个人博客项目笔记_05
1|01. ThreadLocal内存泄漏
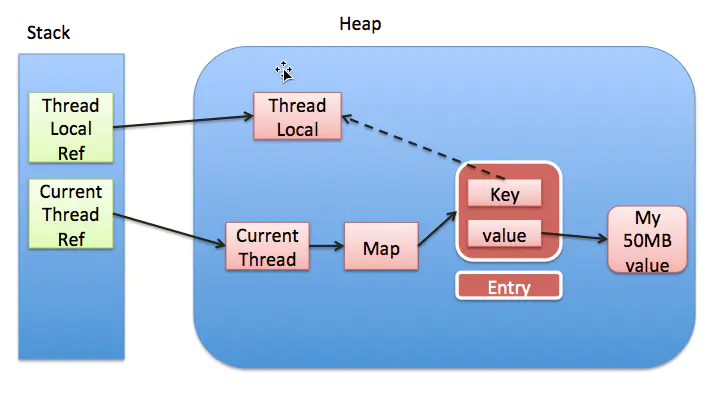
ThreadLocal 内存泄漏是指由于没有及时清理 ThreadLocal 实例所存储的数据,导致这些数据在线程池或长时间运行的应用中累积过多,最终导致内存占用过高的情况。
内存泄漏通常发生在以下情况下:
- 线程池场景下的 ThreadLocal 使用不当: 在使用线程池时,如果线程被重用而没有正确清理 ThreadLocal 中的数据,那么下次使用这个线程时,它可能会携带上一次执行任务所遗留的数据,从而导致数据累积并消耗内存。
- 长时间运行的应用中未清理 ThreadLocal 数据: 在一些长时间运行的应用中,比如 Web 应用,可能会创建很多 ThreadLocal 实例并存储大量数据。如果这些数据在使用完后没有及时清理,就会导致内存泄漏问题。
- 没有使用
remove()方法清理 ThreadLocal 数据: 在使用完 ThreadLocal 存储的数据后,如果没有调用remove()方法清理数据,就会导致数据长时间存在于 ThreadLocal 中,从而可能引发内存泄漏。
实线代表强引用,虚线代表弱引用
每一个Thread维护一个ThreadLocalMap, key为使用弱引用的ThreadLocal实例,value为线程变量的副本。
强引用,使用最普遍的引用,一个对象具有强引用,不会被垃圾回收器回收。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不回收这种对象。
如果想取消强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样可以使JVM在合适的时间就会回收该对象。
弱引用,JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用java.lang.ref.WeakReference类来表示。
2|02. 文章详情
2|12.1 接口说明
接口url:/articles/view/{id}
请求方式:POST
请求参数:
| 参数名称 | 参数类型 | 说明 |
|---|---|---|
| id | long | 文章id(路径参数) |
返回数据:
2|22.2 涉及到的表
2|32.3 Controller
2|42.4 Service
2|52.5 测试
3|03. 使用线程池 更新阅读次数
3|13.1 线程池配置
taskExecutor是一个线程池对象,在这段代码中通过@Bean("taskExecutor")注解定义并配置了一个线程池,并将其命名为 "taskExecutor"。asyncServiceExecutor()方法是一个Bean方法,用于创建并配置一个线程池,并以taskExecutor作为 Bean 的名称。ThreadPoolTaskExecutor是 Spring 框架提供的一个实现了Executor接口的线程池- 在方法中创建了一个
ThreadPoolTaskExecutor实例executor,并对其进行了一系列配置:
setCorePoolSize(5): 设置核心线程数为 5,即线程池在空闲时会保持 5 个核心线程。setMaxPoolSize(20): 设置最大线程数为 20,即线程池中允许的最大线程数量。setQueueCapacity(Integer.MAX_VALUE): 配置队列大小为整数的最大值,即任务队列的最大容量。setKeepAliveSeconds(60): 设置线程活跃时间为 60 秒,即线程在空闲超过该时间后会被销毁。setThreadNamePrefix("CherriesOvO博客项目"): 设置线程名称的前缀为 "CherriesOvO博客项目"。setWaitForTasksToCompleteOnShutdown(true): 设置在关闭线程池时等待所有任务结束。initialize(): 执行线程池的初始化。- 最后,将配置好的线程池返回为一个
ExecutorBean,供其他组件使用。
3|23.1 使用
通过
@Async("taskExecutor")注解,该方法标记为异步执行,并指定了使用名为 "taskExecutor" 的线程池。
articleMapper.update(articleUpdate, updateWrapper)是一个 MyBatis-Plus 中的更新操作,用于更新数据库中的文章记录。
update方法接受两个参数:
articleUpdate:表示需要更新的文章对象,其中包含了新的阅读量。updateWrapper:表示更新条件,即确定哪些文章需要被更新的条件。这段代码通过
Thread.sleep(5000)方法在当前线程中休眠了5秒钟。这样做的目的是为了模拟一个耗时操作,以展示在异步线程中执行的任务不会影响到主线程的执行。
3|33.3 测试
睡眠 ThredService中的方法 5秒,不会影响主线程的使用,即文章详情会很快的显示出来,不受影响
__EOF__

本文链接:https://www.cnblogs.com/zyj3955/p/18127298.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2021-04-10 关于ECharts图表反复修改都无法显示的解决方案