Spark在Local环境下的使用
① 将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux (cd /opt/module路径下)并解压缩
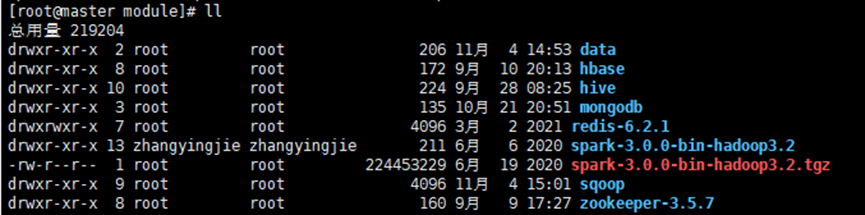
② 修改spark-3.0.0-bin-hadoop3.2名称为spark-local
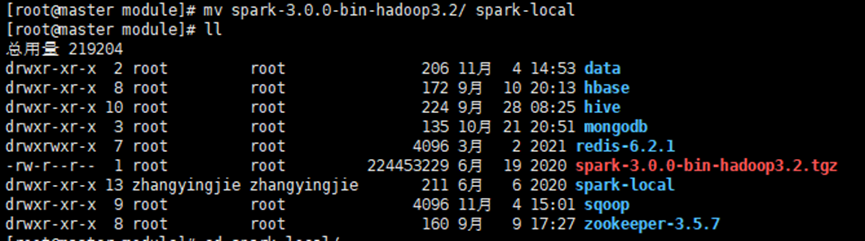
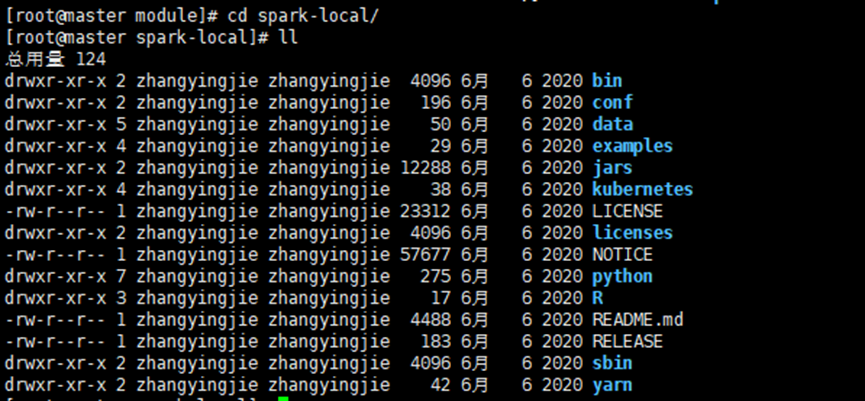
③ 进入spark-local
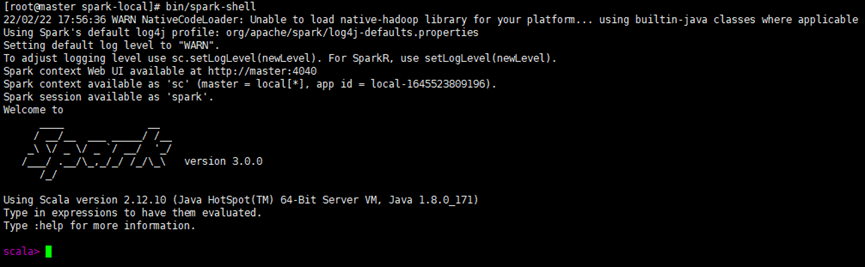
④ 启动local环境
⑤ Web页面访问:master:4040
⑥ 命令行的使用

⑦ 提交应用(cd /opt/module/spark-local路径下)
1) --class 表示要执行程序的主类,可以更换为自己写的应用程序
2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,可以设定为自己打的 jar 包
4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量

⑧ 退出本地模式
__EOF__

本文作者:CherriesOvO
本文链接:https://www.cnblogs.com/zyj3955/p/15924407.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/zyj3955/p/15924407.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!