
计算机编码方式简介
1.计算机开始阶段
一开始运行在美国,美国的科学家为了能够让计算机认识人类语言。就开始编写编码方式。他们常将用的英文字母、标点符号、以及空格和制表符等所有的字符排列在一起,然后用二进制表示,就出现了一开始的ASCII编码,占有8字节,第一位为0。ASCII第一次以规范标准的类型发表是在1967年。
ASCII编码段介绍:
* 0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符)
* 32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。1.
* 65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
2.计算机发展阶段
后来随着计算机的发展,其他国家也开始使用计算机。都开始效仿美国开始了自己的编码,一开始美国占用了0000 0000 –0111 1111共有127位。其他国家就是要剩下了128位
后来计算机之间开始通信,发现将美国电脑上的东西拷贝到其他国家电脑上会出现乱码。因为每个国家的编码都是相互独立的,所以就会导致计算机不能进行编码出现乱码。
在这个阶段出现的编码方式有 1.在1981年IBM PC ROM256个字符的字符集,即IBM扩展字符集, 2. 1985年11Windows字符集被称作“ANSI字符集”,遵循了ANSI草案和ISO标准(ANSI/ISO8859-1-1987,简“Latin 1”
3.之后就开始了编码三阶段
Unicode编码
unicode编码系统分为两个分部:一部分是编码方式,一部分是实现方式
为了形成全世界性规范,伟大的人类在ASCII基础之上制定了unicode字符集,包含了所有国家的字母和字符,同时扩展到4bity,也就是32位
同时32位会存在一些问题,英文字母也需要32位,这样就会面临浪费很多内存空间的问题。为了解决这个问题,人类就提出来unicode编码不同的实现方式。
目前主流的集中实现方式,utf-8,utf-16,Utf-32
此部分主要讲解Utf-8实现方式。
首先看一下utf-8的编码:
Unicode 十六进制码点范围 UTF-8 二进制
0000 0000 - 0000 007F 0xxxxxxx
0000 0080 - 0000 07FF 110xxxxx 10xxxxxx
0000 0800 - 0000 FFFF 1110xxxx 10xxxxxx 10xxxxxx
0001 0000 - 0010 FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
上图是unicode编码对应的utf8编码格式,
当字符对应的unicode编码位于0x0000 0000 到 0x0000 007F
对应的UTF-8 二进制就是将十六进制转成2进制就行了
其实这是就是指ASCII编码。
当字符对应的unicode编码位于 0x0000 0080 到 0x0000 07FF
这一段范围是指一下拉丁字母,和一些彝文字母
当字符对应的unicode编码位于0x0000 0800 到 0x0000 FFFF
这一段主要就是用来表示汉字,所以就会有在utf-8中汉字占三个字节。
当字符对应的unicode编码位于 0x0001 0000 到 0x0010 FFFF
找了好久也没有具体的发现。
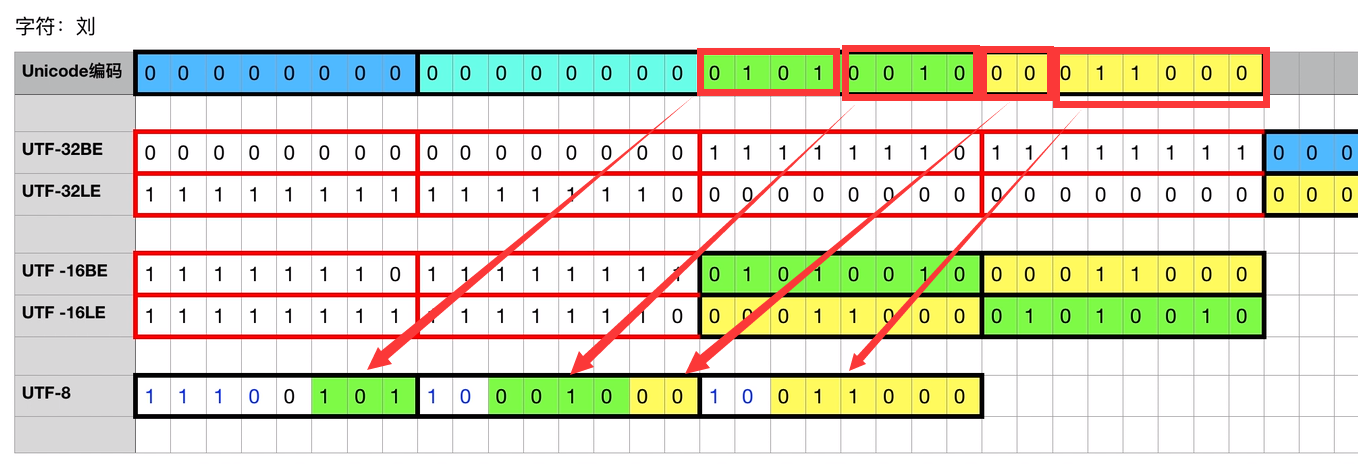
接下来以刘为例子讲解一下unicode编码utf-8实现方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号