前还剩多少秒
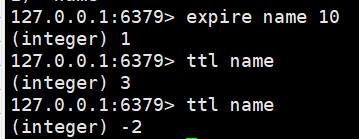
type name:查看当前key类型
select 0-15:选择第几个数据库,redis一共只有16个数据库
Spring
append name "hello":追加字符串,如果key不存在就相当于setkey
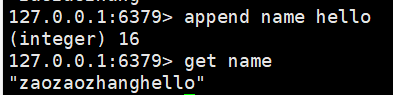
strlen name:查看字符串长度
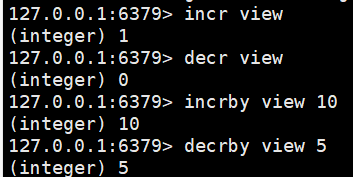
incr view:自增1
decr view:自减1
incrby view 10:增加10
decrby view 5:减5
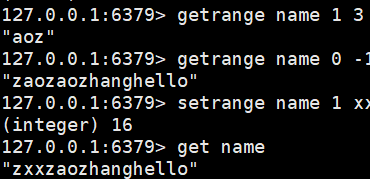
getrange name 1 3:截取下标1到3的字符
getrange name 0 -1:所有字符串
setrange name 1 xx:从位置1开始替换字符串
setex:设置过期时间
setnx:如果不存在就创建key
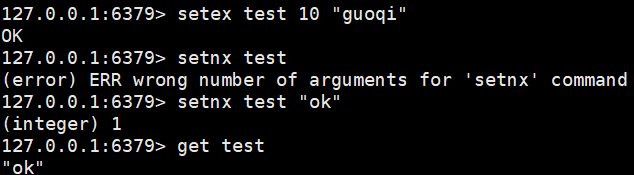
mset:批量设置值
mget:批量获取值
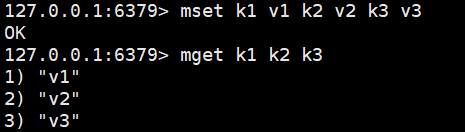
msetnx:原子性操作,要么一起成功要么一起失败

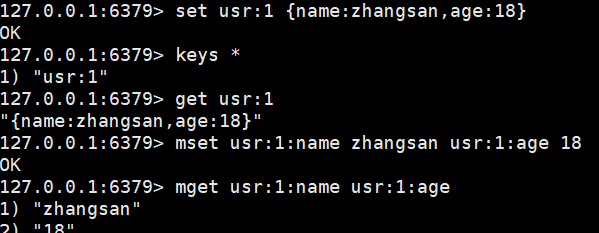
存储对象格式
set usr:1 {name:zhangsan,age:18}:json格式
mset usr:1:name zhangsan usr:1:age 18
getset:先get再set 如果不存在值返回null,如果存在值,获取原来的值,设置新的值

Set
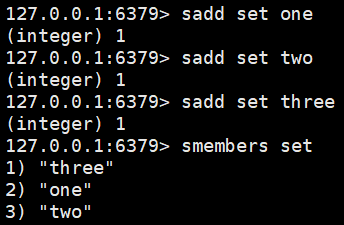
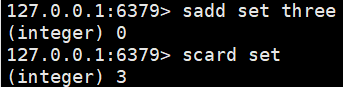
sadd set one:set集合中添加元素(无序不重复)
smembers set:查看set所有值
sismember set one:判断某个值在不在set集合中
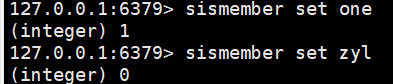
scard set:获取set集合中的元素个数
srem set three:移除set中的元素
SRANDMEMBER key [count]
如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。
如果 count 大于等于集合基数,那么返回整个集合
如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值
如果 count 为 0,返回空 如果 count 不指定,随机返回一个元素
srandmember set:随机抽选出一个元素
srandmember set 2:随机抽出指定个数元素
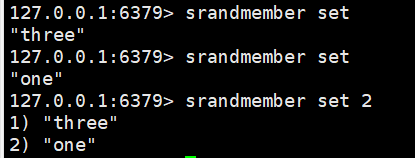
spop set:随机删除指定元素
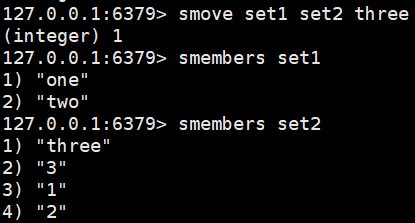
smove set1 set2 three:将set1中指定的值移动到set2中
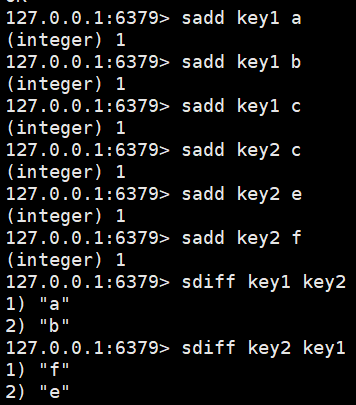
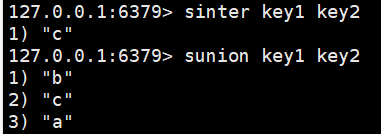
差集:sdiff
交集:sinter
并集:sunion
Zset(Sorted Sets)有序集合
ZADD key score member [score member ...]
zadd zset 1 one:添加一个值,相比set来说只是多一个修饰1
zadd zset 2 two 3 three:添加多个值

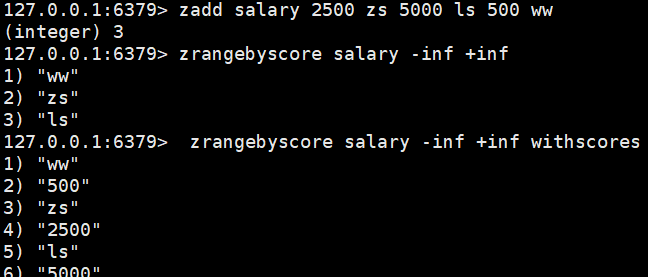
zrangebyscore salary -inf +inf:从小到大排序
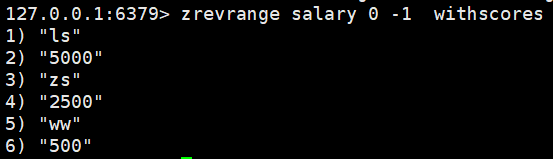
zrevrange salary 0 -1 withscores:从大到小排序
zrangebyscore salary -inf +inf withscores:添加一个参数
ZREM key member [member ...] 移除一个或多个值
zrem salary zs:移除指定元素 zcard salary:获取有序集合个数
List
基本所有的list命令都是用 l 开头,实际上是一个双向链表,有序可重复
lpush list one:将一个值或者多个值插入列表头部(插入内容是倒叙的)
rpush list four:正序插入
-----------l对头部进行操作,r对尾部进行操作,且可以插入重复的值
lrange lIst 0 -1:查看list中的值
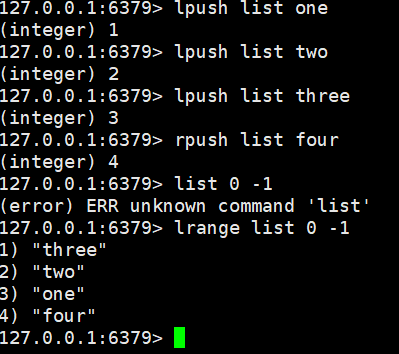
lpop list:移除list的第一个值
rpop list:移除list的最后一个值
lindex list 1:查看下标索引为1的值
llen list:查看当前list长度
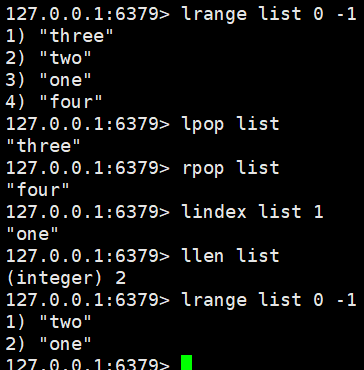
lrem list 1 one
lrem list 2 three:移除指定数量的值,返回移除数量
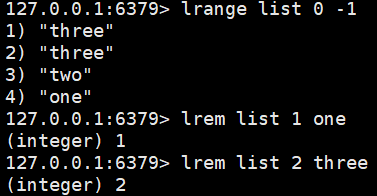
ltrim list 1 3:截取索引1到3的字符串
rpoplpush list1 list2:移除list1最后一个元素放到list2第一个
注意:只能rpoplpush,其他的都是错误
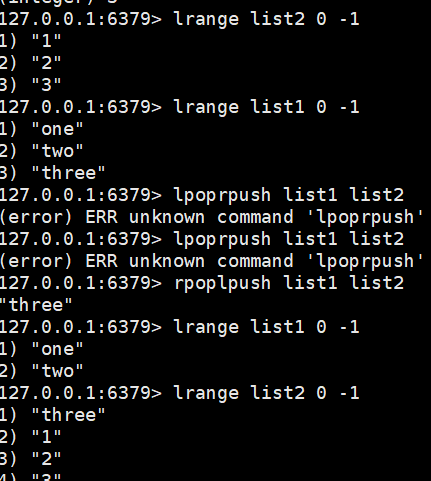
lset list 1 111:将list中索引为1的内容进行修改,如果不存在就报错
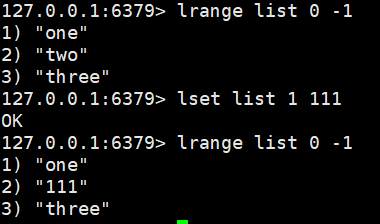
linsert list before two 222:在list中字符串之前插入
linsert list after two 333:在list中字符串之后插入
Hash(哈希)
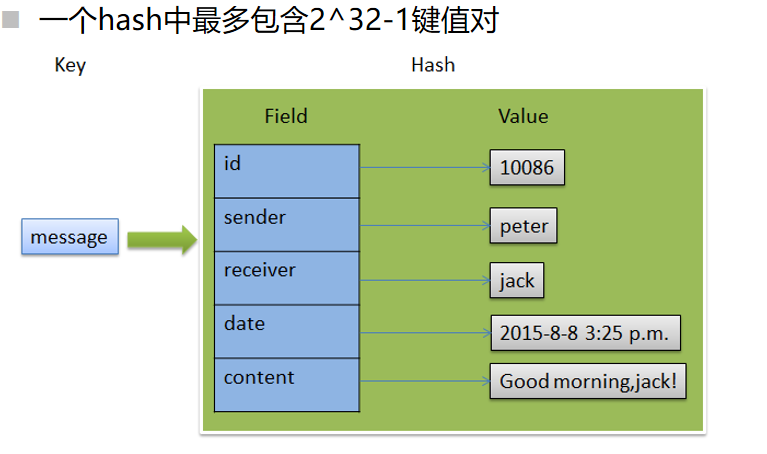
本质是一个key-map集合 key-(key-value)
hset first name1 zyl:赋值
hget first name1:获取值
hmset first name2 zzz name3 yyy:批量赋值
hmget first name1 name2:批量获取值
hgetall first:同上

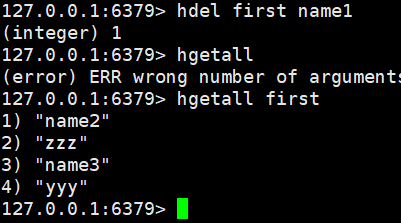
HDEL key field [field ...]:删除指定字段
hdel first name1:删除hash指定的key
在字段对应的值上进行整数的增量计算 HINCRBY key field increment
在字段对应的值上进行浮点数的增量计算 HINCRBYFLOAT key field increment
hlen first:获取hash表长度
hexists first name2:判断指定字段是否存在

hkeys first:获取所有key值
hvals first:获取所有value值
hincrby xxx key 1:value值加1
hsetnx xxx key xx:如果不存在xx 就创建
可以用来存储用户信息
Geospatial地理位置
geoadd:添加地理位置
geoadd china:city 120.16 30.24 hangzhou 108.96 34.26 xian
geopos:获取指定城市的经纬度
geopos china:city hangzhou
geodist:两人之间的距离
geodist china:city hangzhou xian km
georadius:查找指定坐标半径内的城市
georadius china:city 110 30 500km
georadius china:city 110 30 500km withcoord count 3 :限制数量
georadiusbymember:查找指定城市半径内的城市
georadiusbymember china:city shanghai 500km
geohash:将二维的经纬度转换为一维的字符串(降维打击)
geohash china-city hangzhou xian
Hyperloglog
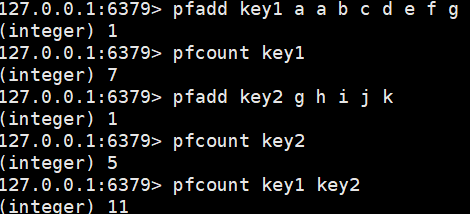
pfadd:添加元素
pfcount:统计元素个数,重复元素只算一次
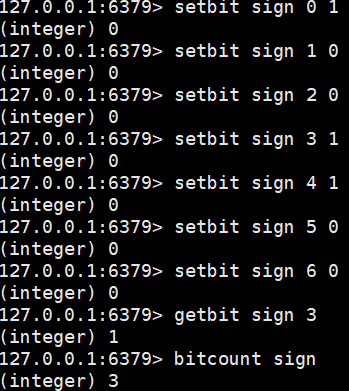
Bitmaps(位存储)
可以判断打卡记录
事务
redis事务本质:一组命令的集合
redis事务没有隔离性的概念,且不保证原子性只有单条命令保存
开始事务:multi
执行事务:exec
放弃事务:discard
多线程测试redis的乐观锁
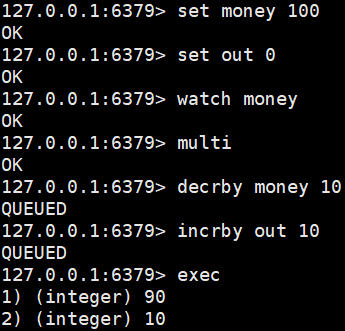
如果在watch之下多线程进行修改值就会exec报错
![]()
如果发现事务执行失败可以先unwatch解锁
idea连接redis
pom.xml文件中导入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
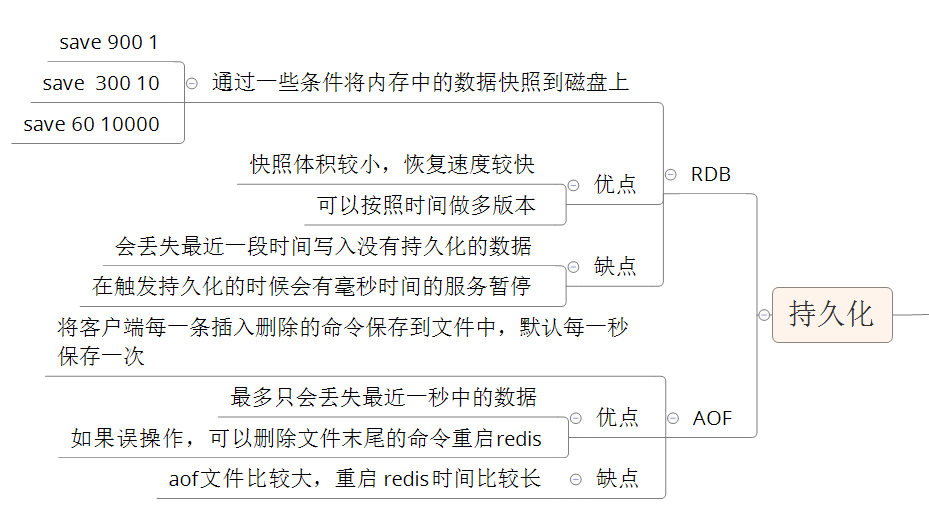
Redis持久化:RDB和AOF
RDB:
自动:RBD持久化默认将数据库快照保存在dump.rdb二进制文件内,是以bgsave命令保存的,可以通过更改配置调节里面的属性

手动:
save命令:会阻塞当前redis使其暂时不能相应客户端请求,且每一次save都会创建新的dump.rdb替代旧的
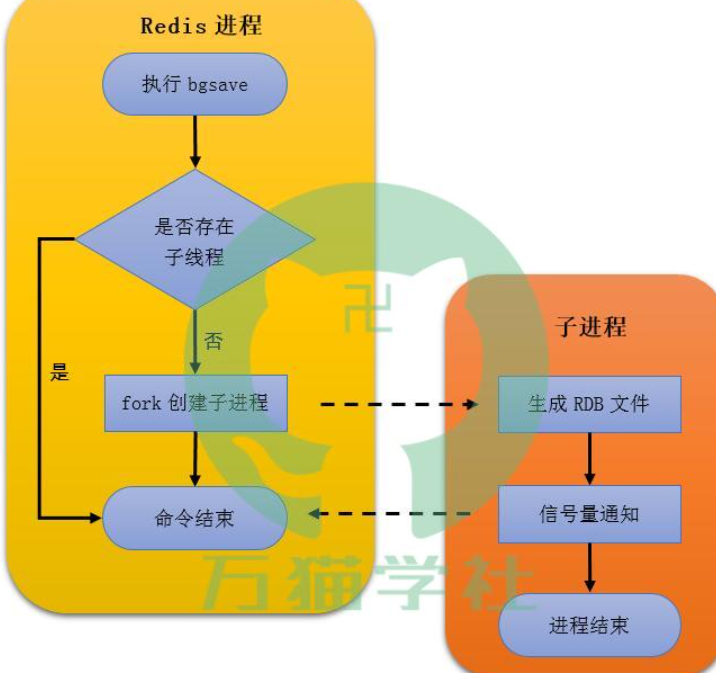
bgsave命名:不会阻塞,但会folk()一个当前的子进程,子进程创建edb文件并告知服务器
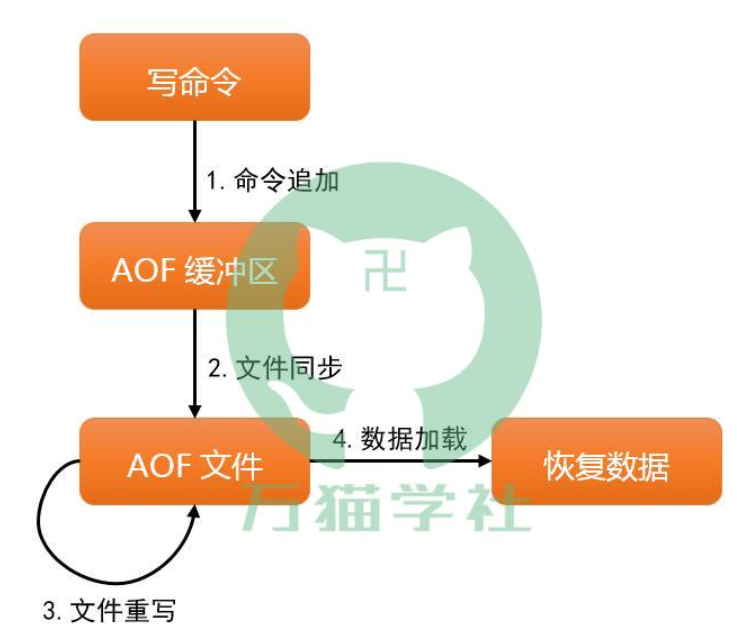
AOF:
默认关闭,在配置文件中 appendonly yes 开启
![]()
AOF默认采用追加的方式来保存,保存的默认文件是appendonly.aof,且是基于磁盘的,aof是以一条条命令存储的而rdb是结果存储,所有当服务器出现问题,aof的损失会小很多
AOF写入磁盘通常有三种:Everysec(默认),服务器每一秒重调用一次fdatasync
Always:服务器每写入一个命令,就调用一次fdatasync
No:服务器不主动调用fdatasync,由操作系统决定何时将缓冲区里面的命令写入到硬盘
always最慢,其他都很快
AOF的重写机制:当文件过大时(大于64MB时),多次重写需要文件的增量大于起始size的100%时(就是文件大小翻了一倍),AOF会合并重复的操作,减少命令行,如果出现故障可以使用redis-check-aof工具修复
- 手动触发:使用
bgrewriteaof命令。 - 自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage配置确定自动触发的时机。
缓存穿透、击穿和雪崩
缓存穿透:指查询一个一定不存在的数据。用户查询一个数据,redis缓存和mysql数据库中都没有,那么当大量请求都没命中时就会穿透,给数据带来压力
解决方案有两种; 1.布隆过滤器 2缓存空对象
布隆过滤器:将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。在击穿缓存时,先查一下布隆过滤器,如果不存在,则不查db,一定程度保护了db层。
缓存空对象:将null变成一个值,通常将其设置一个较短的过期时间,节省内存空间
缓存击穿:是指一个非常热点的key,在不停的扛着大并发,当这个key失效时,一瞬间大量的请求冲到持久层的数据库中,就像在一堵墙上某个点凿开了一个洞!
解决方案:设置key值永不过期,互斥锁
缓存穿透,与击穿的区别就是,击穿:数据库里“有”数据;穿透:数据库里“没”数据。
缓存雪崩:指的是大面积的 key 同时过期,导致大量并发打到我们的数据库。不像击穿,只是因为 1 个 key 的过期。
解决方案:分散key的过期时间
Redis集群
主从复制 Replication:
1.只要网络连接正常,Master会一直将自己的数据更新同步给Slaves,保持主从同步
2.只有Master可以执行写命令,Slaves只能执行读命令
3.一个Redis服务可以有多个该服务的复制品,这个Redis服务称为Master,其他复制品称为Slaves
总结:
一个Master可以有多个Slaves Slave下线,只是读请求的处理性能下降 Master下线,写请求无法执行 其中一台Slave使用SLAVEOF no one命令成为Master,其它Slaves执行SLAVEOF命令指向这个新的Master,从它这里同步数据 以上过程是手动的,能够实现自动,这就需要Sentinel哨兵,实现故障转移Failover操作
Redis集群:
1.由多个Redis服务器组成的分布式网络服务集群 ,每一个Redis服务器称为节点Node,节点之间会互相通信。
2.每个节点都有两种角色可选,主节点master node、从节点slave node。其中主节点用于存储数据,而从节点则是某个主节点的复制品,也可以通过增加节点拓展系统的拓展性
3.故障转移:Redis集群的主节点内置了类似Redis Sentinel(哨兵)的节点故障检测和自动故障转移功能,当集群中的某个主节点下线时,集群中的其他在线主节点会注意到这一点,并对已下线的主节点进行故障转移
4.集群分片:集群将整个数据库分为16384个槽位slot,集群中的每个主节点都可以处理0个至16383个槽,当16384个槽都有某个节点在负责处理时,集群进入上线状态,并开始处理客户端发送的数据命令请求
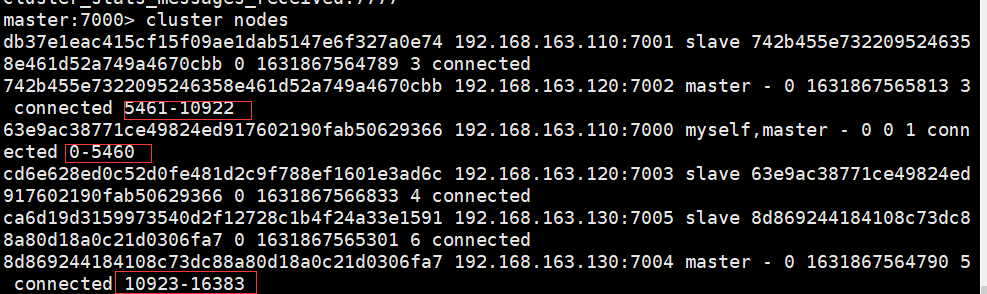
5.Redis集群Redirect转向:由于Redis集群无中心节点,主节点只会处理自己负责槽位的命令请求,其它槽位的命令请求,该主节点会返回客户端一个转向错误,客户端根据错误中包含的地址和端口重新向正确的负责的主节点发起命令请求 命令:redis-cli -p 7000 -h master -c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号