Python学习笔记--XML的应用
XML的定义
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
Python 提供了多种模块来处理XML。
- xml.dom.* 模块:Document Object Model。适合用于处理 DOM API。它能够将 xml 数据在内存中解析成一个树,然后通过对树的操作来操作 xml。但是,这种方式由于将 xml 数据映射到内存中的树,导致比较慢,且消耗更多内存。
- xml.sax.* 模块:simple API for XML。由于 SAX 以流式读取 xml 文件,从而速度较快,切少占用内存,但是操作上稍复杂,需要用户实现回调函数。
- xml.parser.expat:是一个直接的,低级一点的基于 C 的 expat 的语法分析器。 expat 接口基于事件反馈,有点像 SAX 但又不太像,因为它的接口并不是完全规范于 expat 库的。
- xml.etree.ElementTree (以下简称 ET):元素树。它提供了轻量级的 Python 式的 API,相对于 DOM,ET 快了很多 ,而且有很多令人愉悦的 API 可以使用;相对SAX,ET 也有 ET.iterparse 提供了 “在空中” 的处理方式,没有必要加载整个文档到内存,节省内存。ET 的性能的平均值和 SAX 差不多,但是 API的效率更高一点而且使用起来很方便。
遍历查询
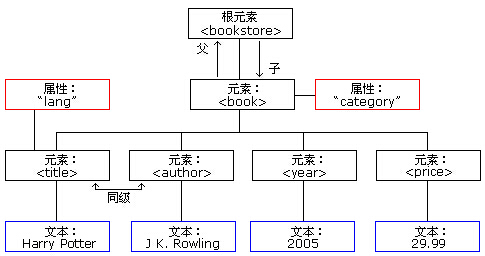
这是一个 xml 树,只不过是用图来表示的,还没有用 ET 解析呢。把这棵树写成 xml 文档格式:
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
建立起 xml 解析树。然后可以通过根节点向下开始读取各个元素(element 对象)。
>>> import xml.etree.cElementTree as ET >>> tree = ET.ElementTree(file="22601.xml") >>> tree <ElementTree object at 0x7f8fbd411050> >>> root = tree.getroot() >>> root.tag 'bookstore' >>> root.attrib {}
读取根下面的元素:
>>> for child in root: ... print child.tag,child.attrib ... book {'category': 'COOKING'} book {'category': 'CHILDREN'} book {'category': 'WEB'}
读取指定元素的信息:
>>> root[0].tag 'book' >>> root[0].attrib {'category': 'COOKING'} >>> root[0].text #无内容 '\n\t\t'
再读取下一个元素
>>> root[0][0].tag 'title' >>> root[0][0].attrib #第一元素 {'lang': 'en'} >>> root[0][0].text 'Everyday Italian' >>> root[0][1].tag #第二个元素 'author'
对于 ElementTree 对象,有一个 iter 方法可以对指定名称的子节点进行深度优先遍历。例如:
>>> for ele in tree.iter(tag="book"): #遍历book节点 ... print ele.tag,ele.attrib ... book {'category': 'COOKING'} book {'category': 'CHILDREN'} book {'category': 'WEB'} >>> for ele in tree.iter(tag="title"): #遍历title节点 ... print ele.tag,ele.attrib ... title {'lang': 'en'} title {'lang': 'en'} title {'lang': 'en'}
除了上面的方法,还可以通过路径,搜索到指定的元素,读取其内容。这就是 xpath。
>>> for ele in tree.iterfind("book/title"): ... print ele.text ... Everyday Italian Harry Potter Learning XML
利用 findall() 方法,也可以是实现查找功能:
>>> for ele in tree.findall("book"): ... title = ele.find('title').text ... price = ele.find('price').text ... print title,price ... Everyday Italian 37.0 Learning XML 46.95
编辑
删除
除了读取有关数据之外,还能对 xml 进行编辑,即增删改查功能。还是以上面的 xml 文档为例:
>>> root[1][0].text 'Harry Potter' >>> del root[1] >>> root[1][0].text #可以看见Harry Potter已经被删除了 'Learning XML'
但是这样的操作源文件是没有改变的,现在只是在内存中做了修改而已,如果要修改源文件我们得这样做:
>>> import os >>> outpath = os.getcwd() >>> file = outpath + "/22601.xml" >>> tree.write(file)
上面用del 来删除某个元素,其实,在编程中,这个用的不多,更喜欢用 remove() 方法。比如我要删除price> 40 的书。可以这么做:
>>> for book in root.findall("book"): ... price = book.find("price").text ... if float(price) > 40.0: ... root.remove(book) ... >>> tree.write(file)
修改
>>> for price in root.iter("price"): ... new_price = float(price.text) + 7 ... price.text = str(new_price) ... price.set("updated","up") ... >>> tree.write(file) >>> for price in root.iter("price"): ... print price.text ... 37.0 46.95
查看源文件
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price updated="up">37.0</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price updated="up">46.95</price>
</book>
</bookstore>
不仅价格修改了,而且在 price 标签里面增加了属性标记。
增加
>>> import xml.etree.cElementTree as ET >>> tree = ET.ElementTree(file="22601.xml") >>> root = tree.getroot() >>> for ele in root: ... print ele.tag ... book book >>> ET.SubElement(root, "book") #在 root 里面添加 book 节点 <Element 'book' at 0x7fc78fa06c90> >>> for ele in root: ... print ele.tag ... book book book >>> b2 = root[2] #得到新增的 book 节点 >>> b2.text = "Python" #添加内容 >>> tree.write("22601.xml")
总结:
元素常用属性:
- tag:string,元素数据种类
- text:string,元素的内容
- attrib:dictionary,元素的属性字典
- tail:string,元素的尾形
针对属性的操作
- clear():清空元素的后代、属性、text 和 tail 也设置为 None
- get(key, default=None):获取 key 对应的属性值,如该属性不存在则返回 default 值
- items():根据属性字典返回一个列表,列表元素为(key, value)
- keys():返回包含所有元素属性键的列表
- set(key, value):设置新的属性键与值
针对后代的操作
- append(subelement):添加直系子元素
- extend(subelements):增加一串元素对象作为子元素
- find(match):寻找第一个匹配子元素,匹配对象可以为 tag 或 path
- findall(match):寻找所有匹配子元素,匹配对象可以为 tag 或 path
- findtext(match):寻找第一个匹配子元素,返回其 text 值。匹配对象可以为 tag 或 path
- insert(index, element):在指定位置插入子元素
- iter(tag=None):生成遍历当前元素所有后代或者给定 tag 的后代的迭代器
- iterfind(match):根据 tag 或 path 查找所有的后代
- itertext():遍历所有后代并返回 text 值
- remove(subelement):删除子元素
ElementTree 对象
- find(match)
- findall(match)
- findtext(match, default=None)
- getroot():获取根节点.
- iter(tag=None)
- iterfind(match)
- parse(source, parser=None):装载 xml 对象,source 可以为文件名或文件类型对象.
- write(file, encoding="us-ascii", xml_declaration=None, default_namespace=None,method="xml")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号