

大数据应用期末总评——Hadoop综合大作业
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
此处选取的是爬虫大作业——对猫眼电影上《小偷家族》电影的影评。
此处选取的是comment.csv文件,共计20865条数据。
将comment.csv上传到HDFS
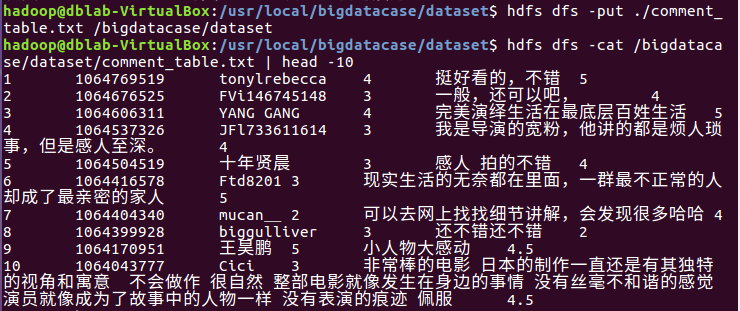
2.对CSV文件进行预处理生成无标题文本文件
编辑pre_deal.sh文件对csv文件进行数据预处理。
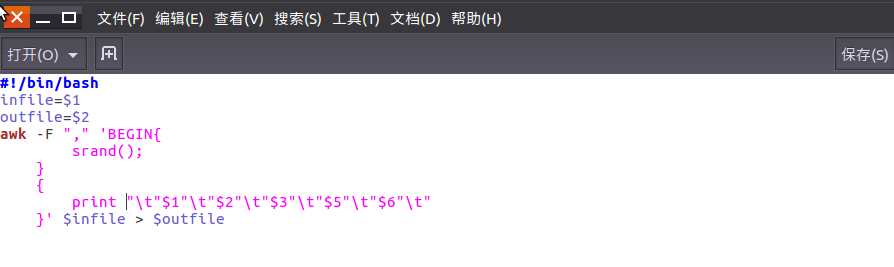
使得pre_deal.sh中的内容生效。
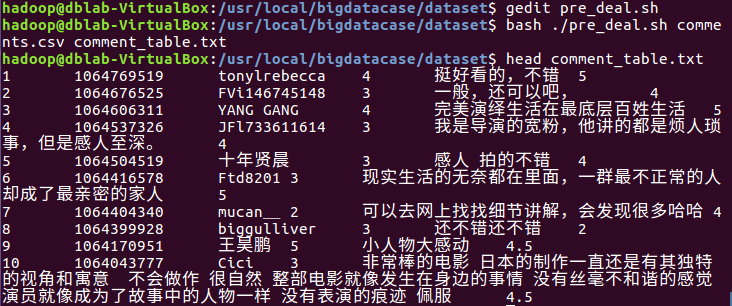
3.把hdfs中的文本文件最终导入到数据仓库Hive中
创建数据库dblab;
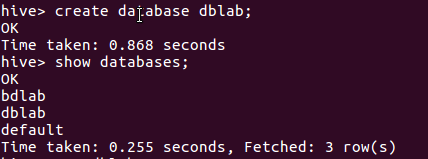
在数据库dblab中创建相应的表,此处是bigdata_user。

4.在Hive中查看并分析数据
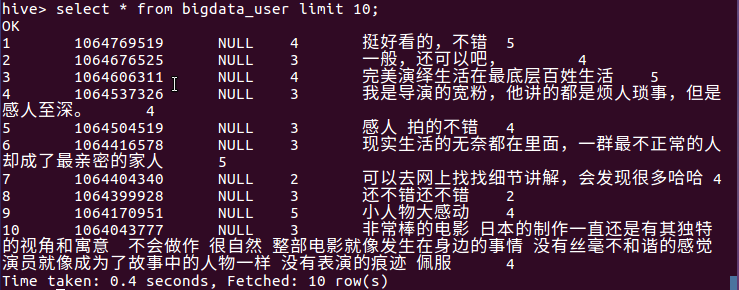
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
- 查询前20位猫眼电影用户对《小偷家族》电影的评分
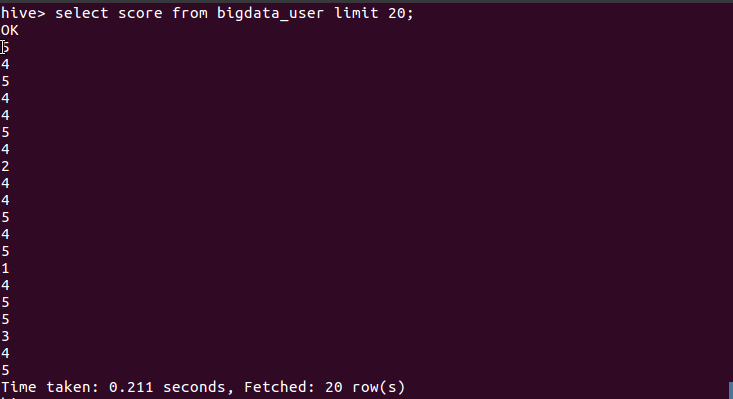
由上图可以看出大部分用户评分都在4分以上(5分评分为满分),这也就说明大部分用户对此部电影的评价都非常高。
- 查询给此电影1分评分的用户的评论

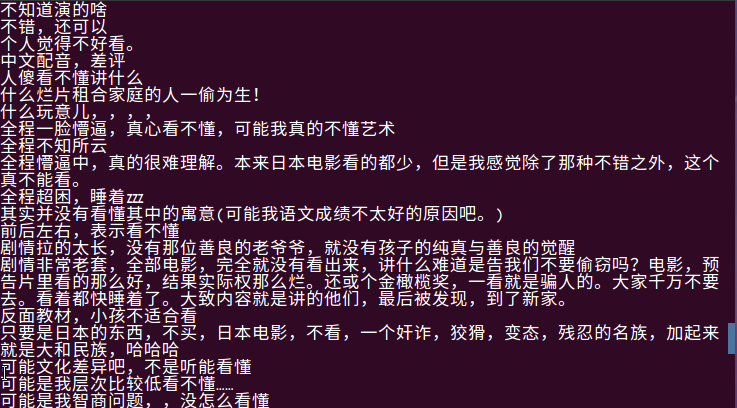
由上图可以看出给低分评价的用户多半为没看懂与难以理解所给出的低评分,由此可以得出用户对于电影的理解都不完全相同,一千个读者就有一千个哈姆雷特,大部分用户都是靠着主观意识来给与电影评分。
- 查询给此电影5分评分的用户的评论


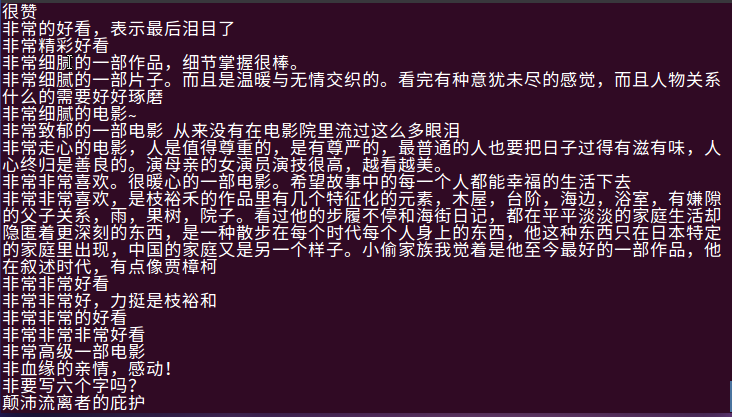
由5分评价也可以得出此部电影的主旨与想向观众表达的东西,可看出此部电影主要是围绕着亲情,感动为主题来叙述的。
- 查询对比5评分用户与1分评分用户的人数
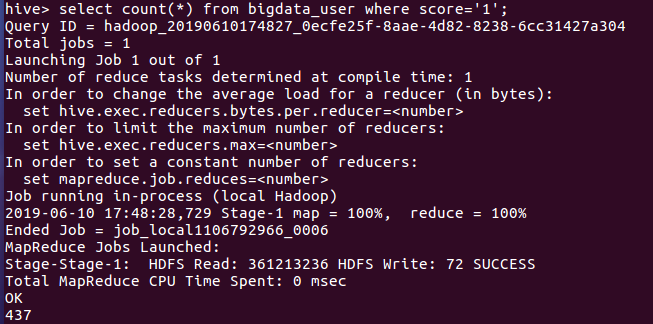
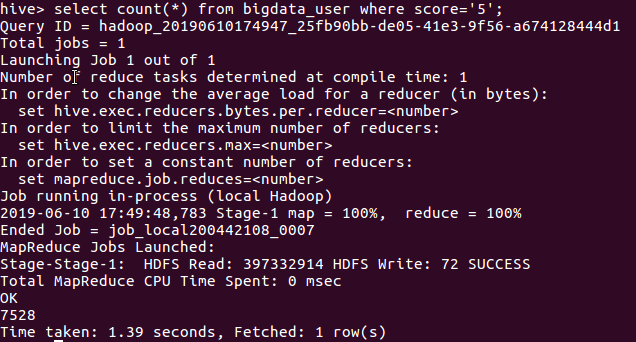
由上图可知给5分高分评价的用户人数为7528人,给1分低分评价用户人数为437人。由此可以知道这是一部优秀的电影。
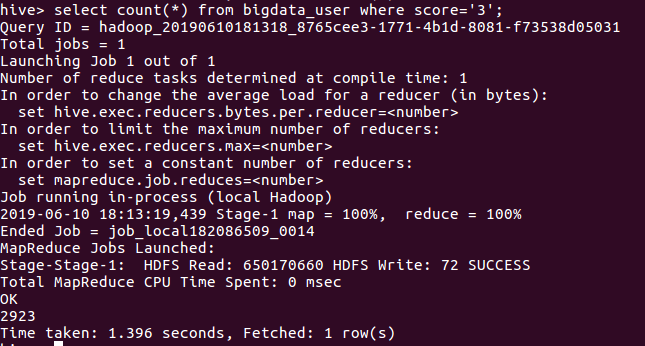
- 查询评分为3的用户人数
- 查询评分为1的用户id

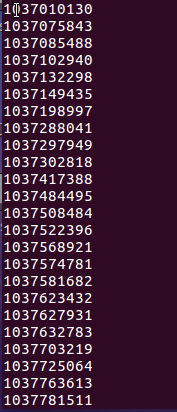
- 查询评分为4的用户的评论


与评分为5的评论相差不多,基本都是对整个电影的好评与受到的感动。
- 查询城市葫芦岛的评论用户人数
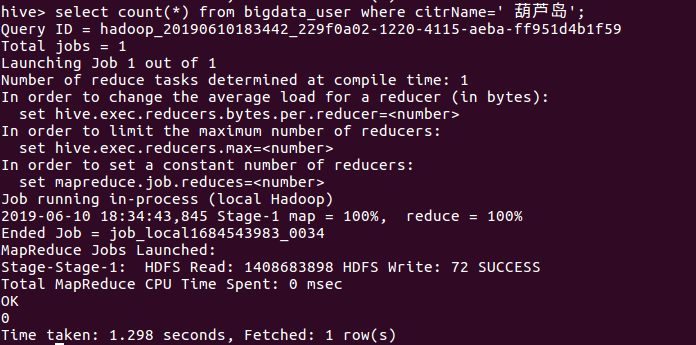
由此可看出此部电影还是比较小众,在较为不发达的城市基本无人问津。
- 查询评分为5的处于表格的序号

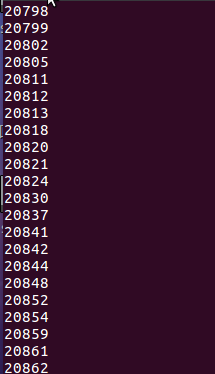
- 查询表格的数据中名字不重合的数据的数量
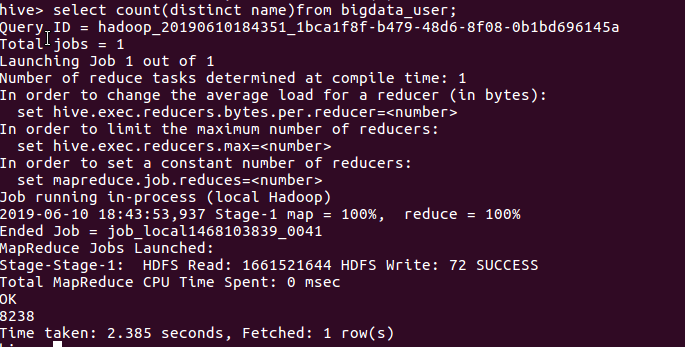
由上图可以看出由8238名用户没有重复评论数据的产生。说明爬取的数据仍然具备较大的重复性,需要注意。
- 查询表格数据中评论未重合的数据数量
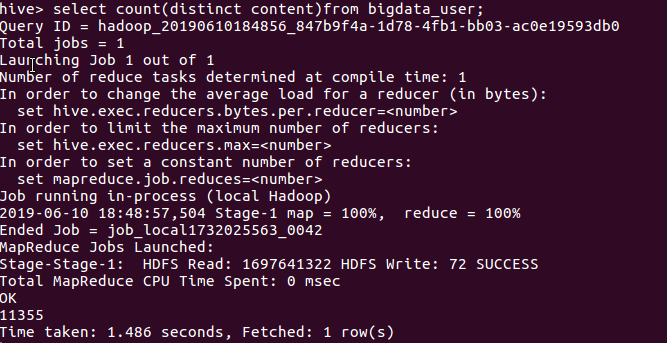
由上图可看出11355名用户评论没有重复数据的产生,基本可以视为有效数据。
总结:对于此次作业的完成,最大的问题就在于对于整个Hadoop环境的配置,就算是按部就班的按照步骤走,在这个过程中也遇到了非常多的问题,只要有一步的配置出现错误,会导致整个环境的配置失败。
但是总体来说还是基本按照要求完成了本次作业,在这个过程中我也是受益匪浅。

