李宏毅机器学习2022年学习笔记(一)-- Introduction

二. 机器学习的种类
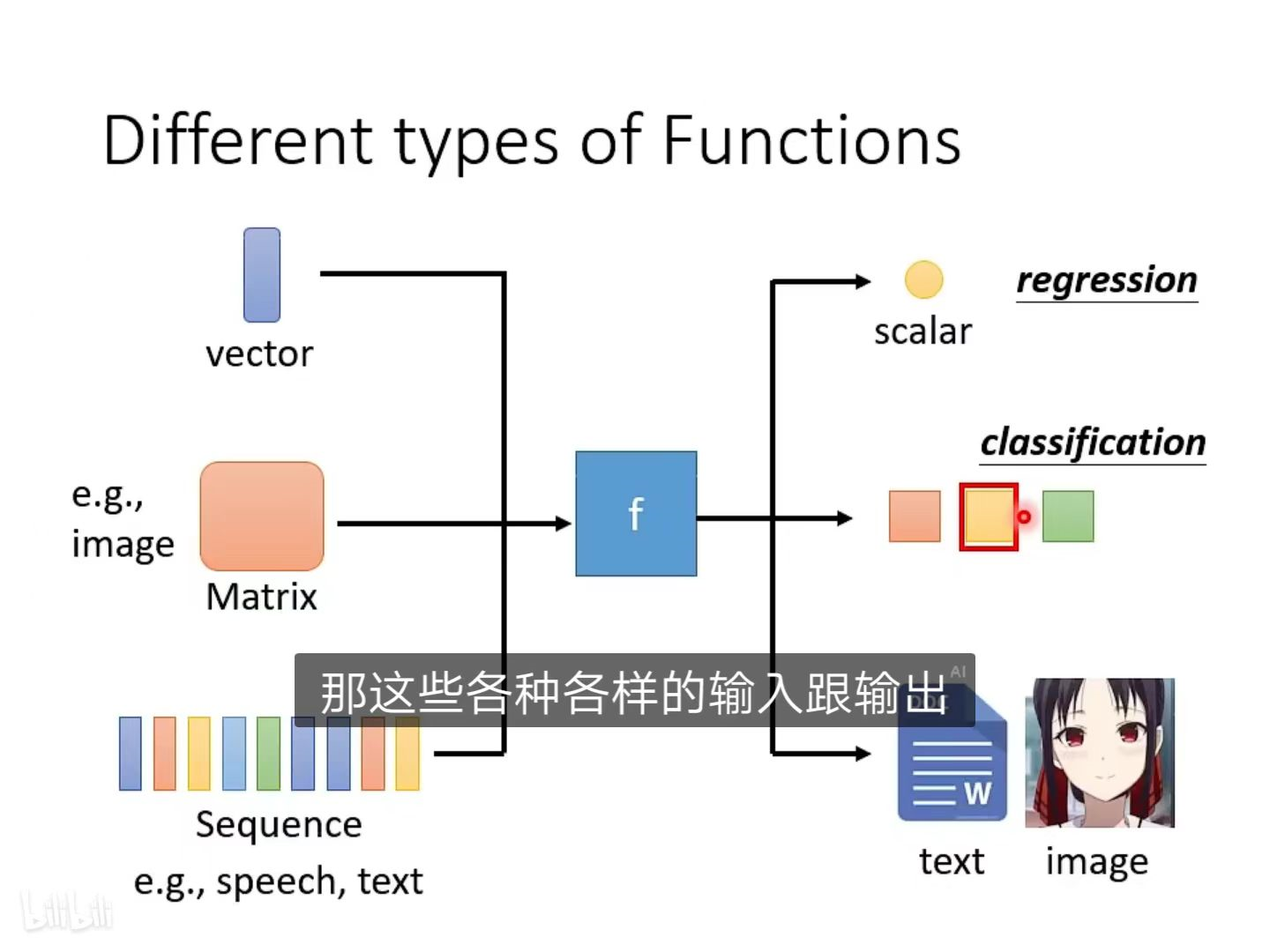
根据不同的任务从而选择不同函数方法的不同,机器学习最常用的是regression(回归)和classification(分类)。
regression(回归):模型的输出为数值,一般应用于预测房价、温度、空气指数等。例如:输入和目标任务PM2.5相关的feature,经过该模型所设计的方法流程计算后,就能得到预测的明天的PM2.5数值并且输出。寻找这一组方法的过程就是Regression需要完成的任务。
classification(分类):多适用于做选择时,事先给定期望输出的一些类别结果,模型根据输入可以输出对应的类别。例如:分类模型能甄别邮件是否为垃圾邮件;下棋中使用分类模型预测下一步落在哪个棋盘格上赢面最大。
Structured Learning(结构化学习):机器在学习的时候不只输出一个数字,不单单做选择题,还要生成有结构的物件。也就是让机器学会创造。
三. 机器学习的步骤
1. Function with Unknown Parameters(未知参数函数)
根据domain知识,猜测一个能完成任务并带有未知参数的函数。
设y为要预测的最终结果,x1为输入的前一天观看总人数,b与w均属于未知参数。刚开始猜测未知参数需要人们对于问题的本质了解,也就是需要Domain knowledge(领域知识)。一开始的猜测不一定是对的,需要后续的修正。
总之先假设y = b+w*x1,
b与w是未知的,称为参数(parameter)
这个带有Unknown的Parameter的Function,称之为Model(模型)
x1在这个Function中是已知的,是前一天的后台数据,称之为Feature(特征)
w是与Feature相乘的数,称之为weight(权重)
b没有与feature相乘,称之为Bias(偏离率)
2.Define Loss from Training Data(定义训练数据的损失函数)
根据训练资料,定义loss函数,用来衡量函数解和真实情况的差距。

Loss:是关于选取未知参数后的函数,不同参数的选择从而产生不同的函数,计算出不一样的Loss,而Loss的作用就是用来评估这些未知参数的选取好还是不好。
L越大,代表当前的参数值的选取越不好;L的值越小,代表当前的这一组参数的选取越好。
现在我们使用的计算Loss的方法有以下几种:
mean absolute error(*均绝对误差)MAE;
mean square error(均方误差)MSE;
Cross-entropy(交叉熵):当y与y∧的值都为概率的时候,可以使用。
第三步:通过不断优化,找到能使loss最小的参数,也就是使函数解尽可能接*真实情况。这三步都属于training过程。最后train出来的参数能使模型预测最准,将这个模型用于预测没有看过的资料的过程叫做testing,一般testing 的 loss 会比 training 的 loss 高。
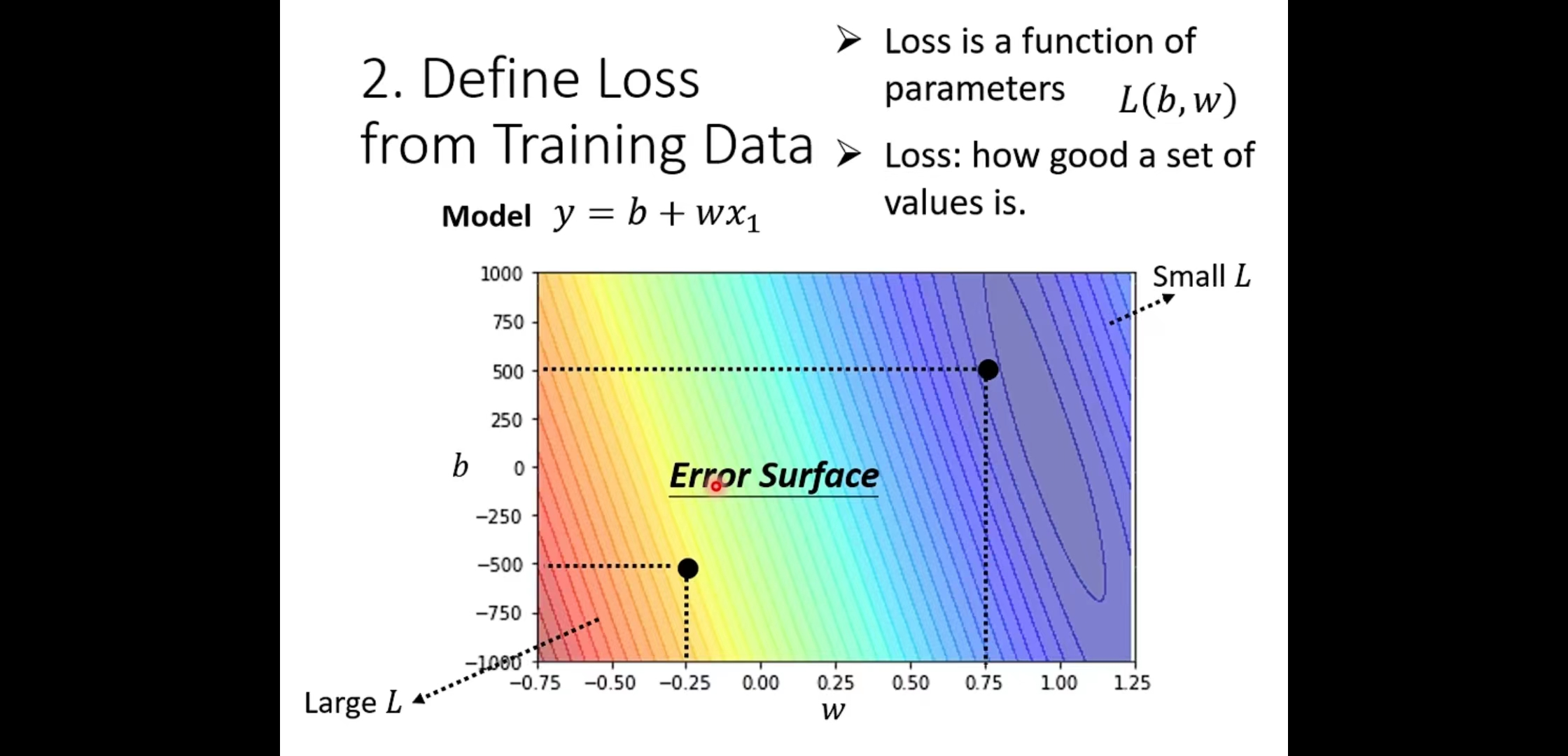
Error Surface(误差曲面)
该图为一个真实数据计算出来的结果,我们可以调整b和w,让其取不同的值,每种组合都计算其Loss的值,画下其等高线图(Error Surface)。
在这个等高线图上面,越偏红色系,代表计算出来的Loss越大,就代表这一组w跟b未知参数的选取越差;如果越偏蓝色系,Loss越小,就代表这一组w跟b未知参数的选择越好。
3.Optimization(最优化)
优化的目的就是找到使 loss最小的参数,找到参数之后的模型就能真正用来预测了,也就是找到一个合适的w与b,可以让Loss的值最小,我们让这两个合适的参数称为w*和b*。本例中使用Gradient Descent方法进行优化。
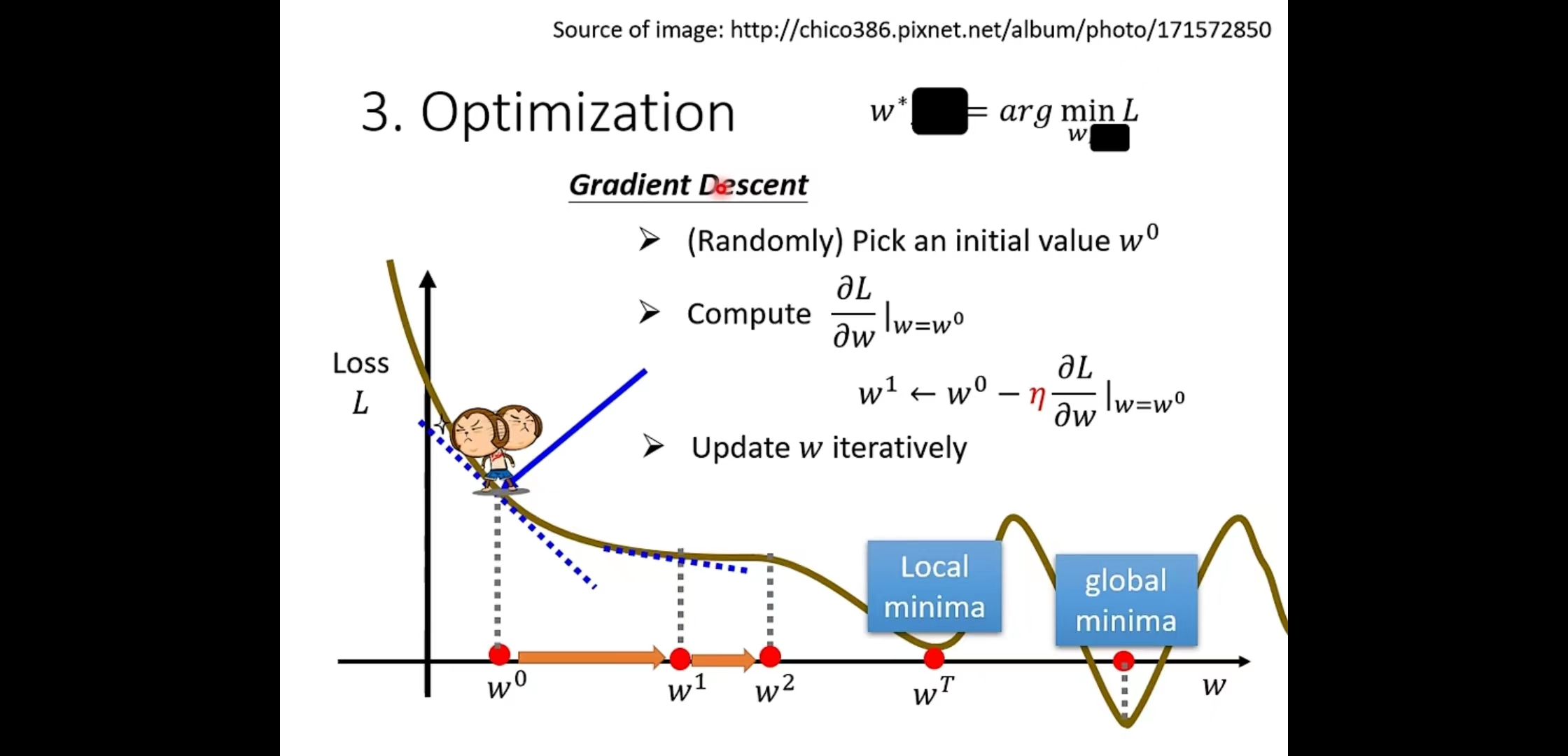
寻找w的方法
1. 随机选一个初始的点,w0。(不一定完全随机,有选择的方法)
2. 计算 w = w0 时,w对loss的微分是多少,也就是在wº上误差曲面的切线斜率
3. 如果斜率为负值,就把w的值变大,可以让loss变小。
如果斜率是正的,就代表Loss值左边比较低右边比较高,w往左边移,可以让Loss的值变小。
同时,Learning rate(学习率)是影响w移动步长的重要因素,令学习速率为η。
η的值越大,w参数每次update到下一个位置的步长幅度就会越大;
η的值很小,则参数update就会很慢,每次只会改一点点参数的值。
(这类需要人手工设置的参数叫做hyperparameters 超参数)
如上图,经过w不断的重复进行update来移动位置从而减小Loss值,直到停下来。但是该方法也有一个缺点,因为停下来有两种情况:
1. 在计算微分的时候操作者已经设置了更新次数的上限制,例如update达到100万次以后就不会再更新。
2. 代表斜率已经为0,最好的情况是已经到达了global minima,使得Loss减小到了最小值。 但也无法分辨是否是达到了不好的情况,即:停止点仅仅是local minima,还没有到达Loss最低值,但更新操作已提前结束。
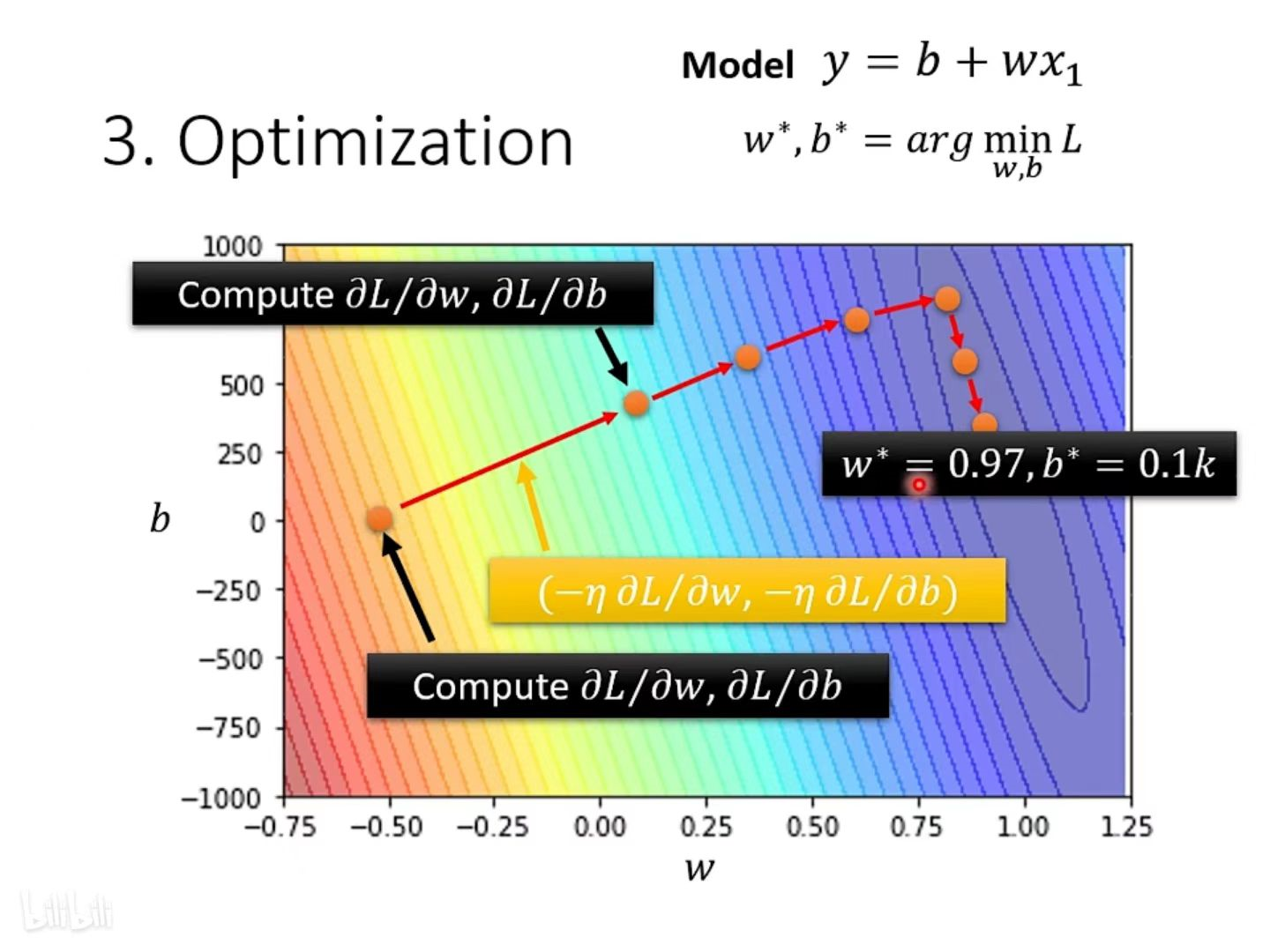
同样的原理,加入第二个未知参数b, 同时观察 w 和 b。优化过程如下:
第一步:随机初始化参数w0和b0。
第二步:计算该点的 loss 关于参数的微分值,用微分值去更新参数。
第三步:不断重复:计算微分值,更新,直到 loss 达到阈值。

具体操作方法:
在初始值处计算w与b分别对Loss的微分,然后更新w与b,更新方向为上图中标黄的向量。也就是算出微分的值就可以决定更新的方向,把w跟b更新的方向结合起来,就是一个向量,就是上图中红色的箭头。
之后再计算一次微分,根据微分决定更新的方向,以此类推,直到找到一组合适的w和b。 经过不断更新后的等高线图如下图所示。
四. 如何表示更复杂的模型(单变量)
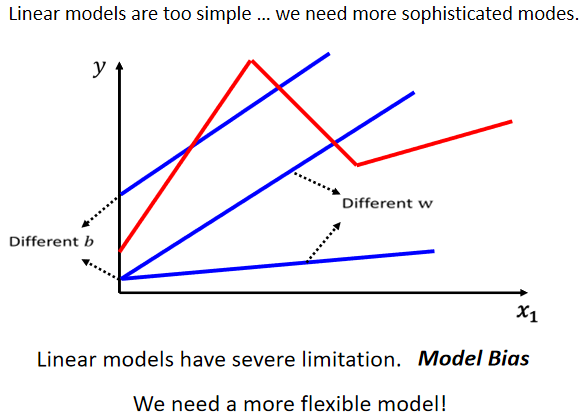
1. 连续曲线
最有弹性的模型就是连续曲线,因为它描述复杂问题最为精准。用线段去逼**滑的曲线,充足的分段线性曲线可以逼*连续曲线
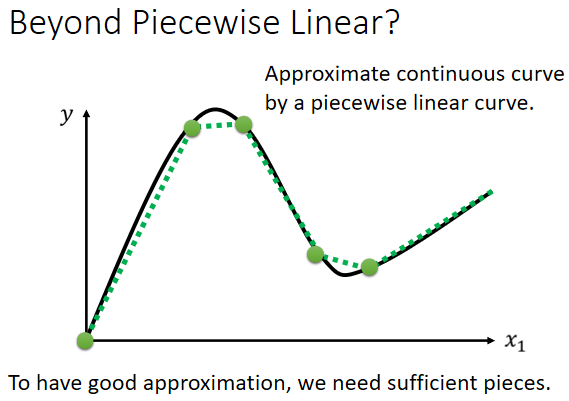
2. Piecewise Linear Curves(分段线性曲线)
1.模型定义
红线是分段线性曲线,蓝线是不同的hard sigmoid函数。下图中的 0 + 1 + 2 + 3 加在一起就变成了红线,所以用一堆的 hard sigmoid函数加上一个常数可以组成分段线性曲线。
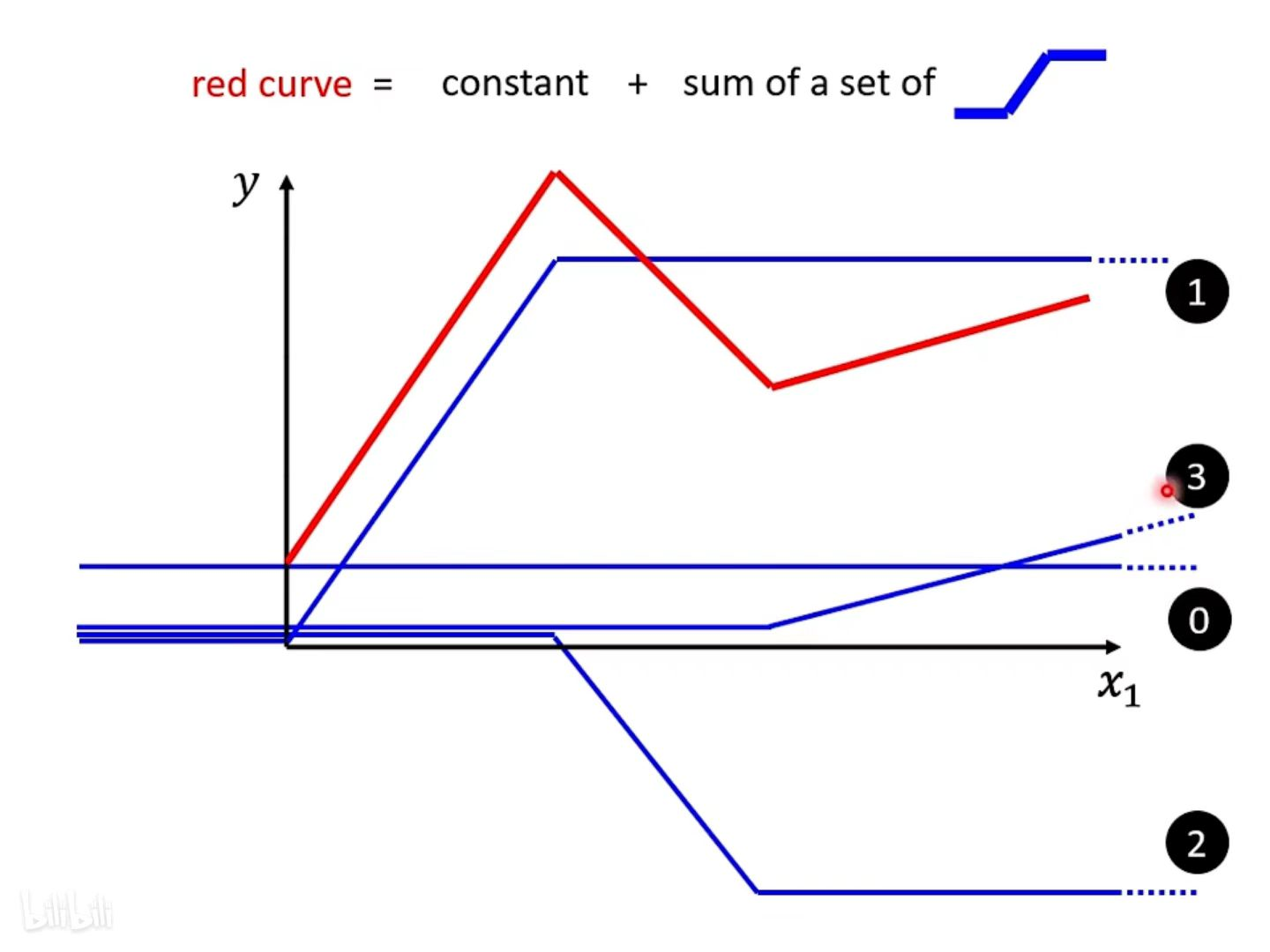
分段线性曲线的折线越多,需要的 hard sigmoid函数就更多,从左到右,需要的 hard sigmoid 在逐渐增多。
2. 结论:
- 可以用 Piecewise Linear 的 Curves,去逼*任何的连续的曲线
- 每一个 Piecewise Linear 的 Curves,都可以用一大堆蓝色的 Function加上一个常量组合起来得到
- 只要有足够的蓝色 Function 把它加起来,就可以变成任何连续的曲线
3. Hard Sigmoid
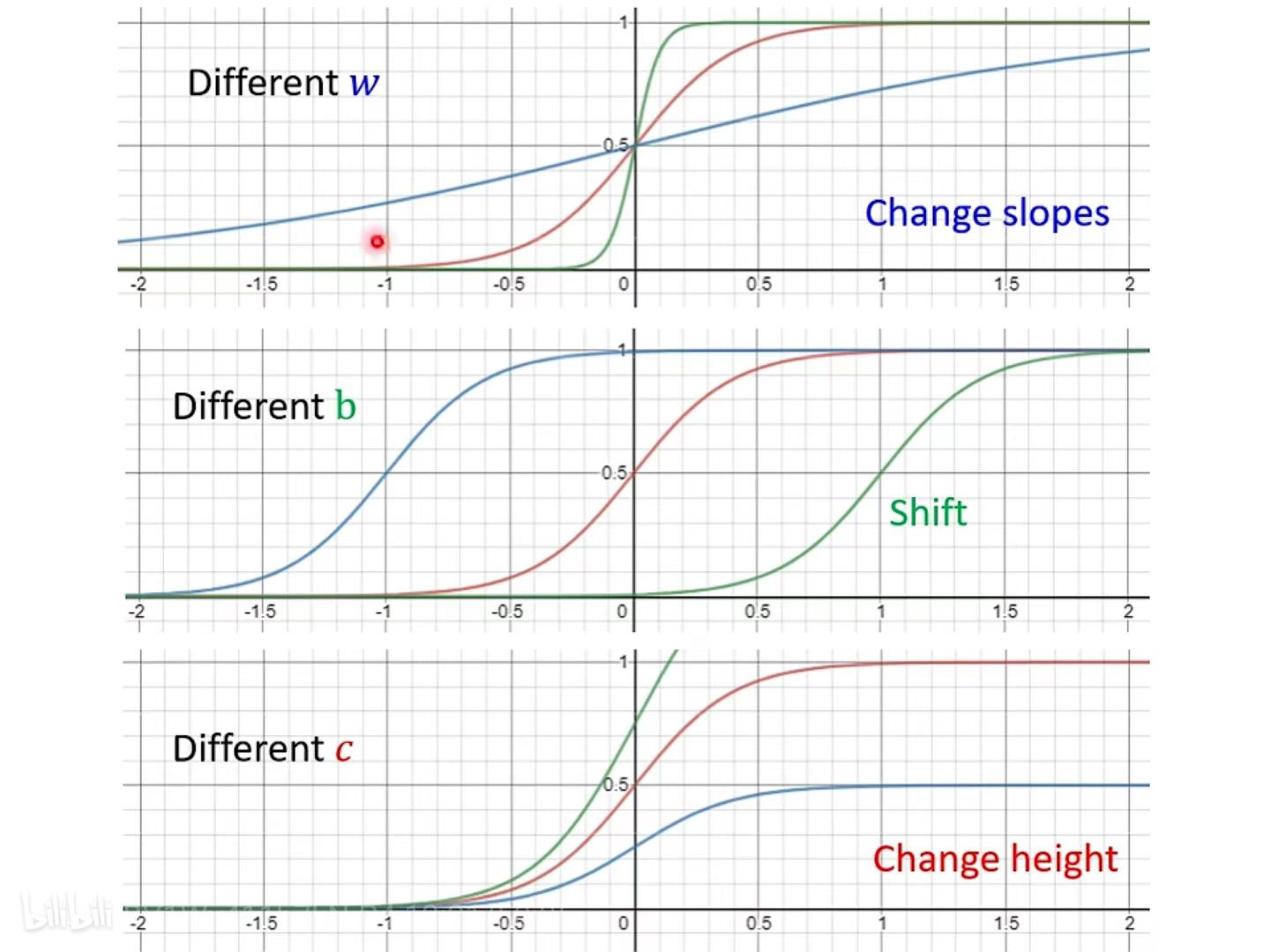
hard sigmoid 可以组成分段线性曲线,而 hard sigmoid 可以用 sigmoid(S型曲线)来代表,因为差别很小可以忽略。S型曲线中的 c、b、w都是参数,需要机器学出来。
为什么不将 hard sigmoid 作为基础函数呢?因为转角处无法求微分,所以要用一个*滑的曲线做基础函数。
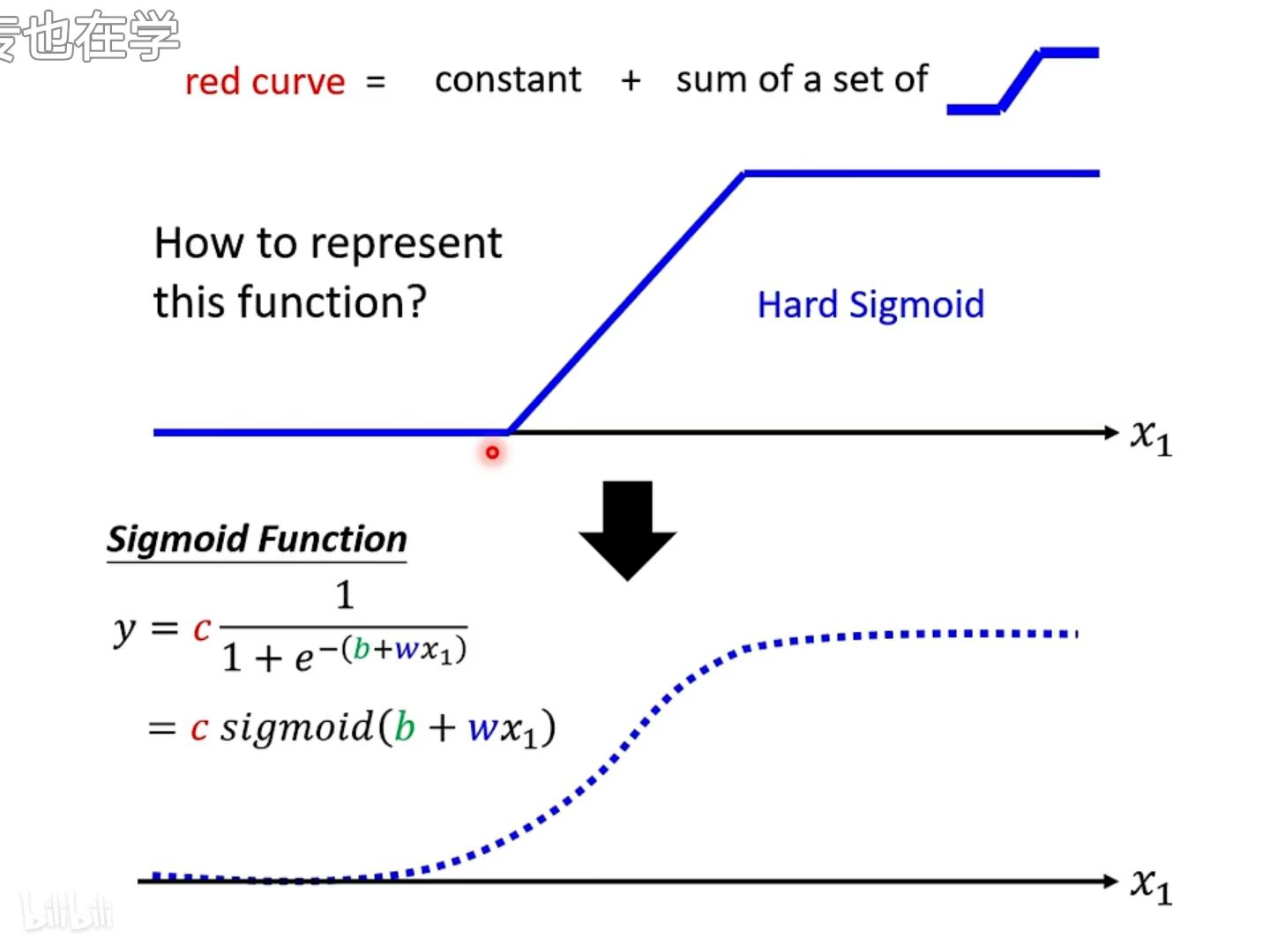
4. Sigmoid函数
c、b、w这三个参数可以得到各种不同的sigmiod来逼*”蓝色function“,通过求和,最终*似各种不同的 Continuous 的 Function
- 改变斜率 可以改变斜坡的坡度
- 改变b 可以把这个 Sigmoid Function 左右移动
- 改变c 可以改变它的高度
总结:利用若干个具有不同 w,b,c的Sigmoid函数与一个常数参数的组合,可以模拟任何一个连续的曲线(非线性函数)
总结
先用 sigmoid 代表 hard sigmoid,然后由 sigmoid 和一个参数组成分段线性曲线,分段线性曲线再去组成连续曲线。
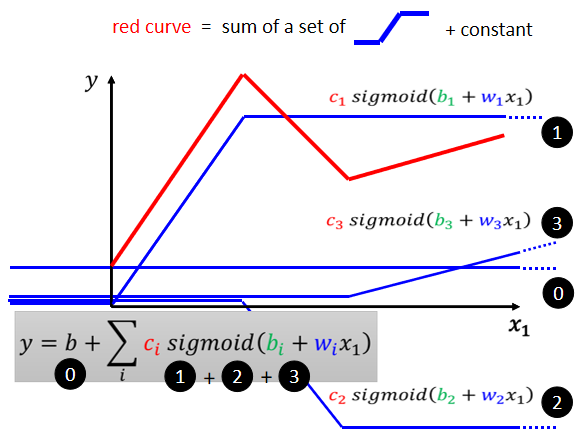
我们把 1+2+3 加起来,这边每一个式子,都代表了一个不同蓝色的 Function,将这些不同的蓝色的 Function 加起来,每一个 sigmoid函数表示红线中的某一段,这样就可以拿来*似各种不同的 Continuous 的 Function
五. 如何表示更复杂的模型(多变量)

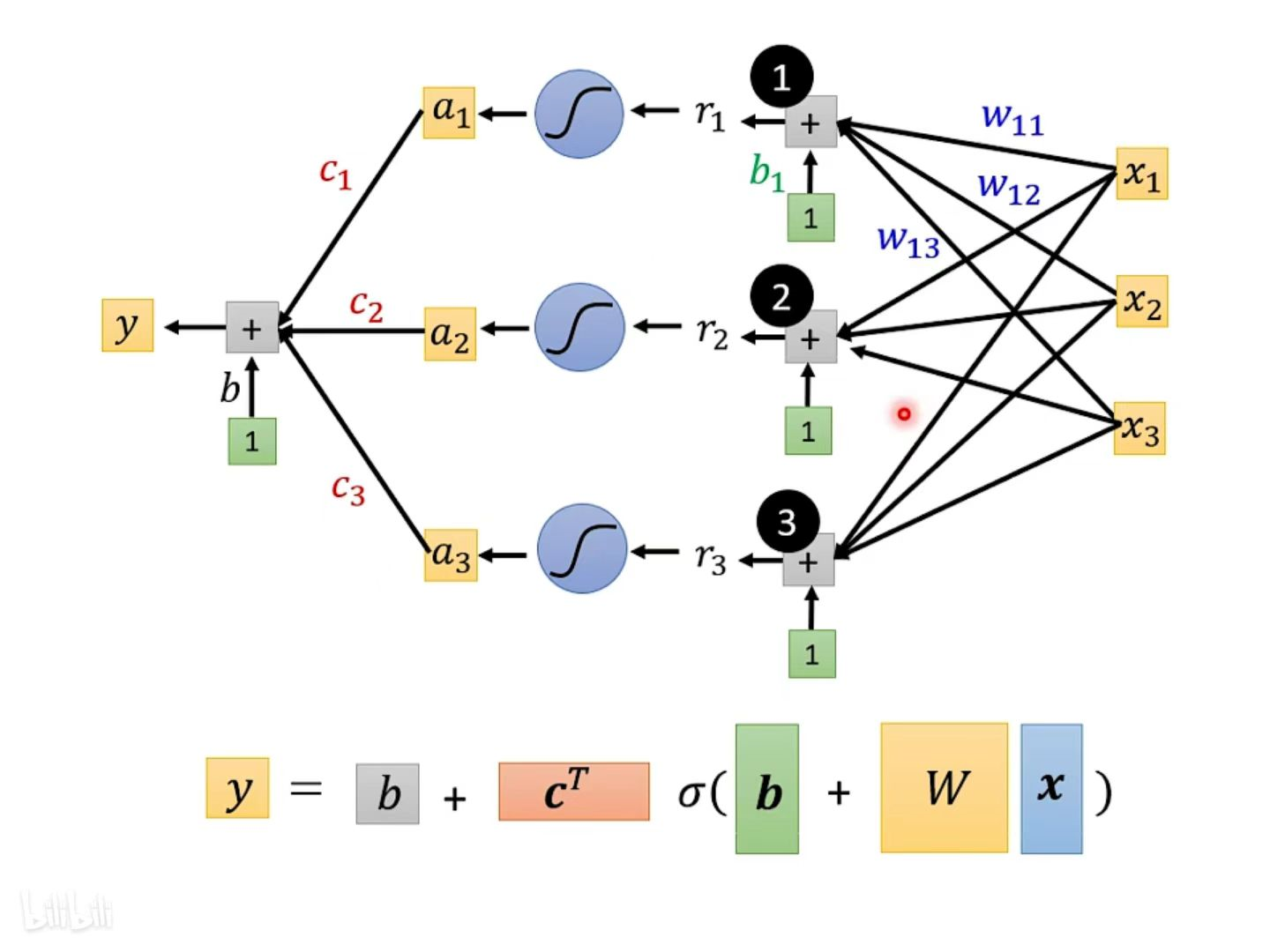
将起初讨论的仅单变量 x1 的情况变成多个 feature,其中j用来表示 feature 的编号,同时 sigmoid 函数内也相应考虑每一个feature的情况,每一个 Sigmoid 的 Function 裡面都有不同的 bi 不同的 wi,然后取 Sigmoid 以后乘上 ci 全部加起来之后,再加上偏移量 b 就得到最终的 y ,这样不同的 w / b / x 组合就可以得到不同的 Function。

for i 循环分别计算r1, r2, r3,将每一个 xj 输入 feature 分别与 wij 相乘并求和,可以看作是矩阵向量相乘的关系。x 乘上矩阵 w 再加上向量 b,得到向量 r。
接下来将 r 通过 sigmoid Function 求得 a 向量,乘矩阵向量 c 的 转置 Transpose 之后再加上偏移矩阵向量 b ,最终求得y的结果。
用线性代数中向量矩阵相乘的方式来表示上述操作,
其中,
x 是Feature,
W是权重组成的矩阵,
绿色框的 b 为向量,灰色框的 b 为数值,
c 为常数组成的向量。
W、c、向量 b 、常数 b 是未知的参数,把这些未知的参数组合成一个长的向量:把 W 的每一行(或每一列)拿出来组合成一个长的向量,再把向量 b 组合进来,再把 c 的转置组合进来,最后再加入常数 b 。最后形成了一个长向量,用 θ 来表示,其中里面的θ1 θ2……都是来自上述的未知参数,所有的未知参数统称为θ。

六. define loss from training data(多变量)
有了新Model之后,我们需要进行第二步,从训练数据中定义Loss函数。
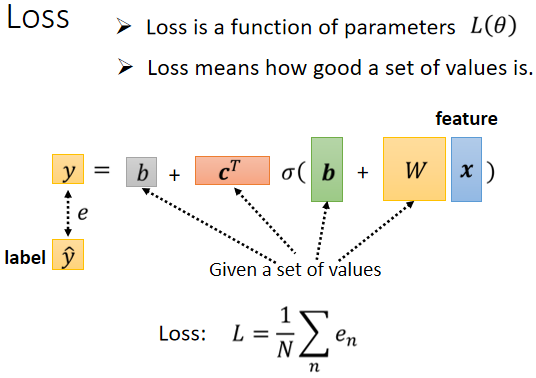
计算Loss值的流程依旧和只有两个参数的时候类似,具体步骤如下:
1. 先给定(或随机)一组值(θ)2. 代入一种 Feature x 的值,计算出预测的 y 值是多少

整个操作流程如下:
1. 先随机选择(或用更好的方法)一个初始的数值 θ0 计算其对L的微分,这样每一个位置的参数计算他们对L的微分之后的集合,是一个向量,用g表示,来代表 Gradient(梯度)。
2. 算出梯度后,需要根据得到的梯度将 θ0 更新为 θ1,其中学习率的选择也与更新幅度有关
3. 之后再根据θ1计算新的Gradient,再把θ1更新为θ2……以此类推,直到计算次数达到了预先指定的上限,或者计算出来的梯度为0向量,无法再更新参数为止。
总结
1. 写出一个有未知参数的function,参数θ来表示
2. 确定损失函数,判断function的参数θ 好不好
3.optimization,得到使损失函数最小的参数θ*
有了 θ* 以后,就把它拿来用在测试集上,把 Model 中的参数用 θ* 来取代,它的输入就是你现在的测试集。
八. 批处理
如果在求Gradient时候,数据N过大,为了加快更新速率,一般会把这N个数据分成一个一个的Batch(一批;批处理),也就是对N个数据进行分组,设每个Batch中有B个数据。
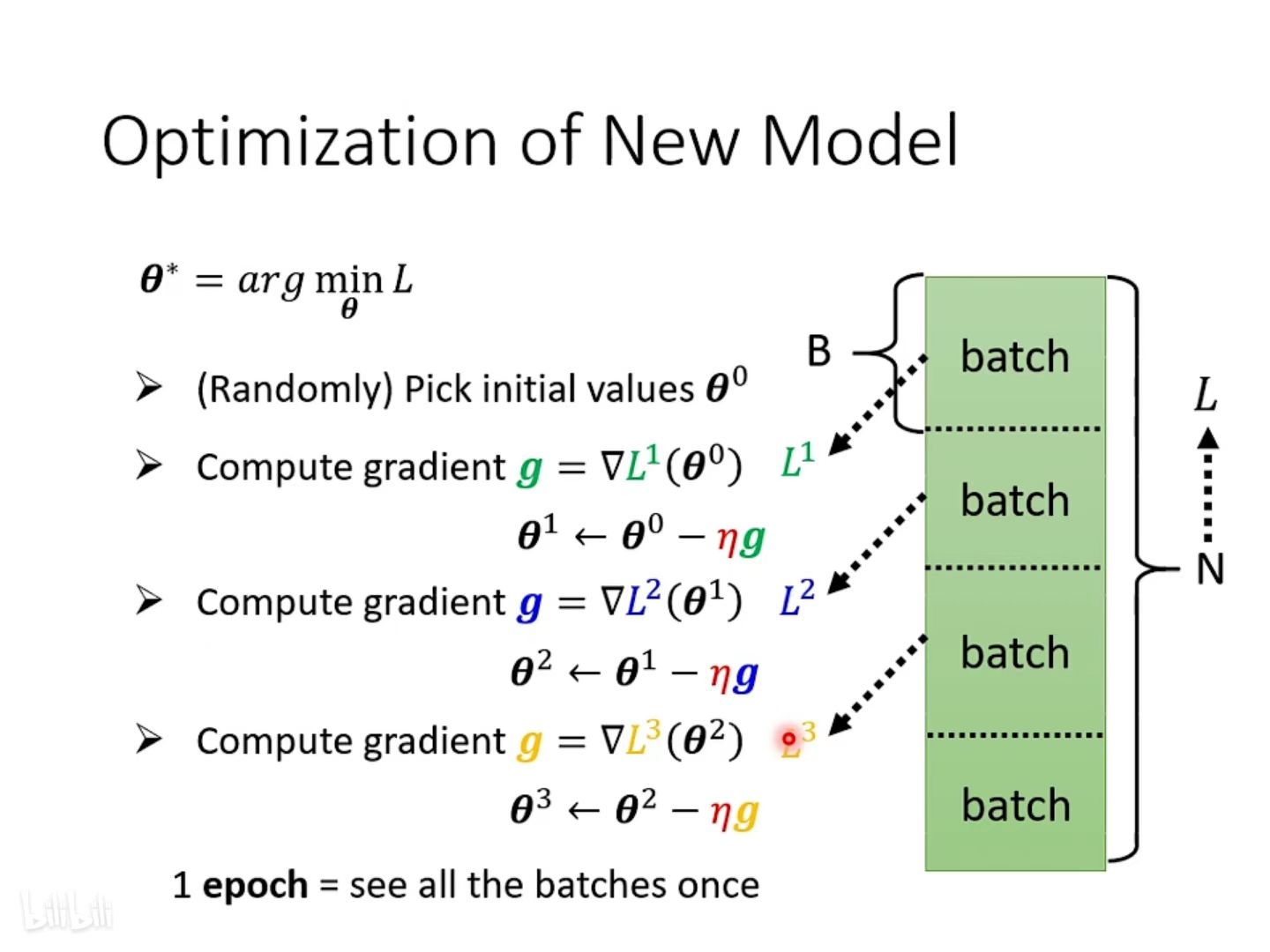
实际操作如下:
1. 先选择一个Batch,用这个Batch 来算其 Loss,计为 L1,根据这个 L1 来算 Gradient,用这个 Gradient 来更新参数
2. 接下来再选下一个 Batch 算出 L2,根据L2 算出 Gradient,然后再更新参数
3. 再取下一个 Batch 算出 L3,根据 L3算出 Gradient,再用 L3 算出来的 Gradient 来更新参数。
其中,每个 Batch 每更新一次参数的过程为 update,每过完一轮全部的Batch是一次Epoch
计算方法:假设我们有10000个Data,也就是N=10000,设我们的 BatchSize是10,也就 BS = 10,则会产生 10000 / 10 = 1000 个 Batch,所以在一个 Epoch 里更新参数 1000 次
九. 神经网络基础
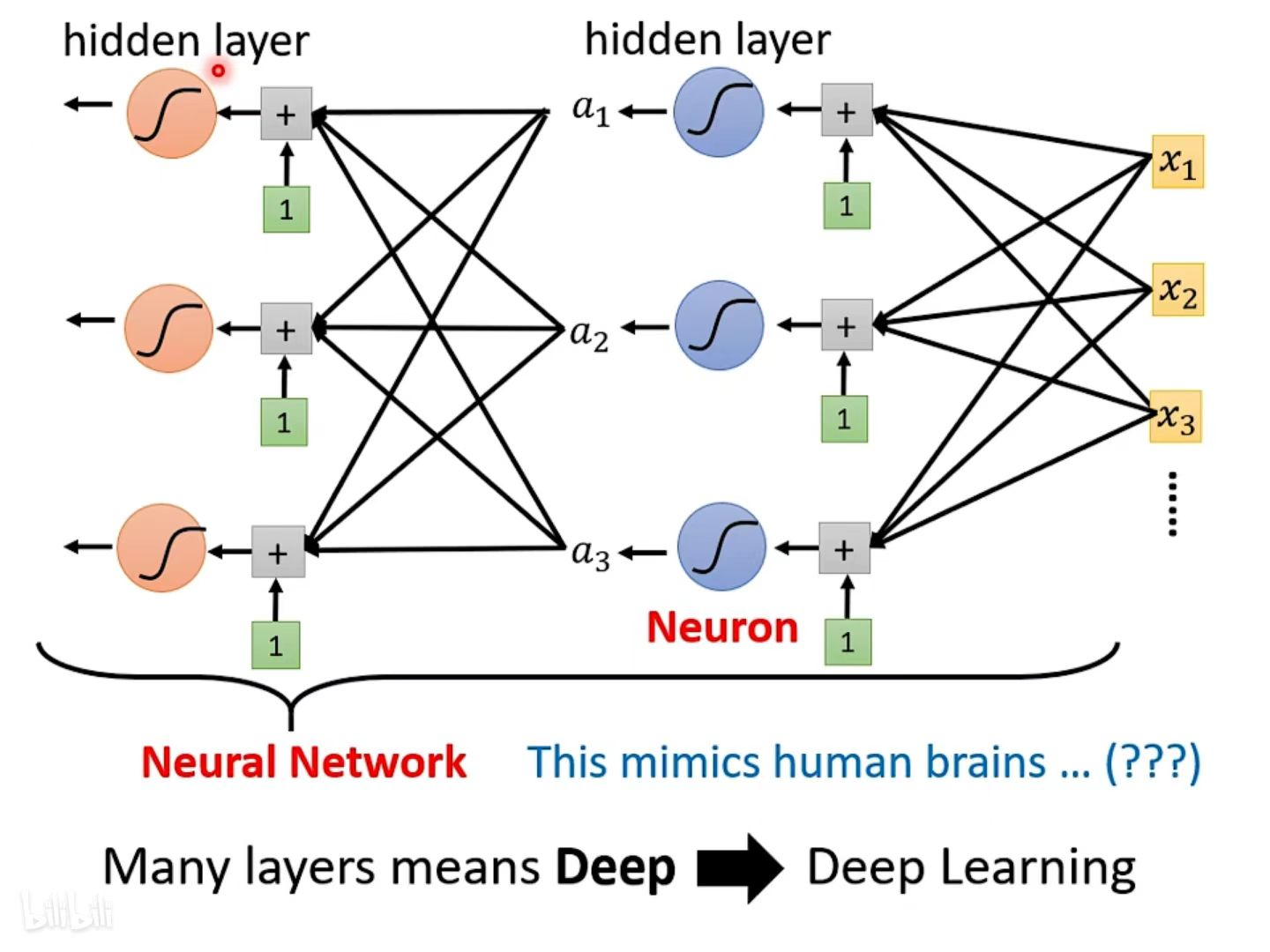
Model中的Sigmoid或ReLU称为Neuron(神经元) ,多个神经元连起来就是Neural Network(神经网络)
图中每一层的神经元称为hidden layer(隐藏层);多个Hidden Layer就组成了Deep;以上的整套技术就称为Deep Learning(深度学习)
深度学习的层数也不能太多,太多会导致Overfitting(过拟合),也就是在训练集上表现的好,但是在测试集上表现差。
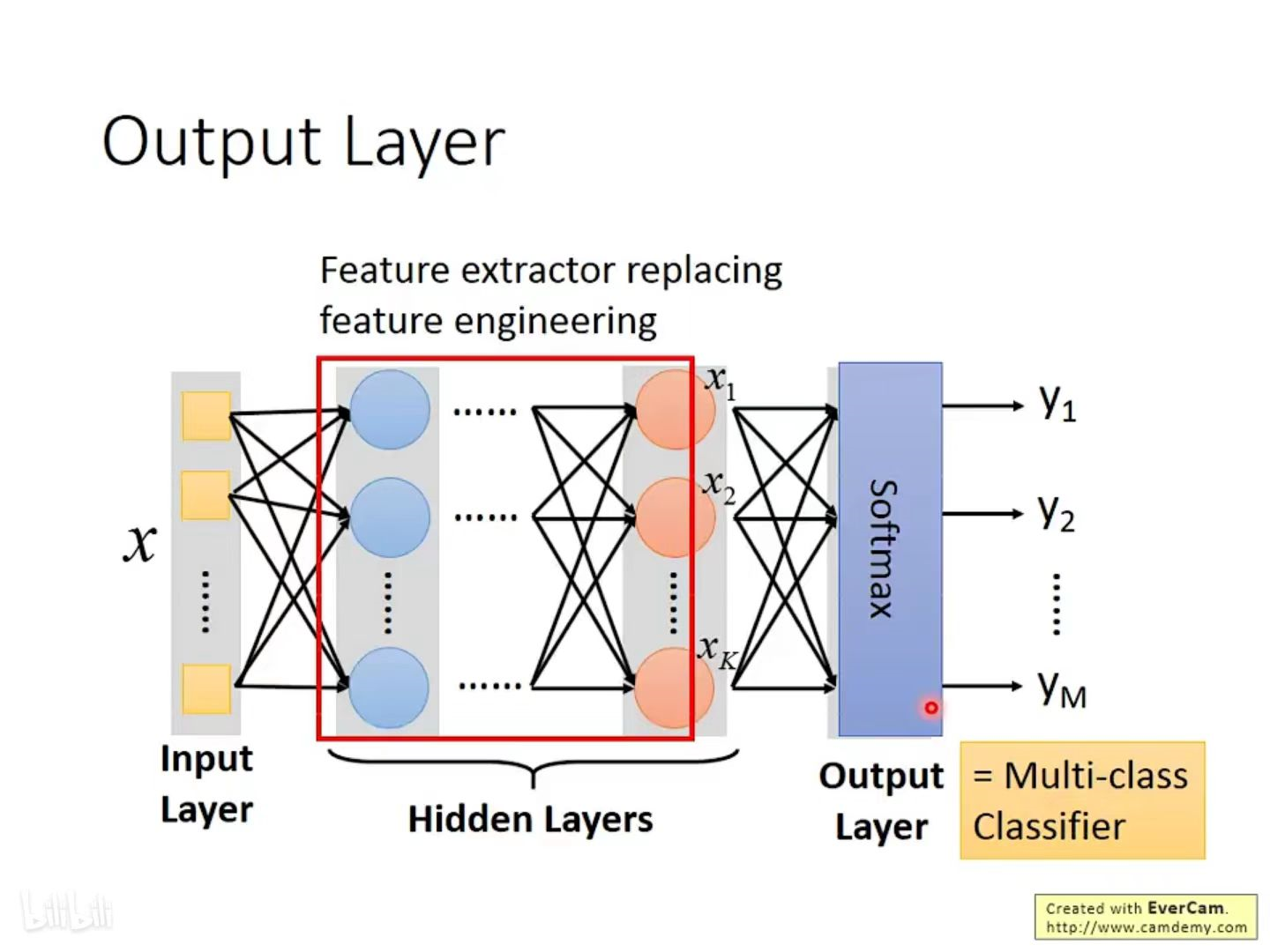
在 Hidden Layer 中,需要设计相应的网络结构使我们能在 function set 中找到一个能使 Loss 值减到最小的 function
在 Output Layer 中,通常在分类任务中使用Softmax函数,输出每个分类结果的概率值,表示这个类别的可能性;将多分类信息,转化为范围在[0,1]之间和为1的概率分布,其中概率最大的分类结果所代表的类别即为最终预测的分类类别。
十. 数据集划分
从吴恩达 AI for Diagnosis 课程那里学来的训练集一般60-80%,验证集和测试集各10-20%左右,不过一般如果数据集比较小的话可以直接训练集80测试集20(6:2:2,如果我记错了私密马赛,等毕业六月份补这个专项课程的第二项前再回顾,然后补正确)
其中,Testing data 是仅有输入数据的,输出结果是隐藏状态,测试时并不可见他的真正输出 label,避免过拟合


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· .NET10 - 预览版1新功能体验(一)