李宏毅机器学习2022年学习笔记(五)-- transformer
一、 seq2seq
1. 含义
输入一个序列,机器输出另一个序列,输出序列长度由机器决定。
文本翻译:文本至文本; 语音识别:语音至文本; 语音合成:文本至语音; 聊天机器人:语音至语音。

2. 应用
① 自然语言处理(NLP问题),不过seq2seq有时候不一定是最佳的解决方法。
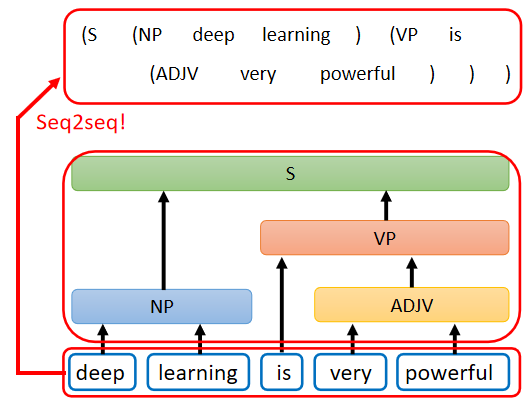
② 应用于Seq2seq for Syntactic Parsing句法分析(文法剖析),例如,给机器一段文字,Deep learning is very powerful,机器要做的事情是产生一个文法的剖析树 。
输出结果(剖析树)告诉我们,deep 加 learning 合起来是一个名词短语,very 加 powerful 合起来是一个形容词短语,形容词短语加 is 以后会变成一个动词短语,动词短语加名词片语合起来是一个句子
文法剖析要做的事情就是产生这样子的一个 Syntactic tree,所以在用 deep learning 解决 文法剖析的任务里面,输入是一段文字(一个Sequence),输出是一个树状的结构,(可以把他看作是一个Sequence,一个代表句法分析树的序列)
③ 应用于 multi-label classification(多标签分类问题:同一个对象可以属于多个class)
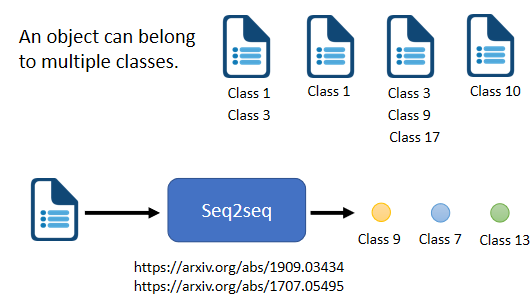
区分:
- multi-class classification:为样本从数个 class 中选择某一个 class(多对一)
- multi-label classification:同一个样本可以属于多个 class (一对多)
难点:每篇文章对应几个 class 不好确定 ⇒ seq2seq 决定要输出几个
④ Object Detection 物体检测
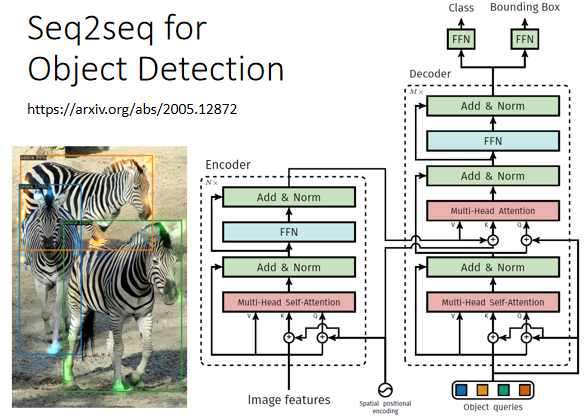
3. Seq2seq 实现方式
seq2seq's model = Encoder(编码器) + Decoder(解码器)
这两部分可以使用RNN或transformer实现,seq2seq主要是为了解决输入和输出长度不确定的情况。
Encoder:将输入(文字、语音、视频等)编码为单个向量,这个向量可以看成是全部输入的 抽象表示。
Decoder:接受 encoder 输出的向量,逐步解码,一次输出一个结果,每次输出会影响下一次的输出,开头加入 <BOS> 表示开始解码, <EOS> 表示输出结束。

① Encoder
用途:输入一排向量(序列),输出另外一排同样长度的向量(序列)
可以使用:Self-attention,RNN,CNN
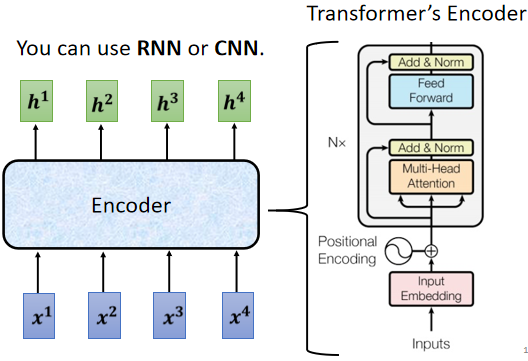
A、encoder 就是通过多层 block(模块),将输入转换成向量。每一个 block 都包含若干层( self-attention 和 fully connect 等网络结构 ),每个 block 输入一排向量,输出相同数量的一排向量。
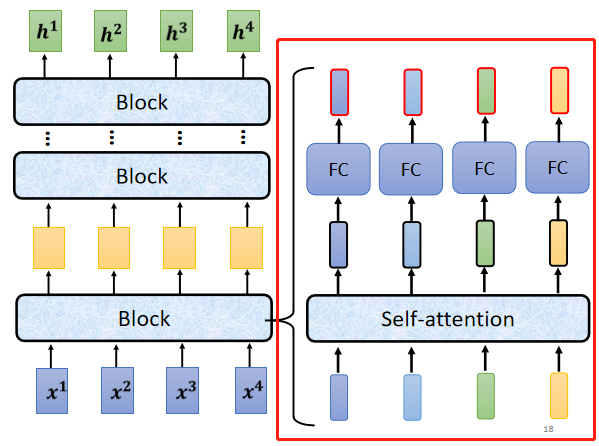
B、 block 的内部细节构成如下(在 input 送入 block 之前,需先进行 positional encoding,这个知识点在 self - attention 中有提过)。
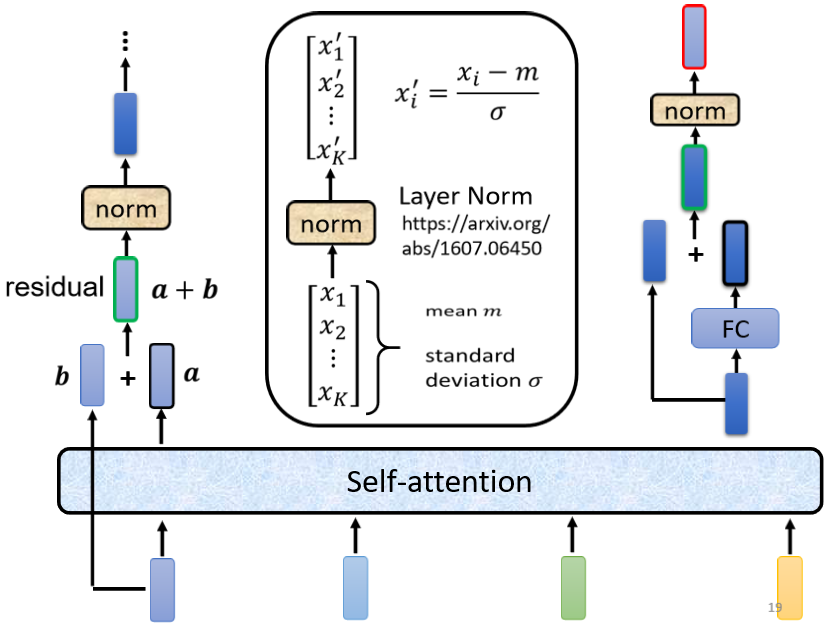
C 、 它考虑所有输入向量后的输出向量,其中 b 是原来的 input 向量,经过残差网络(residual connection:把 a vector 加上它的 b input vector 作为 output )和标准化后,送到全连接神经网络 FC ,由于在 FC network 中也有 residual 的架构,因此需要再经过一组 残差网络 + 标准化 后得到输出。(注意:这里的标准化是 layer normalization 而不是 batch normalization)。这个输出才是 residual network 里一个 block 的输出。
batch normalization:对 不同的 example 不同 feature 的 同一个 dimention 去计算平均值 mean 和标准差 standard deviation。
layer normalization:对 同一个 example 同一个 feature的 不同 dimention 去计算平均值 mean 和标准差 standard deviation。

② Decoder
decoder主要有两种:AT(autoregressive)与 NAT(non-autoregressive),Decoder 要做的事情:产生最终的输出结果
A、autoregressive(AT)decoder :以语音辨识为例
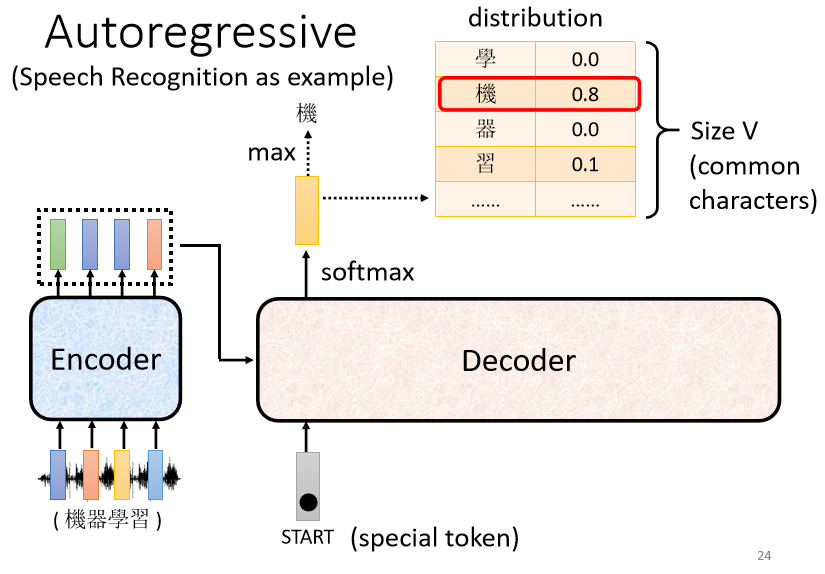
1. 向 Decoder 输入 Encoder 产生的向量
2. 在 Decoder 可能产生的文字库里多加一个标识字符 BEGIN ,它代表 “ Decoder 开始识别” 来提醒机器(BOS: begin of sentence)
NLP 的问题中,每一个 Token 用一个 One-Hot 的 Vector 来表示,其中正确的类别标识是 1,其他都是 0,其中 BEGIN 也是用 One-Hot Vector 来表示
3. 经过 softmax 之后,Decoder 会输出一个和 输入的 Vocabulary Size 一样的向量长度的 向量结果。对比已知文字库,找到相似度最高的字符就是最终输出的字符。(这里“机”字 就是这个 Decoder 的第一个输出)
Vocabulary Size:取决于你输出的单位。比如输出中文,则size是中文方块字的数目。
4. 再把上一步的输出当做下一个的输入。(在本例中,第二次 Decoder 把 “机” 当做是 Decoder 的 Input,在上一步 “机” 是 Decoder 的输出结果)经过一系列相同的操作后我们会得到第二次 Decoder 的输出,再作为第三次的输入,继续输出后续的文字,以此类推……
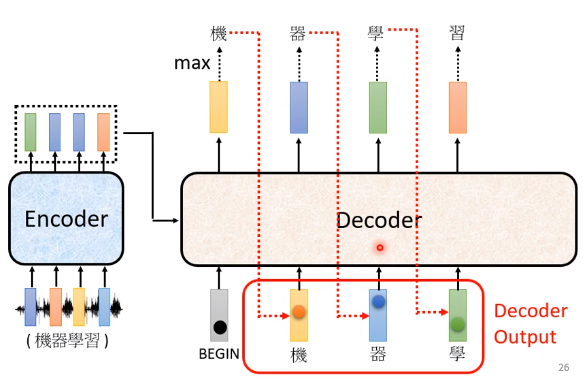
5. 机器自己决定输出的长度:一个特别的标识符 ”END” 代表工作结束
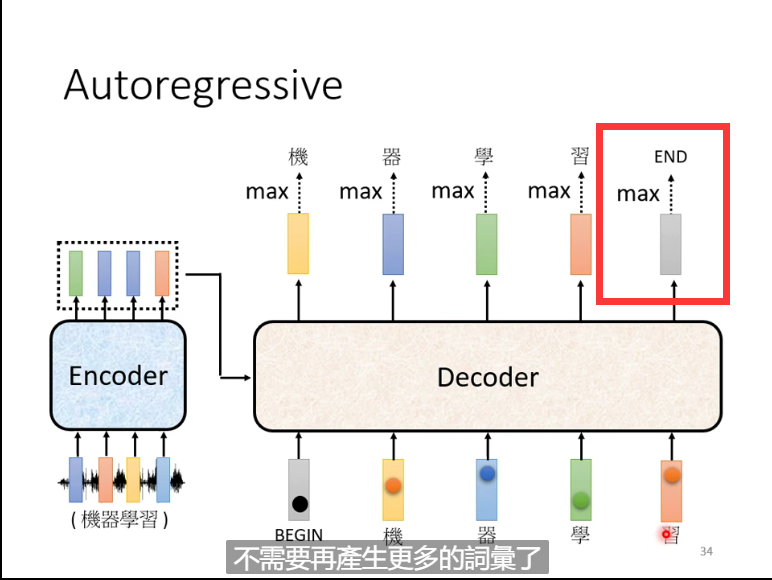
总结: 除了中间的部分,Encoder 跟 Decoder 并没有太大的差别。最后我们可以再做一个 Softmax,可以通过计算输出的概率分布与 Ground Truth 之间的 交叉熵(Cross Entropy)并求梯度实现优化,交叉熵的值越小越好。

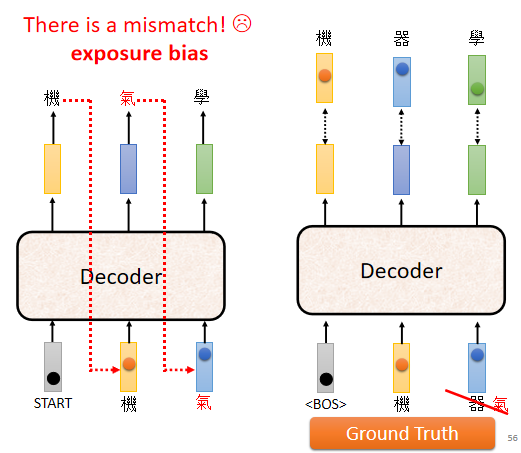
缺点:如果Decoder 看到错误的输入,让 Decoder 产生错误的输出并被代入到下一步 Decoder 工作的输入中,会会造成 Error Propagation(一步错,步步错)⇒ 解决:Teacher Forcing技术 (但是测试的时候 显然没有正确答案可以给 Decoder 看)
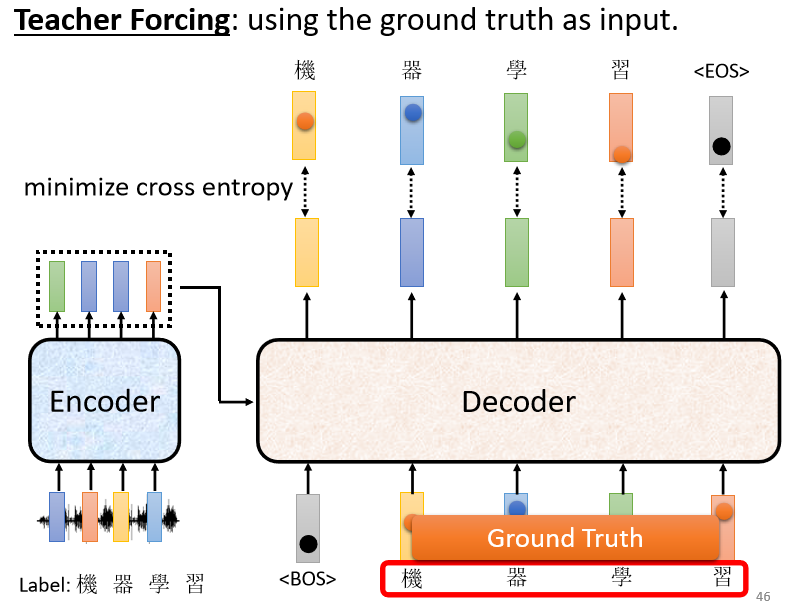
由于 Teacher Forcing的存在,训练跟测试的情景不一致。Decoder 在训练的时候永远只看过正确的东西,但是在测试的时候,仍然会导致一步错、步步错。
解决:给 Decoder 的输入加一些错误的东西 ⇒ Scheduled Sampling(但是也会一定程度损害平行化的能力)
B、Non-autoregressive (NAT) decoder
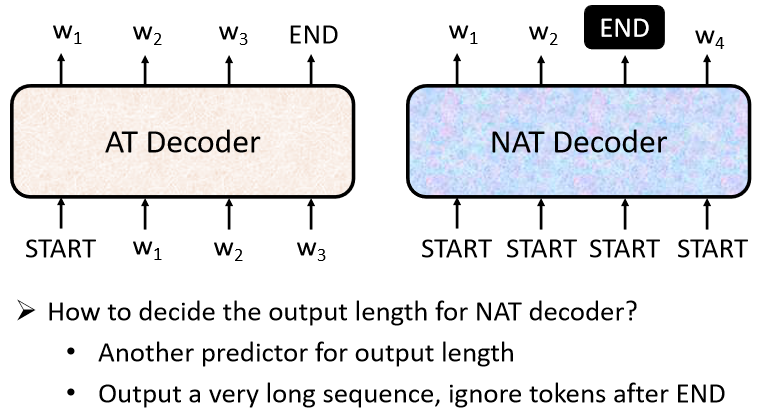
① 特点:NAT 不是依次有序进行 decoder 工作并挨个输出,而是一次性在输入时赋予 整个句子 一整排的 “ BEGIN ” 标识,把整个句子的 decoder 结果一次性都输出
② 思路:如何确定BEGIN的个数:
- 另外训练一个 Classifier,输入 Encoder 的 Input vector,输出是一个数字(代表 Decoder 应该要输出的长度)
- 给它若干个 BEGIN 的 Token,比如输出句子的最大长度不超过 300,就给 input 300 个 BEGIN token,然后就会相应地一次性输出 300 个字(遇到有输出 END 时表示这个句子输出结束),但是可能会比较耗费内存空间
③ 好处:
- 并行化。NAT 的 Decoder 不管 input 句子的长度大小,都是一次性输出完整的句子结果,所以在执行速度上 NAT 的 Decoder 比 AT 的 Decoder 要快
- 容易控制输出长度。
④ 应用:
常用在语音合成,例如:利用其中一个 决定 NAT 的 Decoder 应该输出的长度的 Classifier,我们可以通过设置这个输出长度的大小以调整语音的速度。(如果要让输出的语音讲快一点,就把 Classifier 输出的长度数值 除以 N,它讲话速度就变成 N 倍速;同理,如果想要合成的语音变为慢速,就把 Classifier 输出的长度数值乘 N 倍)
⑤ 缺点:虽然 NAT 看起来有很多优点(尤其是并行化),但是 NAT 的 Decoder 实际上 Performance 往往都不如 AT 的 Decoder。为什么NAT 没有 AT 实际效果好 ⇒ Multi-Modality 参考链接

 浙公网安备 33010602011771号
浙公网安备 33010602011771号