学习笔记——Python基础
str = '我是一名学生' print(str[0]) #输出“我” print(str[-6]) #输出“我”

字符串切片:把数据对象的一部分拿出来
str = '我是一名学生' print(str[2:4]) #输出“一名” print(str[-4:-2]) #输出“一名”

#获取字符串长度:len() str = '我是一名学生' length = len(str) print(length)

函数
def interview(): #def是关键字 表示定义一个函数 print("把求职者带到3号会议室") print("请求职者 完成答卷") print("让测试经理来面试 求职者") print("让技术总监面试 求职者")
-
函数参数:
def interview(interviewee): #def是关键字 表示定义一个函数 print("下一位求职者是" + interviewee) print("把求职者带到3号会议室") print("请求职者 完成答卷") print("让测试经理来面试 求职者") print("让技术总监面试 求职者") interview('小明')
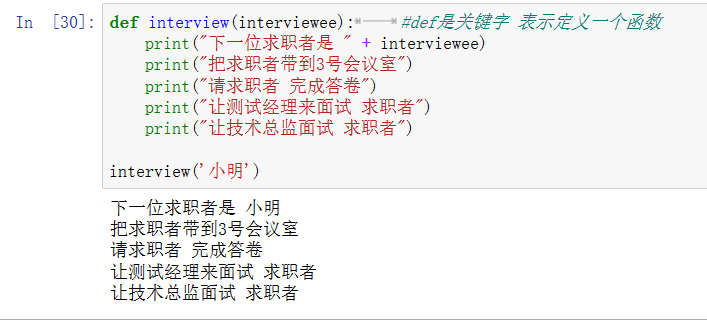
注:python中TAB和空格不能混用,否则会出错
列表:列表的内容可以改变
-
定义:
nameList = [] #空列表 a = [1, 2, 3.14, 'hello', [7,8,9] ] #非空列表
元组:元组的内容不可以改变
-
定义:
nameList = () #空元组 a = (1, 2, 3.14, 'hello') #非空元组
如果元组中只有一个元素,必须要在后面加上逗号。(a = (1, ))
定义元组还可以去掉圆括号,a = 1, 2, 3.14, 'hello'
-
判断元素是否在元组:
list1 = [1,2,3,4, 'hello'] tuple1 = (1,2,3,4, 'hello') if 'hello' in list1: print('hello 在列表中存在') if 'boy' not in tuple1: print('boy 在元组中不存在')
判断语句
def registerUser(): phone = input('请输入你的手机号码(不超过11个字符):') if len(phone) > 11: print('输入错误!手机号码超过了11个字符') # 还需要进一步判断 输入的是否全数字 elif not phone.isdigit() : print('输入错误!手机号码必须全是数字') # 判断是否以数字1 开头 elif not phone.startswith('1') : # startswith 是字符串对象的方法 print('输入错误!手机号码必须以数字1开头') else: print('手机号码输入正确') print('函数结束')
isdigit() 方法检测字符串是否只由数字组成,只对 0 和 正数有效。
startsWith() 方法用于检测字符串是否以指定的子字符串开始。
输入
def temperature(): tem = int(input("请输入今天的气温:")) ap = int(input("请输入今天的气压:")) if tem > 30 or tem < -8 or ap > 300 or tem < 20: print("不舒适") elif tem >25 and tem <= 30 and ap > 200 and ap <= 300: print("比较舒适") else: print("无法判断") temperature()
对象的方法
# var1 是一个列表对象 var1 = [1,2,3,4,5,6,7] # 列表对象都有 reverse方法,该方法将列表元素倒过来 var1.reverse() print(var1)

字符串的方法
-
count:
# 调用字符串的count 方法,count 方法可以返回字符串对象包含了多少个参数指定的字符串 # 表示该字符串包含了两个 '我们' '我们今天不去上学,我们去踢足球'.count('我们')
-
find:在字符串中查找参数子字符串,并返回该参数字符串在其中第一个出现的位置索引
str1 = '我们今天不去上学,我们去踢足球' # 返回 0 , str1字符串中有两个 '我们' # find返回的是第一个 '我们' 的索引 0 pos1 = str1.find('我们')
-
split、splitlines:split经常用来从字符串中截取出我们想要的信息。
#用 | 作为源字符串str1的分割符 str1 = '小张:79 | 小李:88 | 小赵:83' pos1 = str1.split('|') print(pos1)

#splitlines把字符串按换行符进行切割 salary = ''' 小王 10000元 小李 20000元 小徐 15000元 ''' print(salary.splitlines())

-
join:将列表中的字符串元素以某字符串为连接符,连接为一个字符串
'|'.join([ '小张:79 ', ' 小李:88 ', ' 小赵:83' ])

-
strip 、 lstrip 、 rstrip:
' 小 李:88 '.strip() #strip方法可以将 字符串前面和后面的空格删除,但是不会删除字符串中间的空格 ' 小 李:88 '.lstrip() #将字符串前面(左边)的空格删除,但是不会删除字符串中间和右边的空格 ' 小 李:88 '.rstrip() #将字符串后面(右边)的空格删除,但是不会删除字符串中间和左边的空格
-
replace:替换字符串里面所有指定的子字符串为另一个字符串
str1 = '我们今天不去上学,我们去踢足球' str1 = str1.replace('我们', '他们')
-
startswith 和 endswith
#startswith方法检查字符串是否以参数指定的字符串开头 #endswith方法检查字符串是否以指定的字符串结尾 str1 = '我们今天不去上学,我们去踢足球' str1.startswith('我们') # 返回 True str1.endswith('我们') # 返回 False def telephone(): tele = input("请输入手机号码:") if not tele.isdigit() or len(tele) != 11 or not tele.startswith('1'): print("手机号码输入格式错误") else: print("您的手机号码为:"+tele) telephone()
列表的方法
-
append:在列表后面添加一个元素
a = [1, 2, 3.14, 'hello'] # append 之后,a就变成了 [1, 2, 3.14, 'hello', '你好'] a.append('你好') print(a) # 继续append ,a就变成了 [1, 2, 3.14, 'hello', '你好', [7,8]] a.append([7,8]) print(a)

append 方法的返回值是None
-
insert:在指定位置插入一个元素
a = [1, 2, 3.14, 'python3.vip'] # 插入到索引0的位置,也是插到第1个元素的位置上 # a列表内容就变成了 ['你好', 1, 2, 3.14, 'python3.vip'] a.insert(0, '你好') print(a)

insert方法的返回值也是None
-
pop:从列表取出并删除一个元素
a = [1, 2, 3.14, 'python3.vip'] # 取出索引为3 的元素,也就是第4个元素 poped = a.pop(3) # 取出后,a列表对象内容就变成了 [ 1, 2, 3.14] print(a)

pop 方法的返回值是提取出来的元素
-
remove:删除列表元素,参数是要删除元素的值,最多只会删除1个元素
var1 = ['a','b','c','a'] var1.remove('a') print(var1)

-
reverse:将列表元素倒过来
var1 = [1,2,3,4,5,6,7] var1.reverse() print(var1)
-
index:返回参数对象在列表中的位置,也就是索引
var1 = [1,2,3,4,5,6,7] idx = var1.index(5) print(idx)
-
sort:对列表进行排序
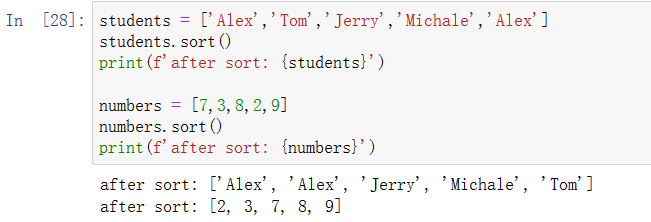
students = ['Alex','Tom','Jerry','Michale','Alex'] students.sort() print(f'after sort: {students}') numbers = [7,3,8,2,9] numbers.sort() print(f'after sort: {numbers}')
字符串格式化
-
printf风格:
salary = input('请输入薪资:') # 计算出缴税额,存入变量tax tax = int(salary) *25/100 # 计算出税后工资,存入变量aftertax aftertax = int(salary) *75/100 print('税前薪资:%s元,缴税:%s元,税后薪资:%s元' %(salary,tax,aftertax))
-
f-string风格:
salary = input('请输入薪资:') # 计算出缴税额,存入变量tax tax = int(salary) *25/100 # 计算出税后工资,存入变量aftertax aftertax = int(salary) *75/100 print(f'税前薪资是:{salary}元, 缴税:{tax}元, 税后薪资是:{aftertax}元')
指定宽度:为了输出对齐,我们需要指定填入的字符串的宽度,方法是,在括号里面的变量后面加上——:宽度值
例如:salary = 10000 print(f'{salary:10}')
-
小练习:

def demo(): name = input("请输入你的名字:") age = int(input("请输入你的年龄:")) print(f'你的名字是:{name},你的年龄是:{age}') demo()
循环
-
while循环:
command = input("请输入命令:") while command != 'exit': print(f'输入的命令是{command}') command = input("请输入命令")
-
for循环:
studentAges = ['小王:17', '小赵:16', '小李:17', '小孙:16', '小徐:18'] for student in studentAges: print(student)
循环n次:使用for 循环 和 一个内置类型 range:
# range里面的参数100 指定循环100次 # 其中 n 依次为 0,1,2,3,4... 直到 99 # range里面可以放入两个参数。两个参数表示起止范围。 # range里面可以放入3个参数,第3个参数表示步长 for n in range(100): print(n) print('python,你好')
-
break和return的区别:
-
return 只能用在函数里面, 表示 从函数中返回。
-
break只是跳出循环, 如果循环后面还有代码,会进行执行。
-
return 会从函数里面立即返回, 函数体内的后续任何代码都不执行了。
-
-
break和continue的区别:
-
continue只是当前这次循环结束,就是这次循环 continue 后面的代码不执行了, 后续的循环还要继续进行。
-
break是结束整个循环
-
-
列表推导式:把一个列表里面的每个元素, 经过相同的处理,生成另一个列表。
#一个列表1,里面都是数字,我们需要生成一个新的列表2,依次存放列表1中每个元素的平方 list1 = [1,2,3,4,5,6] list2 = [num**2 for num in list1] print(list2)
-
嵌套循环:
list1 = ['关羽','张飞','赵云','马超','黄忠'] list2 = ['典韦','许褚','张辽','夏侯惇','夏侯渊'] for member1 in list1: for member2 in list2: print(f'{member1} 大战 {member2}')
文件操作
-
写文件:
f = open('test_1.txt','w',encoding='utf8') f.write('Python文件操作') f.close()
-
读文件:
f = open('test_1.txt','r',encoding='utf8') content = f.read() f.close() print(content)
read()有参数,代表读取文件中的几个字符,默认为全部读取。
读取文本文件内容的时候,通常还会使用readlines方法,该方法会返回一个列表。 列表中的每个元素依次对应文本文件中每行内容。
f = open('tmp.txt') linelist = f.readlines() f.close() for line in linelist: print(line)
字典
-
定义:字典对象定义用花括号 {} , 字典里面的 每个元素之间用 逗号隔开。
每个元素都是一个键值对,键和值之间用冒号隔开。
#键必须是可进行哈希值计算的对象,通常是数字或者字符串 #值可以是任何类型的对象 #字典对象的键是唯一的,不可能有两个元素具有相同的键 members = { 'account1' : 13 , 'account2' : 12 } members = { 'account1' : {'account':'account1', 'level': 13, 'point':3000} , 'account2' : {'account':'account2', 'level': 12, 'point':36000} }
-
获取键的值:
members['account1'] #获取account1的值
-
添加:
members = {} #定义空字典 members['accoutn1'] = 13 #添加account1 members['account2'] = 14 #继续添加account2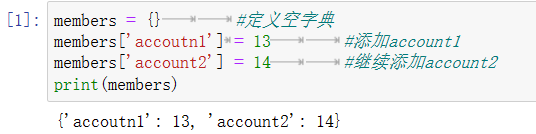
-
修改:
members = { 'account1' : 13, 'account2' : 14 } mambers['account2'] = 15 #修改account2

-
删除:
-
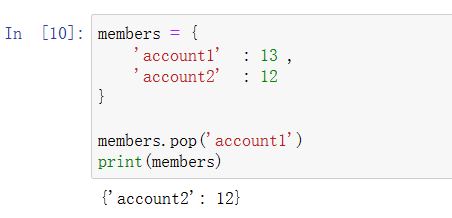
pop方法删除:
members = { 'account1' : 13 , 'account2' : 12 } val = members.pop('account1') #删除account1 print(members)
-
del关键字删除:
members = { 'account1' : 13 , 'account2' : 12 } del members['account1'] print(members)
-
-
判断键值是否存在:
members = { 'account1' : 13 , 'account2' : 12 } if 'account1' in members: print('account1 在字典中存在') if 'account88' not in members: print('account88 不在字典中')
-
遍历字典:
#items方法,返回的是一个类似列表一样的对象,其中每个元素就是键值组成的元组 #item返回的值:[('account1', 13), ('account2', 12), ('account3', 15)] members = { 'account1' : 13 , 'account2' : 12 , 'account3' : 15 , } for account,level in members.items(): print (f'account:{account}, level:{level}')
-
清空字典:
members.clear()
-
字典合并:
members = { 'account1' : 13 , 'account2' : 12 , 'account3' : 15 , } another = { 'account4' : 13 , 'account5' : 12 , } members.update(another) print(members)
-
获取字典元素个数:
len(members)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号