李宏毅机器学习2022年学习笔记(三)-- CNN
P.S. 本次将第三章 CNN 讲解有关内容和之前看的吴恩达深度学习 - 卷积神经网络专项课程的内容结合在一起进行总结
=====================================================
一、 概念导入:边缘检测
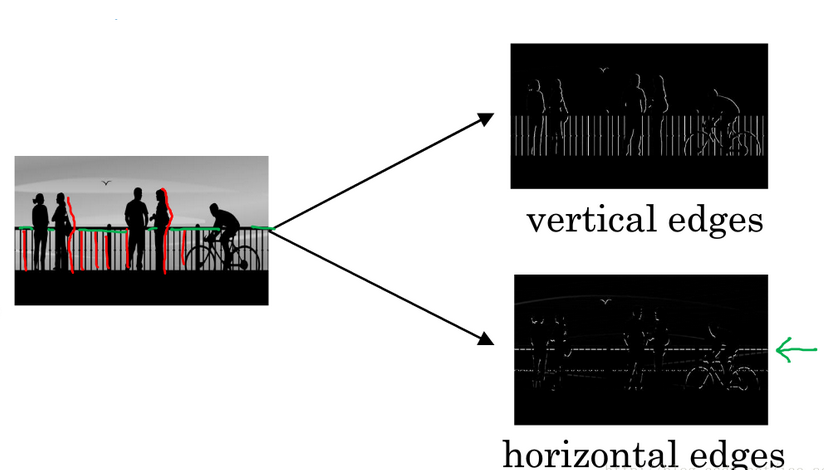
假如有一张如下的图像,想让计算机搞清楚图像上有什么物体,有两种方法:检测图像的 垂直边缘 和 水平边缘。
如下图所示,一个 6 * 6 的灰度图像,构造一个 3 * 3 的矩阵( 在CNN中通常称为 filter 过滤器),将 3 * 3 矩阵映射到该图像中,对这个 6 * 6 的灰度图像做 卷积运算,filter 跟图片对应位置的数值直接相乘,所有的都乘完以后再相加(内积),其中步长为1,以此类推,让过滤器在图像上逐步滑动,对整个图像进行卷积计算得到一幅 4 * 4 的图像。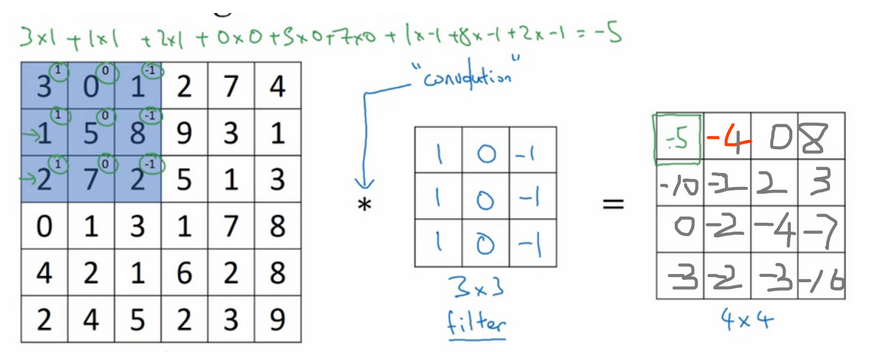
这种方法可以得到图像的边缘信息的主要解释如下:
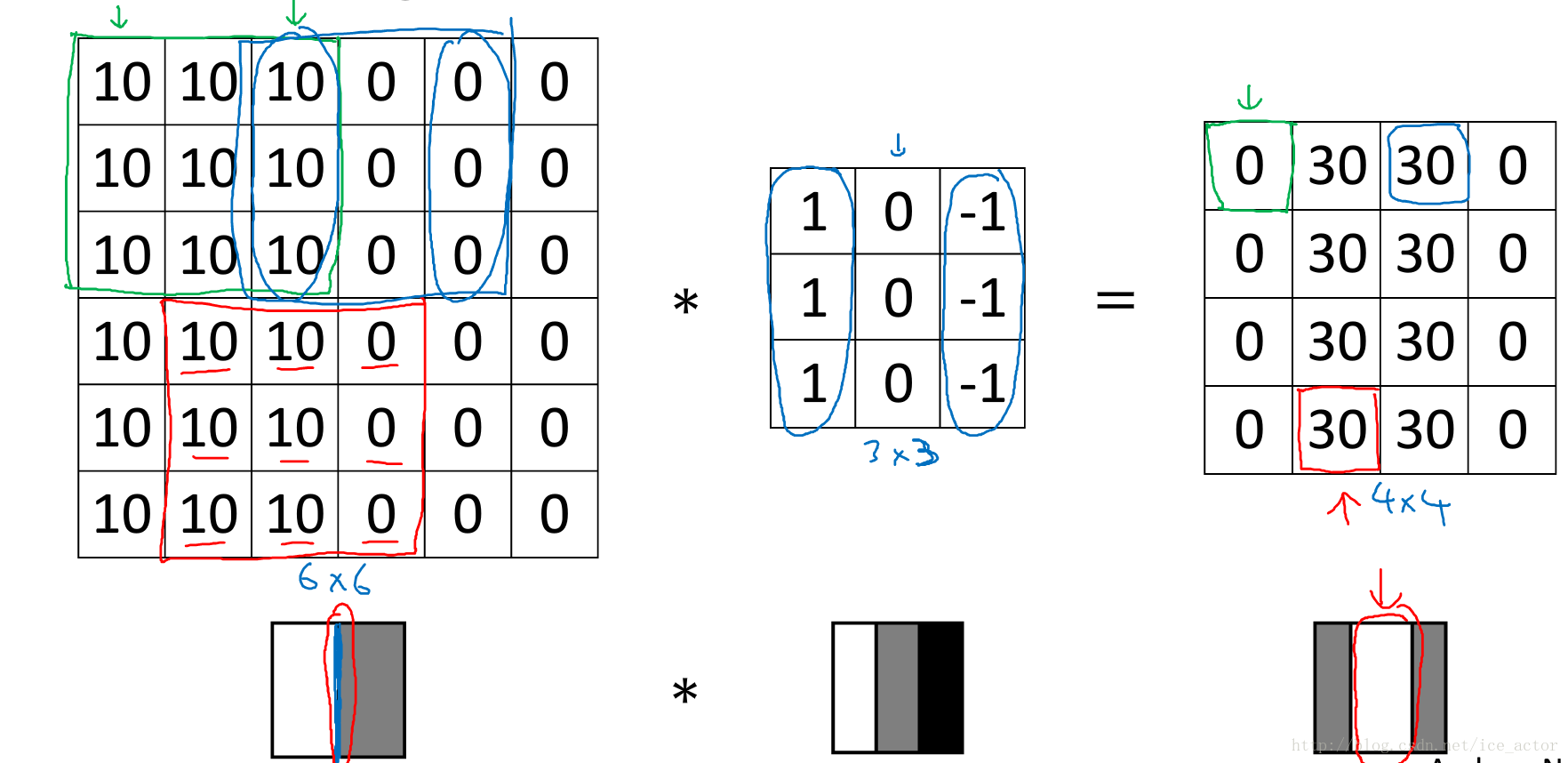
下图 0 表示图像深色区域,10为图像亮色区域,同样用一个 3 * 3 过滤器(其中,1代表亮色、0代表灰色、-1代表更深的深色),对图像进行卷积计算,得到右侧的矩阵,代表的图像信息为中间亮,两边暗(30为亮色,0为),有明显深浅交叉对比,其中 亮色区域 就对应图像边缘。
通过水平过滤器和垂直过滤器,可以实现图像水平和垂直边缘检测。还有其他类型的滤波器,在处理其他适合的任务目标方面有很好的效果。

总结:在卷积神经网络中我们要学习的便是这些滤波器 filter 的参数(神经元的权值 weight ),卷积神经网络训练的目标就是去理解过滤器的参数。
二、基础卷积概念
1. 卷积层
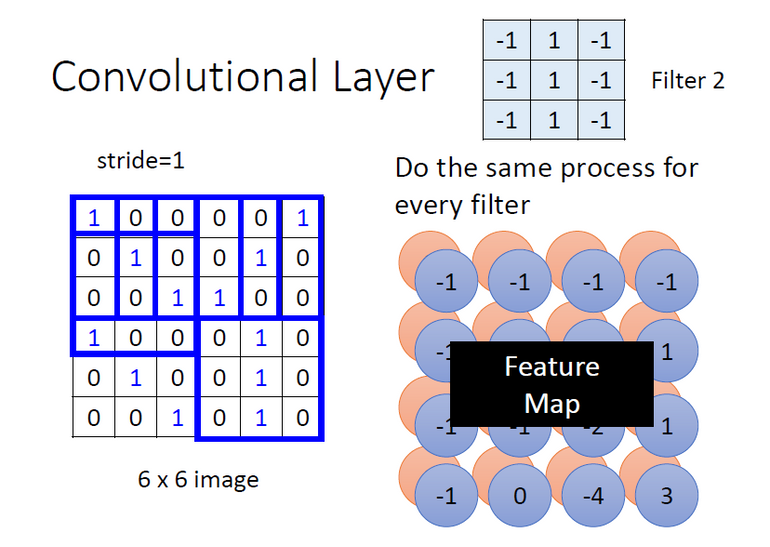
卷积层中有若干个 filter,每个 filter 可以用来 “抓取” 图片中的某一种特征(特征 pattern 的大小,小于感受野大小)。filter 的参数即是神经元中的“权值(weight)”。
不同的 filter 逐步滑动扫描计算完成一张图的矩阵后,将会产生“新的图片”,其中 每个 filter 将会产生图片中的一个 channel ⇒ 这个结果即为 feature map(特征图)
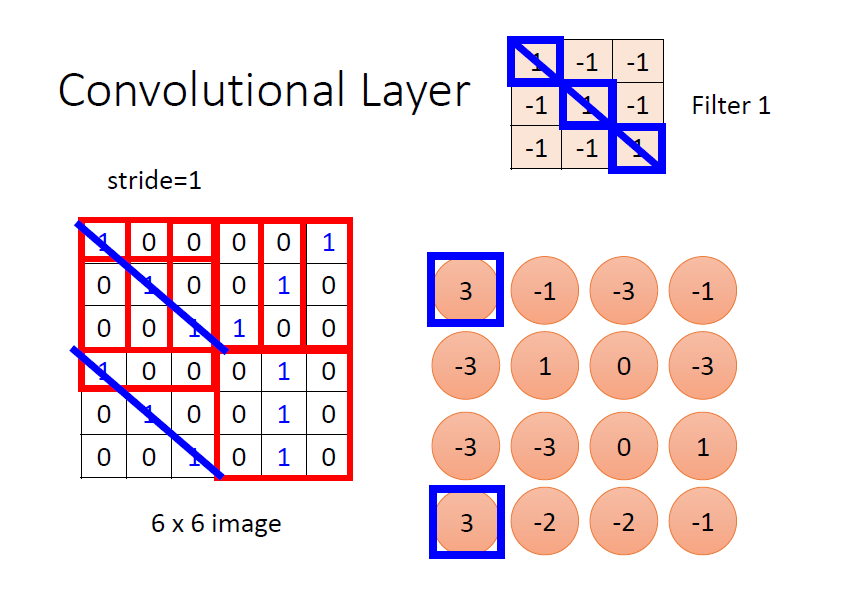
例如上图中的例子,选择的 3 * 3 滤波器对正对角线的信息敏感,因此利用此滤波器对左图矩阵的左上角进行卷积计算后,得到的结果为 3
2. padding 和 卷积步长 (stride)
上述卷积运算过程的缺点是:
① 卷积操作会降低卷积图像的大小,可能会使图像大小越来越低
② 图像的边角元素只被一个滤波器进行计算并输出使用,因此这些图像边缘的像素在输出中采用较少,也意味着丢掉了很多图像边缘的信息
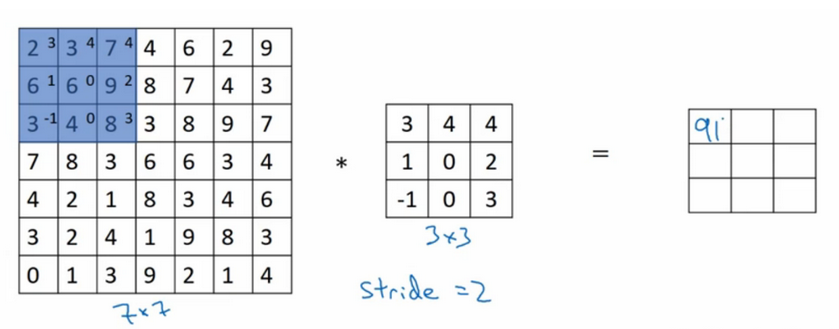
解决方法:
① 引入了 padding 操作(习惯上用0来填充),也就是在图像卷积操作之前,沿着图像边缘用0进行图像填充。对于3*3的过滤器,我们填充宽度为1时,就可以保证输出图像和输入图像一样大。
② 引入 卷积步长 stride (过滤器在图像上滑动的距离)
加入 padding 和 stride 后卷积图像大小的通用计算公式为:
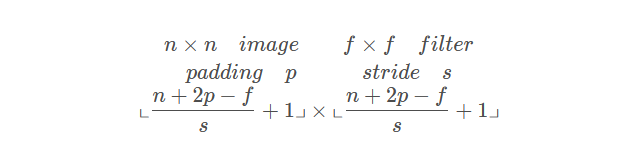
3. 补充知识点
① 参数大小: 例如有 10 个 3 * 3 的过滤器,每个过滤器都有 3 * 3 * 3 + 1 = 28 个参数(其中,3 * 3 * 3 为过滤器大小,1 是偏差系数)
② 每经过一组 过滤器的计算后 ,输出图像的通道数 就是 过滤器的个数
③ 1 x 1 卷积可以在保证高度宽度不变的情况下压缩信道数量并减少计算(降维)。
④ 迁移学习:冻结前面所有的层,只把softmax层改动以适应自己的实现。
三、 参数优化设计
1. 基础卷积操作的缺点(参数过多,影响训练)
如果输入图像的维度是 100 × 100 × 3,并且有 1000 个 Neuron,那第一层的 Weight 就有 1000 ×100 × 100 × 3( 3×10 的 7 次方),是一个非常巨大的参数数量。
虽然随著参数的增加,我们可以增加模型的弹性,我们可以增加它的能力,但是我们也增加了 Overfitting 的风险。
2. 解决方法
① 设定 “感受野”(Receptive Field)
原理:Neuron 也许根本就不需要把整张图片当作输入,它们只需要把图片的一小部分当作输入,就足以让它们检测某些特别关键的 Pattern 有没有出现。例如:在检测鸟嘴的任务中,仅需要获取下图的鸟嘴周围红框部分的图像信息即可检测出鸟嘴
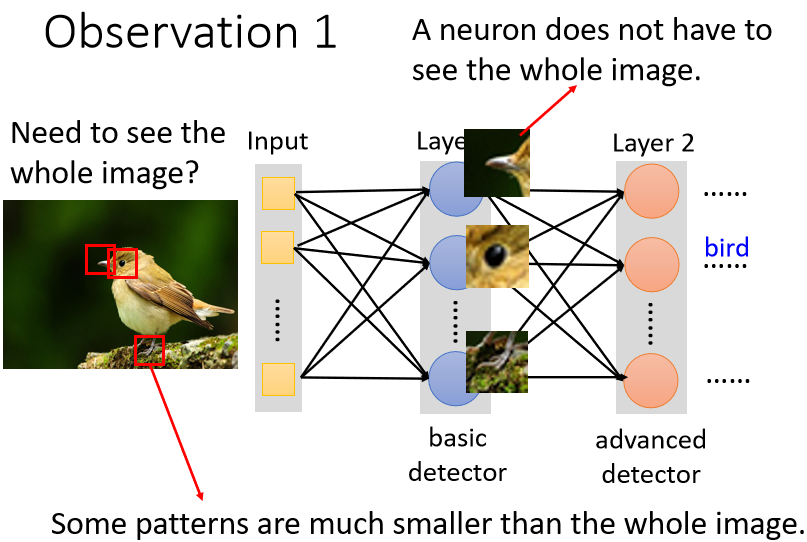
若要设置 “感受野”,每个神经元只需要考察特定范围内的图像信息,将图像内容展平后输入到神经元中即可。
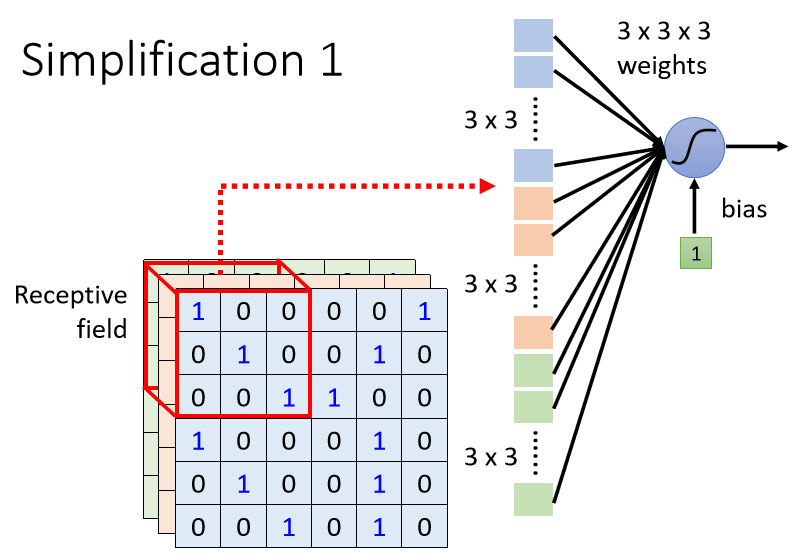
特点:
- 感受野之间可以重叠
- 一个感受野可以被多个神经元选择
- 在设置感受野大小时,感受野可以“有大有小”(一般不做过大的kernal Size,常常设定为3 * 3 )
- 感受野可以只考虑某一些 Channel
- 感受野可以是 “长方形” 的
- 感受野不一定要 “相连”
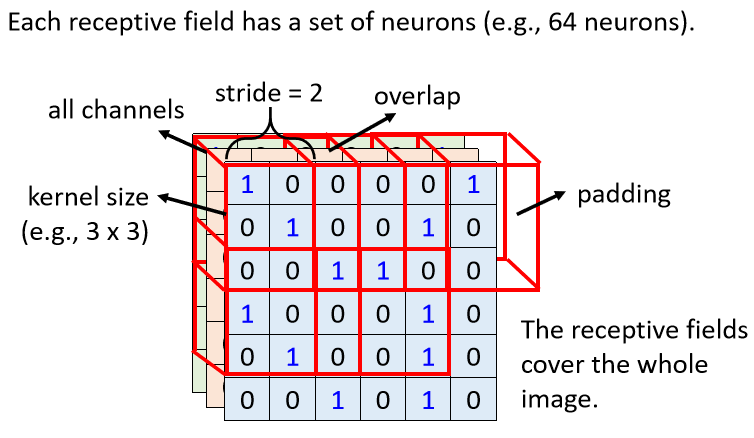
感受野的一般设定:
每一个感受域有多个神经元守备。kernel size 是宽高大小,stride 是移动的步长,padding 是边界区域扩充补值(一般是补 0)。在移动时,我们希望感受域彼此之间有重叠,防止有 pattern 在边缘交界处检测不到。图片中的每个地方都要有感受域,从头开始一步步滑动直到整个图像区域扫描完成
② Parameter Sharing 权值共享(不同 Receptive Field 的 Neuron 共享参数)
原理:同样的 pattern,可能出现在图片的“不同位置”,不同感受域的神经元起同一个作用,侦测同样pattern的神经元做的工作是类似的 ⇒ 共享参数
例如下图所示,在检测鸟嘴的任务中,相当于一个滤波器扫描整张图片看有没有鸟嘴。

例如下图所示,虽然二者选择的 Receptive Field(感受野区域) 不一样,但是它们的参数一模一样。共享的其实就是参数 w,单个神经元的参数 w 是固定的,不会因为感受域不同而改变(当然 w 初始状态为未知,是需要学出来的)。所以同一个神经元针对不同的输入会有不同的输出
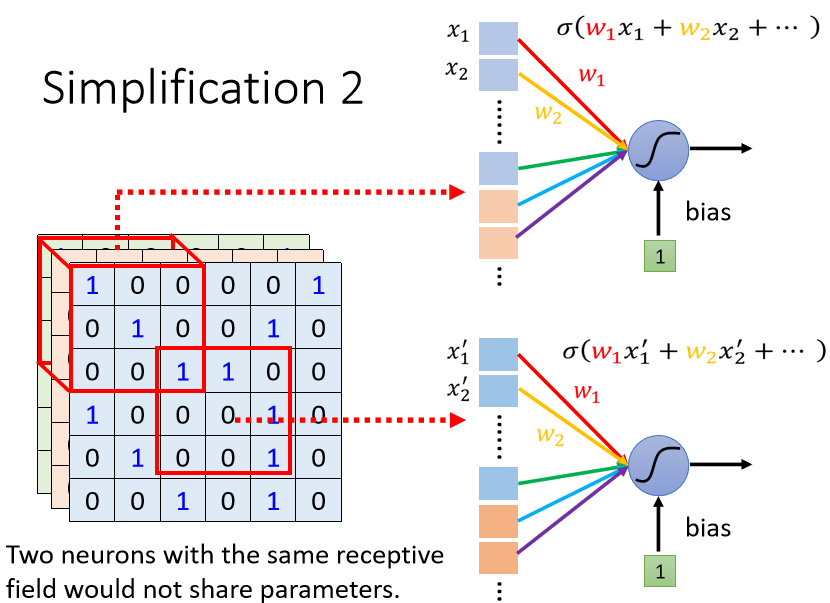
参数共享的一般设定:对每个感受野,都使用一组相同的神经元进行守备;这一组神经元被称作 filter,对不同感受野使用的 filter 参数相同。
③ Pooling(池化)把图片变小,减小运算量
池化的目的就是挑出重要的信息,然后缩小规模,减小运算量,提升运算速度。但是会造成精确度下降。
例如下图通过滤波器产生了4x4 的数字图,按照方框分成四组,每一组中选最大值做为该组代表,这就叫 max pooling(最大池化)。
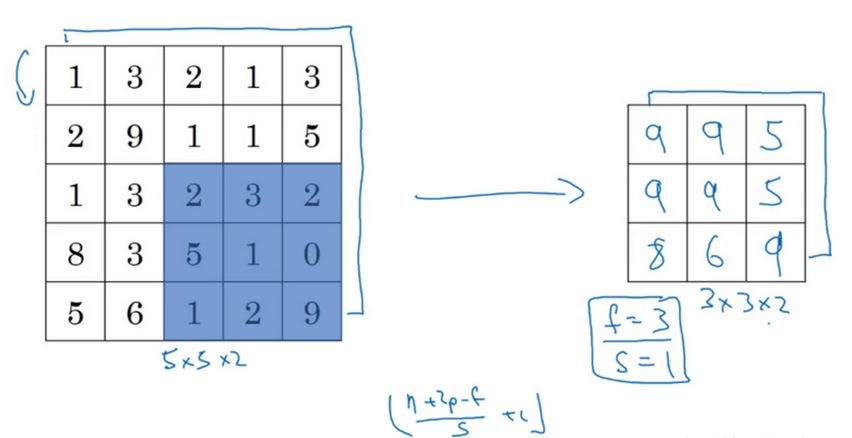
假如是将每一组的平均值作为该组代表,那么就叫做 mean pooling (平均池化)。
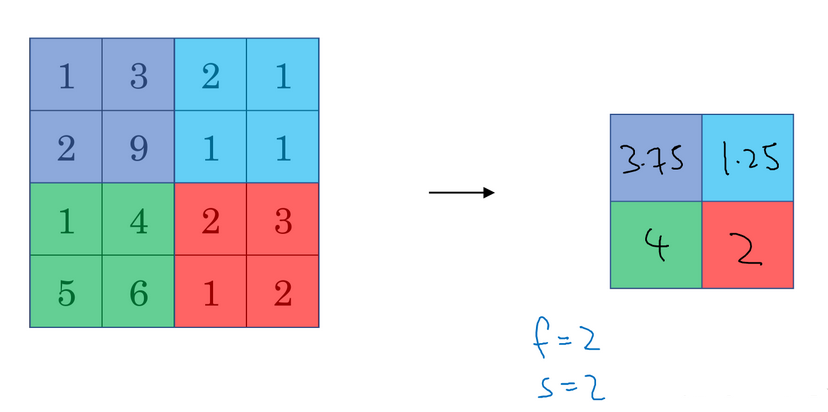
平均池化和最大池化唯一的不同是,它计算的是区域内的平均值而最大池化计算的是最大值。在日常应用使用最多的还是最大池化,除了一些较深的神经网络。
池化的超参数:步长 stride 、过滤器大小 filter size 、池化类型最大池化 / 平均池化
四、CNN的全流程总结
通过卷积层,池化层,拉直(flatten),全连接层,softmax 后,输出结果去分类。不过随着技术的提高,运算能力越来越强,可以不使用池化层来提高精确度(因为现在很多实验环境算力都够用,池化层的目的显得越来越没必要,所以在设计每一模块的时候都要考虑当前任务及实验环境,根据这些因素去设计最符合的网络)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号