php页面编码与字符操作
1 <meta http-equiv="content-type" content="text/html; charset=编码类型">
1 header("content-type:text/html; charset=编码类型");
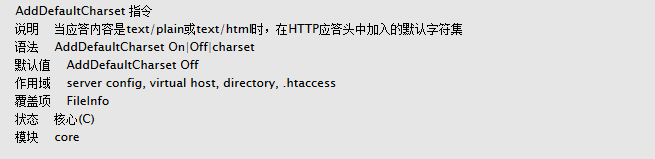
1:如果页面没有指定编码 , Apache配置defaultcharset gbk , 页面文件编码是utf-8。
页面显示是乱码。在页面没有meta指明charset,设置defaultcharset gbk,这个时候服务器的设置生效,编码不一致,造成乱码;
2:如果页面指定编码为utf-8, Apache配置defaultcharset gbk. 页面文件编码是utf-8。
页面显示乱码。设置defaultcharset gbk,会覆盖页面级别(meta)的编码设置;
3:如果页面header申明charset为utf8, Apache配置defaultcharst gbk,页面文件编码是utf8。
页面显示正常。这个说明header优先级要高于服务器和浏览器的设置;
4:如果Apache关闭DefaultCharset 。
页面显示正常。
1 $string = "赵亚飞"; 2 $encode = mb_detect_encoding($string, array("ASCII","UTF-8","GB2312","GBK","BIG5")); 3 header("content-Type: text/html; charset=".$encode); 4 echo $string;
有时会出现检查错误(解决办法)例如:对与GB2312和UTF- 8,或者UTF-8和GBK网上说是由于字符短是,mb_detect_encoding会出现误判。 不是bug,写程序时也不应当过于依赖mb_detect_encoding,当字符串较短时,检测结果产生偏差的可能性很大。
对编码检测的顺序进行调整,将最大可能性放在前面,这样减少被错误转换的机会。 一般要先排gb2312,当有GBK和UTF-8时,需要将常用的排列到前面。
例如:
1 1: 将任意类型( 'ASCII,GB2312,GBK,UTF-8')字符串$html_str转换成'UTF-8'编码 2 $html_str = mb_convert_encoding($html_str, 'UTF-8', 'ASCII,GB2312,GBK,UTF-8'); 3 2:gbk To utf-8 4 < ?php 5 header("content-Type: text/html; charset=Utf-8"); 6 echo mb_convert_encoding("赵亚飞", "UTF-8", "GBK"); 7 ?>
注意:使用上面的函数需要安装但是需要先enable mbstring 扩展库。 在 php.ini里将; extension=php_mbstring.dll 前面的 ; 去掉
1 iconv("UTF-8","GB2312//IGNORE",$data)
1 function check_encod($encod,$string){ 2 //判断字符编码 3 $encode = mb_detect_encoding($string, array("ASCII","UTF-8","GB2312","GBK","BIG5")); 4 var_dump($encode); 5 if($encode != $encod){ 6 $string = iconv($encode, $encod, $string); 7 } 8 return $string; 9 } 10 $path = "赵亚飞。.jpg"; 11 $path = check_encod("GB2312",$path);
1 echo mb_substr('赵亚飞赵亚飞er',0,9); //输出:赵亚飞 2 echo mb_substr('赵亚飞赵亚飞er',0,9,'utf-8'); //输出:赵亚飞赵亚飞er
第一个是以三个字节为一个中文,这就是utf-8编码的特点,下面加上utf-8字符集说明,是以一个字为单位来截取的
Substr是截取字符的函数,但是很多时候,截取中文却需要额外处理,原因是中文在UTF-8中占用3个字节,在GB2312中占用2个字节,在截取中随时存在截取的字符串长度与组成未知,所以给很多人造成了困扰。PHP5开始,iconv_substr函数出现
1 <?php 2 $str='赵z亚y飞f/include'; 3 echo substr($str,1,5); 4 echo "<br>"; 5 echo iconv_substr($str,1,5,"UTF-8"); 6 ?>
这个是在网页编码为UTF-8的PHP代码中使用的截取编码。如果在UTF-8网页中使用GB2312或者GBK编码来截取,会出错,占用字节不同;反之,在GB2312或GBK网页中,不能使用UTF-8来进行截取 。由于iconv_substr是按照字符而非占用字节来计算,所以“a”和“叶”均计算为1位。在GB2312或者GBK中,由于占用字节是一样的,所以可以随意使用GB2312或GBK编码来截取,截取结果是一样的。
3:兼容性良好的截取字符串的函数
1 /** 2 * 截取字符串兼容各种编码 3 * 4 * @param string $str 5 * @param int $start //开始截取位置默认是0 6 * @param int $length //截取长度 7 * @param string $charset //字符编码 8 * @param int $is_addnode //是否加省略号 9 * @return string 10 **/ 11 public static function cut_string($str, $start=0, $length, $charset="", $is_addnode=true){ 12 if(empty($str) || $str == ''){ 13 return $str; 14 } 15 $real_set = mb_detect_encoding($str, array("UTF-8", "ASCII", "GB2312", "GBK", "BIG5")); 16 if(empty($charset)){ 17 //没有传编码就按本身编码; 18 $charset = $real_set; 19 if(empty($charset)){ 20 $charset = 'utf-8'; 21 } 22 }else{ 23 if($real_set != $charset){ 24 //如果编码不一致就设置为传入的编码,防止截取乱码 25 $str = iconv($real_set, $charset, $str); 26 } 27 } 28 29 //兼容没有安装扩展的情况 30 if(function_exists("mb_substr")){ 31 $cut_str = mb_substr($str, $start, $length, $charset); 32 }elseif(function_exists('iconv_substr')) { 33 $cut_str = iconv_substr($str, $start, $length, $charset); 34 } 35 if($is_addnode){ 36 if($str == $cut_str){ 37 return $cut_str; 38 }else{ 39 return $cut_str . "......"; 40 } 41 }else{ 42 return $cut_str; 43 } 44 //兼容正则截取 45 $preg['utf-8'] = "/[\x01-\x7f]|[\xc2-\xdf][\x80-\xbf]|[\xe0-\xef][\x80-\xbf]{2}|[\xf0-\xff][\x80-\xbf]{3}/"; 46 $preg['gb2312'] = "/[\x01-\x7f]|[\xb0-\xf7][\xa0-\xfe]/"; 47 $preg['gbk'] = "/[\x01-\x7f]|[\x81-\xfe][\x40-\xfe]/"; 48 $preg['big5'] = "/[\x01-\x7f]|[\x81-\xfe]([\x40-\x7e]|\xa1-\xfe])/"; 49 preg_match_all($preg[$charset], $str, $match); 50 $string = join("",array_slice($match[0], $start, $length)); 51 if($is_addnode){ 52 return $string . "......"; 53 } 54 return $string; 55 }

