
18-24章
-
Redis 的发布与订阅功能由
PUBLISH、SUBSCRIBE、PSUBSCRIBE等命令组成 -
频道的订阅与退订
-
Redis将所有频道的订阅关系都保存在服务器状态的pubsub_channels字典里面,这个字典的键是某个被订阅的频道,而键的值则是一个链表,链表里面记录了所有订阅这个频道的客户端
-
UNSUBSCRIBE命令的行为和SUBSCRIBE命令的行为正好相反,当一个客户端退订某个或某些频道的时候,服务器将从pubsub_channels中解除客户端与被退订频道之间的关联
-
-
-
服务器也将所有模式的订阅关系都保存在服务器状态的pubsub_patterns中。pubsub_patterns属性是一个链表,链表中的每个节点都包含着一个pubsubPattern结构,这个结构的pattern属性记录了被订阅的模式,而client属性则记录了订阅模式的客户端
-
订阅模式就会创建一个pubsubPattern,插入到链表的结尾。退订就会删除链表的最后一个节点
-
-
将消息发送给频道订阅者
-
遍历链表,把消息发送给链表上的所有订阅者
-
-
将消息发送给模式订阅者
-
遍历整个pubsub_patterns链表,查找那些与channel频道相匹配的模式,并将消息发送给订阅了这些模式的客户端。
-
-
查看订阅信息
-
pubsub channels:返回服务器当前被订阅的频道。底层是遍历pubsub_channels所有的键 -
pubsub numsub [ channel1 channel2 ..]:返回频道的订阅者数量,底层是返回键所对应的链表长度 -
pubsub numpat:返回服务器当前被订阅模式的数量
-
19、事务
-
事务的实现
-
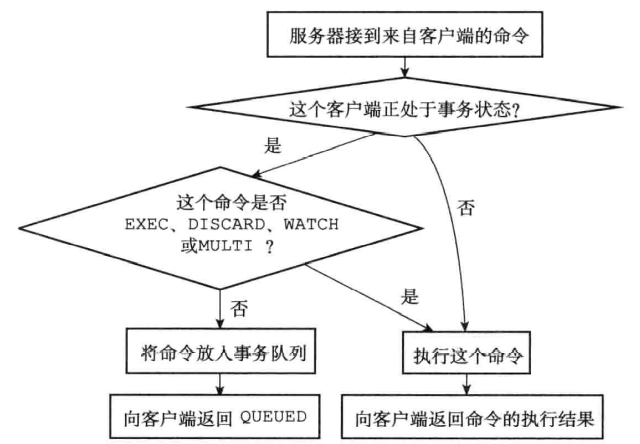
事务开始:MULTI命令可以将执行该命令的客户端从非事务状态切换至事务状态,这一切换是通过在客户端状态的flags属性中打开REDIS_MULTI标识来完成的
-
命令入队:
-
![]()
-
每个Redis客户端都有自己的事务状态,这个事务状态保存在客户端状态的mstate属性。事务状态包含一个事务队列,以及一个已入队命令的计数器。事务队列是一个multicmd类型的数组,数组中的每个multicmd结构都保存了一个已入队命令的相关信息,包括指向命令实现函数的指针、命令的参数,以及参数的数量,事务队列以FIFO的方式保存入队的指令
-
-
事务执行:当一个处于事务状态的客户端向服务器发送EXEC命令时,这个EXEC命令将立即被服务器执行。服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。
-
-
WATCH命令的实现
-
WATCH命令是一个乐观锁( optimistic locking ),它可以在EXEC命令执行之前,监视任意数量的数据库键,并在EXEC命令执行时,检查被监视的键是否至少有一个已经被修改过了,如果是的话,服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复。
-
每个Redis数据库都保存着一个watched_keys字典,这个字典的键是某个被WATCH命令监视的数据库键,而字典的值则是一个链表,链表中记录了所有监视相应数据库键的客户端。
-
通过一个函数触发监视机制,会将监视被修改键的客户端的REDIS DIRTY CAS标识打开,表示该客户端的安全性事务被破坏
-
-
事务的ACID性质
-
原子性:Redis的事务和传统的关系型数据库事务的最大区别在于,Redis不支持事务回滚机制( rollback ),即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止。
-
一致性:Redis通过谨慎的错误检测和简单的设计来保证事务的一致性
-
入队错误:命令不存在或者格式不正确
-
执行错误:比如设置了一个字符串键,但是入队的指令是列表键等
-
服务器停机:无论Redis服务器运行在哪种持久化模式下,事务执行中途发生的停机都不会影响数据库的一致性。
-
-
隔离性:多个事务并发执行,事务与事务之间不影响
-
持久性:当一个事务执行完毕时,执行这个事务所得的结果已经被保存到永久性存储介质(比如硬盘)里面了,即使服务器在事务执行完毕之后停机,执行事务所得的结果也不会丢失。根据持久化模式决定
-
20、LUA脚本
-
创建并修改LUA环境
-
创建LUA环境:服务器首先调用Lua的CAPI函数lua_open,创建一个新的 Lua环境
-
载入函数库:基础库、表格库、字符串、数学库、调试库、lua CJSON库、struct库、lua cmsgpack库
-
创建redis全局表格:把这个表格设置为全局变量,表格中包含以下函数:
redis.call、redis.pcall..... -
使用Redis自制的随机函数来替换Lua原有的随机函数:为了保证相同的脚本可以在不同的机器上产生相同的结果,Redis要求所有传人服务器的Lua脚本,以及Lua环境中的所有函数,都必须是无副作用( side effect)的纯函数(purefunction )。但是数学库中的random函数有副作用
-
创建排序辅助函数:对于Lua脚本来说,另一个可能产生不一致数据的地方是那些带有不确定性质的命令。比如对于一个集合键来说,因为集合元素的排列是无序的,所以即使两个集合的元素完全相同,它们的输出结果也可能并不相同。为了消除命令的不确定性,会创建排序辅助函数
-
创建redis.pcall函数的错误报告辅助函数
-
保护LUA的全局变量:在这一步,服务器将对Lua环境中的全局环境进行保护,确保传入服务器的脚本不会因为忘记使用local关键字而将额外的全局变量添加到Lua环境里面。
-
将Lua环境保存到服务器状态的lua属性里面
-
-
LUA环境协作组件
-
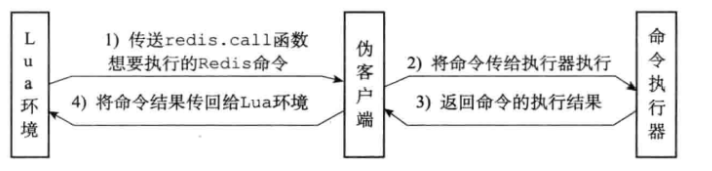
伪客户端:因为执行Redis命令必须有相应的客户端状态,所以为了执行Lua脚本中包含的Redis命令,Redis服务器专门为Lua环境创建了一个伪客户端,并由这个伪客户端负责处理Lua脚本中包含的所有Redis命令。
-
![]()
-
lua_scripts字典:这个字典的键为某个Lua脚本的SHA1校验和( checksum ),而字典的值则是SHA1校验和对应的lua脚本。有以下两个功能:
-
实现SCRIPT EXISTS命令
-
另一个是实现脚本复制功能
-
-
-
EVAL命令的实现
-
定义脚本函数:当客户端向服务器发送EVAL命令,要求执行某个Lua脚本的时候,服务器首先要做的就是在Lua环境中,为传入的脚本定义一个与这个脚本相对应的Lua函数,其中,Lua函数的名字由f_前缀加上脚本的SHA1校验和(四十个字符长)组成,而函数的体( body )则是脚本本身。
-
将脚本保存到lua_scripts字典中:
-
执行脚本函数:
-
-
EVALSHA命令的实现
-
只要脚本对应的函数曾经在Lua环境里面定义过,那么即使不知道脚本的内容本身,客户端也可以根据脚本的SHA1校验和来调用脚本对应的函数,从而达到执行脚本的目的,这就是EVALSHA命令的实现原理。
-
-
脚本管理命令的实现
-
script flush:用于清除服务器中所有和Lua脚本有关的信息,这个命令会释放并重建lua_scripts字典,关闭现有的Lua环境并重新创建一个新的Lua环境。 -
SCRIPT EXISTS:命令根据输入的SHA1校验和,检查校验和对应的脚本是否存在于服务器中。 -
SCRIPT LOAD:命令所做的事情和EVAL命令执行脚本时所做的前两步完全一样:命令首先在Lua环境中为脚本创建相对应的函数,然后再将脚本保存到lua_scripts字典里面。 -
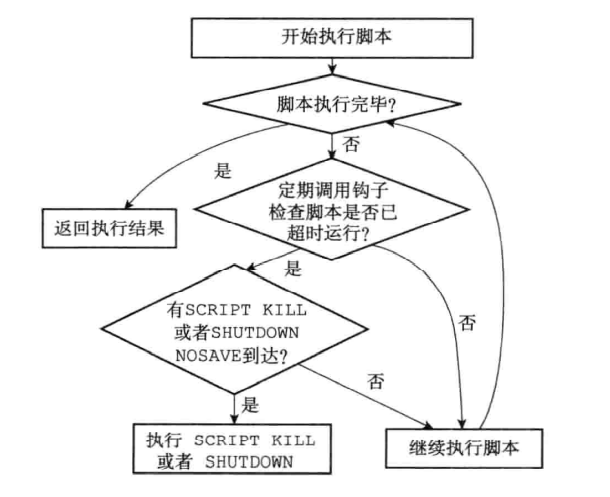
script kill: -
![]()
-
-
脚本复制
-
Redis复制EVAL、SCRIPT FLUSH、SCRIPT LOAD三个命令的方法和复制其他普通Redis命令的方法一样,当主服务器执行完以上三个命令的其中一个时,主服务器会直接将被执行的命令传播( propagate)给所有从服务器
-
对于一个在主服务器被成功执行的EVALSHA命令来说,相同的EVALSHA命令在从服务器执行时却可能会出现脚本未找到( not found)错误。
-
为了防止以上假设的情况出现,Redis要求主服务器在传播EVALSHA命令的时候,必须确保EVALSHA命令要执行的脚本已经被所有从服务器载入过,如果不能确保这一点的话,主服务器会将EVALSHA命令转换成一个等价的EVAL命令,然后通过传播EVAL命令来代替EVALSHA命令。
-
-
21、排序
-
sort< key >实现原理
-
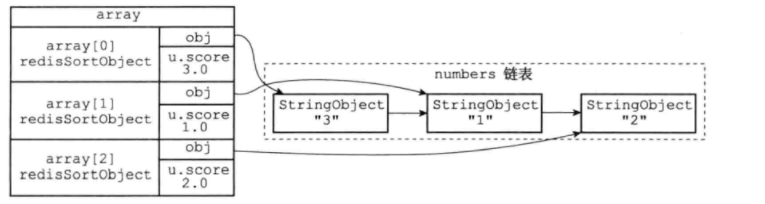
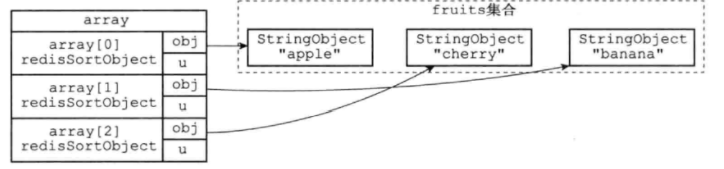
SORT命令为每个被排序的键都创建一个与键长度相同的数组,数组的每个项都是一个redissort0bject结构,根据数组项中的u.scores进行排序
-
![]()
-
-
alpha选项的实现
-
通过使用ALPHA选项,SORT命令可以对包含字符串值的键进行排序:
sort key alpha -
![]()
-
-
asc和desc命令的实现
-
都使用了快排
-
-
by选项的实现
-
通过使用BY选项,SORT命令可以指定某些字符串键,或者某个哈希键所包含的某些域( field)来作为元素的权重,对一个键进行排序。redis> SORT fruits BY *-price1
-
也是根据u.scores排序
-
-
limit实现
-
通过LIMIT选项,我们可以让SORT命令只返回其中一部分已排序的元素
-
-
get的实现
-
SORT命令在对键进行排序之后,总是返回被排序键本身所包含的元素。但是,通过使用GET选项,我们可以让SORT命令在对键进行排序之后,根据被排序的元素,以及GET选项所指定的模式,查找并返回某些键的值。
-
-
store的实现
-
默认情况下sort只向客户端返回排序的结果,他并不保存结果。但是,通过使用STORE 选项,我们可以将排序结果保存在指定的键里面,并在有需要时重用这个排序结果:
-
-
多个选项的执行顺序
-
排序:在这一步,命令会使用ALPHA 、ASC或DESC、BY这几个选项,对输入键进行排序,并得到一个排序结果集。
-
限制排序结果集的长度:在这一步,命令会使用LIMIT选项,对排序结果集的长度进行限制,只有LIMIT选项指定的那部分元素会被保留在排序结果集中。
-
获取外部键:在这一步,命令会使用GET选项,根据排序结果集中的元素,以及GET选项指定的模式,查找并获取指定键的值,并用这些值来作为新的排序结果集。
-
保存排序结果集:在这一步,命令会使用STORE 选项,将排序结果集保存到指定的键上面去。
-
向客户端返回排序结果集:在最后这一步,命令遍历排序结果集,并依次向客户端返回排序结果集中的元素。
-
22、二进制位数组
-
位数组的表示
-
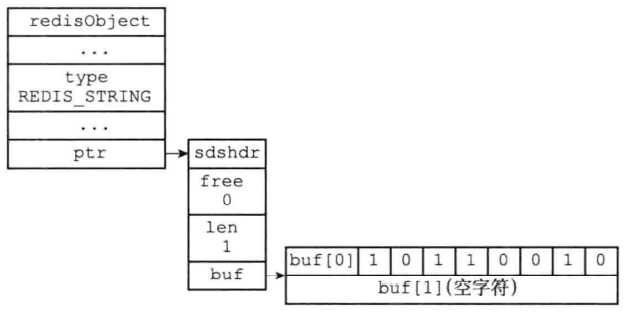
使用字符串对象来保存位数组,SDS。需要注意的是,buf数组保存位数组的顺序和我们平时书写位数组的顺序是完全相反的,因为可以简化SETBIT的实现
-
![]()
-
-
bitcount命令的实现
-
遍历算法
-
查表算法:创建一个表,表的键为数组的位置,值为单个数组中1的个数
-
variable-precision SWAR算法
-
redis的实现:如果未处理的二进制位的数量大于等于128位,那么程序使用variable-precisionSWAR算法来计算二进制位的汉明重量。如果未处理的二进制位的数量小于128位,那么程序使用查表算法来计算二进制位的汉明重量。
-
-
bitop命令的实现
23、慢查询日志
-
Redis 的慢查询日志功能用于记录执行时间超过给定时长的命令请求,用户可以通过这个功能产生的日志来监视和优化查询速度。
-
Redis的慢查询日志功能用于记录执行时间超过指定时长的命令。
-
Redis服务器将所有的慢查询日志保存在服务器状态的slowlog链表中,每个链表节点都包含一个slowlogEntry结构,每个slowlogEntry结构代表一条慢查询日志。
-
打印和删除慢查询日志可以通过遍历slowlog链表来完成。slowlog链表的长度就是服务器所保存慢查询日志的数量。
-
新的慢查询日志会被添加到slowlog链表的表头,如果日志的数量超过slowlog-max-len选项的值,那么多出来的日志会被删除。
24、监视器
-
客户端可以通过执行MONITOR命令,将客户端转换成监视器,接收并打印服务器处理的每个命令请求的相关信息。
-
当一个客户端从普通客户端变为监视器时,该客户端的REDIS_MONITOR标识会被打开。
-
服务器将所有监视器都记录在monitors链表中。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号