
Mysql
DQL(数据查询语言): 查询语句,凡是select语句都是DQL。
DML(数据操作语言):insert delete update,对表当中的数据进行增删改。
DDL(数据定义语言):create drop alter,对表结构的增删改。
TCL(事务控制语言):commit提交事务,rollback回滚事务。(TCL中的T是Transaction)
DCL(数据控制语言): grant授权、revoke撤销权限等
关系型:以行作为记录,列数相同(mysql)
非关系型:以列作为记录,行数随便
查看当前是哪个数据库:select database();
查看数据库版本号:select version();
删除数据库:drop database bjpowernode;
查看表属性:desc emp;
查看创表语句:show create table emp;
简单DQL语句:
select 字段,字段 from 表名 where 条件;(先from 再where 最后select)
1.select sal from emp where enam='smith';
2.select sal from emp where sal !=3000;
3.select sal from emp where sal between 1100 and 3000; (左闭右闭)
4.select ename,sal,comm from emp where comm is null; (null 只能用is 或者 is not 来找)
and 是&& or是||
5.select ename,job from emp where sal>1000 and (deptno=10 or deptno=20);因为and优先级高于or,用括号
6.select ename,job from emp where job='manager' or job='salesman';
select ename,job from emp where job in('manager','salesman'); in等同于or
7.select ename,job from emp where sal not in(800,5000); 不在这几个值当中
8. %表示多个字符。_表示任意一个字符 当出现要查找_符号时 使用 \_ 来转义
select name from emp where ename like '% \_ %';
9.降序升序排序
mysql> select ename,sal from emp order by sal; (升序)
mysql> select ename,sal from emp order by sal desc; (降序)
mysql> select ename,sal from emp order by sal asc; (asc可以省去,是升序排序)
mysql> select ename,sal from emp order by sal asc,ename asc;(先sal排序,相同再ename排序)
mysql> select ename,empno,sal from emp order by 3;(对第三列sal进行升序)
找出薪资再1250到3000的薪资降序(先执行from,然后where,然后select,然后order by )
mysql> select ename,sal from emp where sal between 1250 and 3000 order by sal desc;
10.常见单行处理函数:
(1)lower 转换小写
mysql> select lower(ename) from emp;
(2)upper转换大写
mysql> select upper(ename) from emp;
(3)substr取子串(索引从1开始)
mysql> select substr(enmae,1,2) from emp;
找出员工名字第一个字母为a的员工
mysql> select ename from emp where ename like 'a%';
mysql> select ename from emp where substr(ename,1,1)='a';
输出第一个字母小写后面大写
mysql> select concat(lower(substr(ename,1,1)),substr(ename,2,length(ename)-1)) from emp;
(4)round四舍五入 0是小数点那位 可以为-1,1等等
mysql> select round(sal,-1) from emp;
(5)rand生成随机数(0-1)的随机数
mysql> select round(rand()*100,0) from emp; (生成1-100的随机数)
(6)iffull是空处理函数,在所有数据库中,只要有null参与运算结果都为null;
mysql> select ename,(sal+comm)*12 as 'yearmoney' from emp; (有null值所有不能这样操作)
mysql> select ename,(sal+ifnull(comm,0))*12 as 'yearmoney' from emp;
(7)case..when..then...when..then...else...end
mysql> select ename,job,sal as oldsal,
(case job when 'manager' then sal*1.1 when 'salesman' then sal*1.5 else sal end) as newsal
from emp;
11.分组函数(多行处理函数) 自动忽略null 不能直接的使用在where后面
(1)count 计数 count(*) 统计表中总行数
(2)sum 求和
(3)avg 平均数
(4)max 最大值
(5)min 最小值
mysql> select count(sal),sum(sal),max(sal),min(sal),avg(sal),count(*) from emp;
12.分组查询
select ... from ... where ... group by ... having ... order by... limit ...
顺序是 1.from 2.where 3.group by 4.having 5.select 6.order by 7.limit..
在一条select语句当中,如果有group by语句的话,select后面只能跟:参加分组的字段,以及分组函数。其它的一律不能跟。
找出“每个部门,不同工作岗位”的最高薪资?
mysql> select job,deptno,max(sal) from emp group by job,deptno;
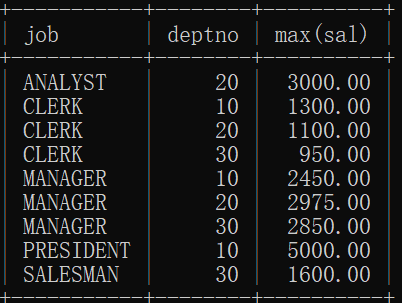
找出每个部门最高薪资,要求显示最高薪资大于3000的?
mysql> select deptno,max(sal) from emp where sal>3000 group by deptno;

也可以使用having对分完组的数据进行过滤
mysql> select deptno,max(sal) from emp group by deptno having max(sal)>3000;
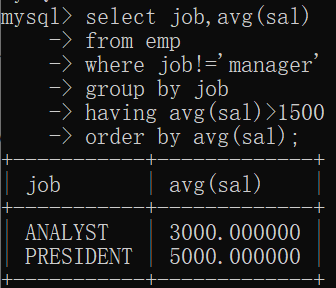
找出每个岗位的平均薪资,要求显示平均薪资大于1500的,除MANAGER岗位之外,要求按照平均薪资降序排。
13.查询的结果一=取出重复记录 distinct
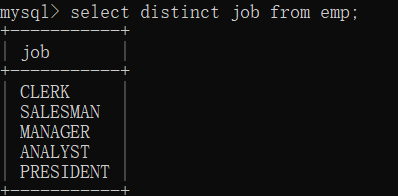
distinct出现在job,deptno两个字段之前,表示两个字段联合起来去重。
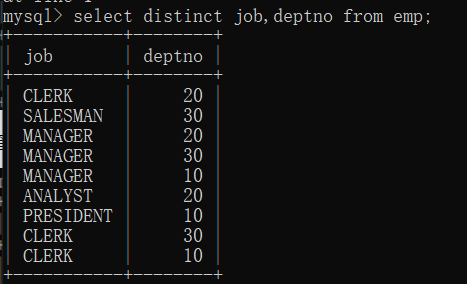
统计一下工作岗位的数量?
mysql> select count(distinct job) from emp;
14.SQL92 SQL99
内连接:
等值连接
非等值连接
自连接
外连接:
左外连接(左连接)
右外连接(右连接)
SQL92:结构不清晰,表的连接条件,和后期进一步筛选的条件,都放到了where后面。

SQL99:(其中 jion 前可以加 inner 表示内连接)表连接的条件是独立的,连接之后,如果还需要进一步筛选,再往后继续添加where
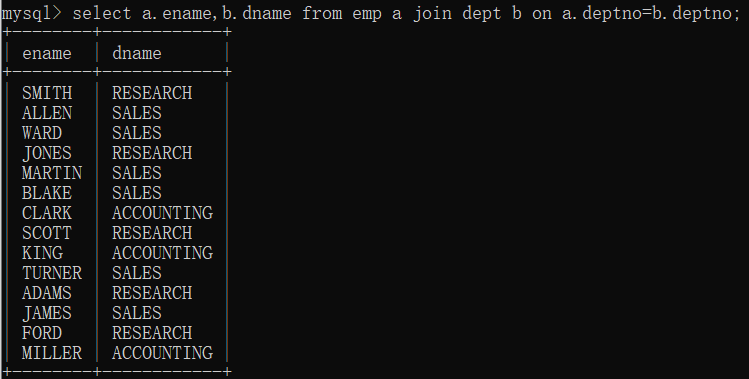
内连接之非等值连接:找出每个员工的薪资等级,要求显示员工名、薪资、薪资等级?
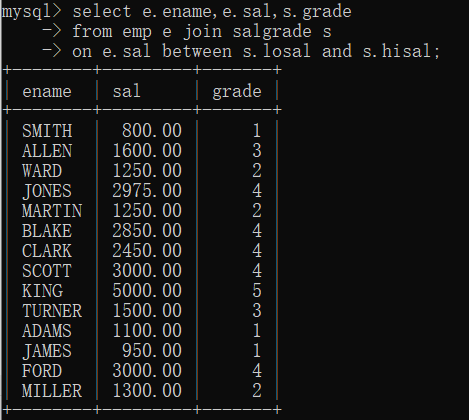
内连接之自连接:查询员工的上级领导,要求显示员工名和对应的领导名?
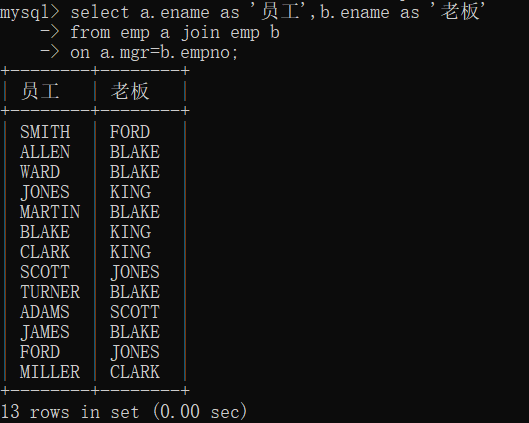
没有king,13条记录
前面的都是内连接没有主次之分,平等的。外连接:右外连接(right) 和 左外连接(left)
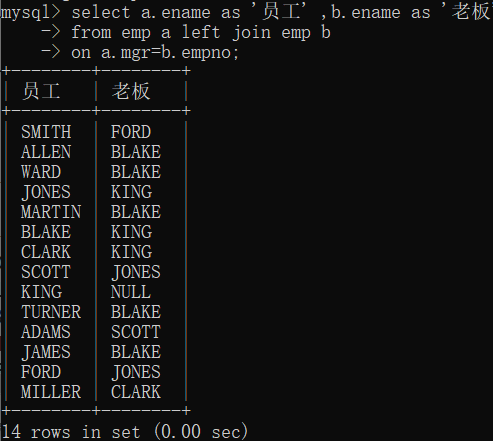
外连接的查询结果条数一定是 >= 内连接的查询结果条数?
查询每个员工的上级领导,要求显示所有员工的名字和领导名?(因为 mgr 有null值,所有要将其为主,全部输出)
15.三张表,四张表怎么连接?
select ...
from a join b
on a和b的连接条件
join c
on a和c的连接条件
right join d
on a和d的连接条件
找出每个员工的部门名称以及工资等级,还有上级领导,要求显示员工名、领导名、部门名、薪资、薪资等级?
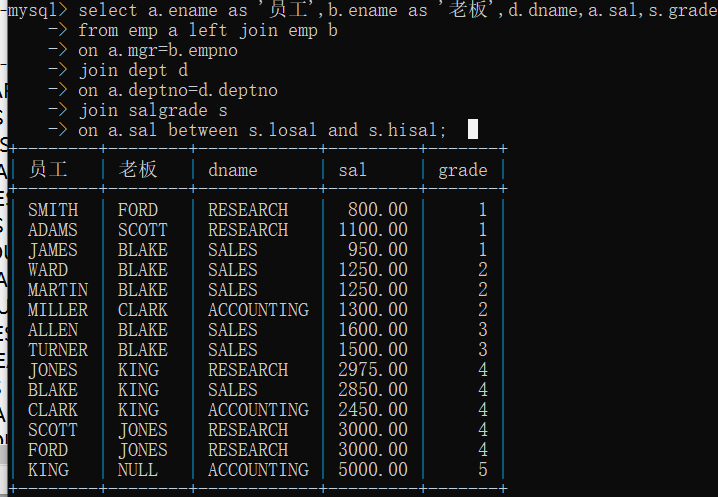
union合并查询结果集(要求两个结果的列数相同)
查询工作岗位是MANAGER和SALESMAN的员工?

union效率更高,减少了笛卡尔积的次数,前者3+4=7后者3 *4=12

limit: limit startIndex, length(满足数组的索引方式),limit在order by之后执行
缺省用法:limit 5 :表示取前五
取出工资降序排名在[5-9]名的员工?
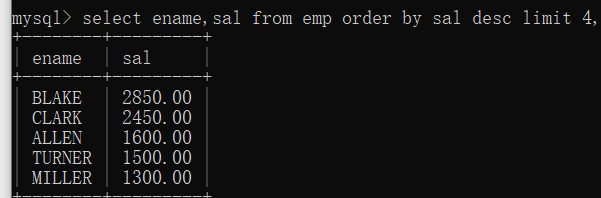
TopN:前几条数据
1.TopN age最大的前三个
select * from students order by age desc limit 0,3;
2.分组Top1 按sex分组后,求分组中年龄最大的一个
1.select * from students where age in (select max(age) m from students group by sex);
2.select * from students as stu1 where age=(select max(age) from students as stu2 where stu1.sex=stu2.sex);
2.分组TopN 按sex分组后,求分组中年龄最大的三个
select * from students as stu1 where 3>(select count(*) students as stu2 where stu1.sex=stu2.sex and stu1.age<stu2.age);
5.6、分页
每页显示3条记录
第1页:limit 0,3 [0 1 2]
第2页:limit 3,3 [3 4 5]
第3页:limit 6,3 [6 7 8]
第4页:limit 9,3 [9 10 11]
每页显示pageSize条记录
第pageNo页:limit (pageNo - 1) * pageSize , pageSize
DDL语句(创表语句): create drop alter
create table 表名 (字段名1 数据类型 .... ,
字段名2 数据类型 .... )engine innodb default charset=utf8
create table 表名 as select * from 表名; (将查询结果创建新表。表的快速复制)
drop table 表名
alter table 表名 rename as xxxx
alter table 表名 add 字段名 数据类型
alter table 表名 modify 字段名 数据类型(修改数据类型,字段名一样)
alter table 表名 change 原字段名 新字段名 数据类型(可以修改字段名和数据类型)
alter table 表名 drop 字段名
数据类型:
varchar(最长255)
可变长度的字符串
比较智能,节省空间。
会根据实际的数据长度动态分配空间。
优点:节省空间
缺点:需要动态分配空间,速度慢。
char(最长255)
定长字符串
不管实际的数据长度是多少。
分配固定长度的空间去存储数据。
使用不恰当的时候,可能会导致空间的浪费。
优点:不需要动态分配空间,速度快。
缺点:使用不当可能会导致空间的浪费。。
int(最长11)
数字中的整数型。等同于java的int。
bigint
数字中的长整型。等同于java中的long。
float
单精度浮点型数据
double
双精度浮点型数据
date
短日期类型:只包括年月日
str_to_date函数可以把字符串varchar转换成日期date类型数据 str_to_date('01-10-1990','%d-%m-%Y')
date_format 日期类型转换成特定格式的字符串。 date_format(birth, '%m/%d/%Y')
datetime now()获取系统当前时间
长日期类型:包括年月日分秒信息
clob
字符大对象
最多可以存储4G的字符串。
比如:存储一篇文章,存储一个说明。
超过255个字符的都要采用CLOB字符大对象来存储。
Character Large OBject:CLOB
blob
二进制大对象
Binary Large OBject
专门用来存储图片、声音、视频等流媒体数据。
往BLOB类型的字段上插入数据的时候,例如插入一个图片、视频等,
你需要使用IO流才行。
DML(对表内容):insert,update,delete
insert into 表名(字段名1,字段名2...)values (值1,值2..) 如果字段省略就是给所有都写上
insert into 表名(字段名1,字段名2...)values (值1,值2..),(值1,值2..)插入多条
注意:insert语句但凡是执行成功了,那么必然会多一条记录。没有给其它字段指定 值的话,默认值是NULL。
update 表名 set 字段名1=值1,字段名2=值2 ... where 条件 (没有条件限制会导致所有数据全部更新)
delete from 表名 where 条件(没有条件,整张表的数据会全部删除!)
delete语句删除数据的原理?(属于DML操作,删除所有数据但不会释放内存)
表中的数据被删除了,但是这个数据在硬盘上的真实存储空间不会被释放!!!
这种删除缺点是:删除效率比较低。
这种删除优点是:支持回滚,后悔了可以再恢复数据!!!
truncate语句删除数据的原理?(属于DDL操作,直接删除表,然后复原表补空白)
这种删除效率比较高,表被一次截断,物理删除。
这种删除缺点:不支持回滚。
这种删除优点:快速。
约束:在创建表的时候,我们可以给表中的字段加上一些约束,来保证这个表中数据的完整性、有效性!!
非空约束:not null 只有列级约束。没有表级约束 name varchar(255) not null,
唯一性约束: unique 约束字段不能重复。但可以为null name varchar(255), unique,
实现两个字段的约束 unique(name,email) // 约束没有添加在列的后面,这种约束被称为表级约束。
表级约束:给多个字段联合起来添加某一个约束的时候,需要使用表级约束。
not null 和 unique联合约束的话,该字段自动变成主键 name varchar(255) not null unique
主键约束: primary key (简称PK) auto_increment 从1开始自增
任何一张表都应该有一个主键,没有主键,表无效!!
id int primary key, //列级约束 primary key(id) // 表级约束
id和name联合起来做主键:复合主键 primary key(id,name)
外键约束:foreign key(简称FK) 将两个表连接,使其子的约束字段限定在一定的范围内
foreign key() references 表()用在子的创建列表中
删除表的顺序?先删子,再删父。
创建表的顺序?先创建父,再创建子。
删除数据的顺序?先删子,再删父。
插入数据的顺序?先插入父,再插入子
思考:子表中的外键引用的父表中的某个字段,被引用的这个字段必须是主键吗?
不一定是主键,但至少具有unique约束。
测试:外键可以为NULL吗?
外键值可以为NULL。
检查约束:check(mysql不支持,oracle支持)
日期函数:
获取当前日期:
current_timestamp;--所有
current_timestamp();--所有
CURRENT_DATE();-- 年月日
CURRENT_DATE;-- 年月日
CURRENT_TIME();-- 时分秒
CURRENT_TIME;-- 时分秒
SELECT now(); --2021-09-06 20:09:22 SELECT CURRENT_TIMESTAMP(); --2021-09-06 20:09:22 SELECT CURRENT_DATE(); --2021-09-06 SELECT CURRENT_TIME(); --20:09:22
时间转str:date_format(date,format)
str转日期:str_to_date(str,format)
日期相减:DATEDIFF(expr1,expr2);
SELECT DATE_FORMAT(NOW(),'%Y%m%d-%H%i%s'); --20210906-201234 SELECT STR_TO_DATE('2018/11/4 12:55:12','%Y/%m/%d %h:%i:%s'); --2018-11-04 00:55:12 SELECT DATEDIFF(NOW(),'2021-9-3'); --3 SELECT TIMEDIFF(CURRENT_TIME(),'19:12:11'); --01:00:24
函数向日期添加指定的时间间隔:DATE_ADD(date,INTERVAL expr unit);
SET @t='2021-09-06 20:02:39'; SELECT DATE_ADD(@t,INTERVAL 1 YEAR); --2022-09-06 20:02:39 SELECT DATE_ADD(@t,INTERVAL 2 HOUR); --2021-09-06 22:02:39 SELECT DATE_ADD(@t,INTERVAL '1:12:30' HOUR_SECOND); --2021-09-06 21:15:09 SELECT DATE_ADD(@t,INTERVAL '1-1' YEAR_MONTH ); --2022-10-06 20:02:39
数组计算
round(x,d):四舍五入
x:值
d:保留几位小数点
ceil(x):向上取整
floor(x):向下取整
rand():随机数(0-1之间)
SELECT ROUND(2.3); --2 SELECT ROUND(2.3,2); --2.3 SELECT CEIL(2.3); --3 SELECT FLOOR(2.3); --2 SELECT RAND(); --0.20764462017234844
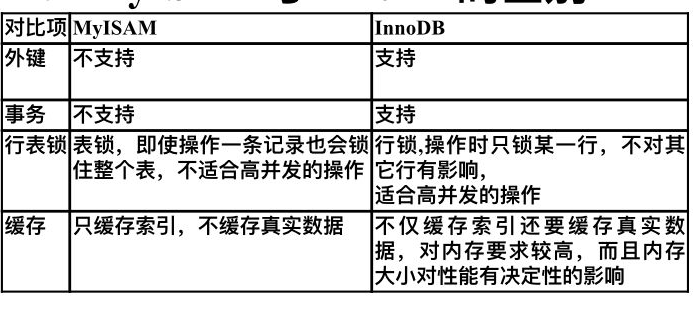
存储引擎: show engines \G 查看mysql支持那些存储引擎
mysql默认的存储引擎是:InnoDB mysql默认的字符编码方式是:utf8 engine=InnoDB default charset=gbk;
事务(只有DML才有):一个事务其实就是一个完整的业务逻辑。是一个最小的工作单元。不可再分。
mysql默认情况下是支持自动提交事务的。(自动提交)
先start transaction 然后最后commit 或者 collback
事务的四个特性
A:原子性
说明事务是最小的工作单元。不可再分。
C:一致性
所有事务要求,在同一个事务当中,所有操作必须同时成功,或者同时失败,
以保证数据的一致性。
I:隔离性
A事务和B事务之间具有一定的隔离。
教室A和教室B之间有一道墙,这道墙就是隔离性。
A事务在操作一张表的时候,另一个事务B也操作这张表会那样???
D:持久性
事务最终结束的一个保障。事务提交,就相当于将没有保存到硬盘上的数据
保存到硬盘上!
索引:一张表的一个字段可以添加一个索引,当然,多个字段联合起来也可以添加索引。
1.在任何数据库当中主键上都会自动添加索引对象,id字段上自动有索引,因为id是PK(primary key)。另外在mysql当中,一个字段上如果有unique约束的话,也会自动创建索引对象。
2.在mysql当中,索引是一个单独的对象,不同的存储引擎以不同的形式存在,在MyISAM存储引擎中,索引存储在一个.MYI文件中。在InnoDB存储引擎中索引存储在一个逻辑名称叫做tablespace的当中。在MEMORY存储引擎当中索引被存储在内存当中。不管索引存储在哪里,索引在mysql当中都是一个树的形式存在。(自平衡二叉树:B-Tree)
创建索引:create index emp_ename_index on emp(ename)
删除索引:drop index emp_ename_index on emp
检索索引:explain select * from emp where ename='KING'
索引失效的五种情况:
有like 模糊时以 %d开头语查询索引h
使用or的时候会失效,如果使用or那么要求or两边的条件字段都要有索引,才会走索引,如果其中一边有一个字段没有 索引,那么另一个字段上的索引也会实现
使用复合索引的时候,没有使用左侧的列查找,索引失效
在where当中索引列参加了运算,索引失效。
在where当中索引列使用了函数
视图:由查询结果得到的一张虚拟表(临时表,虚表),虚拟表和基本表有一对一和一对多的关系
一对一(数据和基本表一样):增删改查
一对一(数据由基本表聚合):查
一对多(数据由基本表聚合):查
一对多(数据由连表联查):查改
创建视图对象:create view dept2_view as select * from dept2
删除视图对象:drop view dept2_view

 浙公网安备 33010602011771号
浙公网安备 33010602011771号