

分布式并行计算MapReduce
作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
- MapReduce的概念:
MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。
- MapReduce的功能:
MapReduce的思想就是“分而治之”。Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。Reducer负责对map阶段的结果进行汇总。
- MapReduce的工作原理:
(1)MapReduce角色
•Client:作业提交发起者。
•JobTracker:初始化作业,分配作业,并且是与TaskTracker通信,最后是协调整个作业。
•TaskTracker:保持JobTracker通信,在分配的数据片段上执行MapReduce任务。
(2)提交作业
•在作业提交之前,是需要对作业进行配置
•程序代码,主要是自己书写的MapReduce程序。
•输入输出路径
•其他配置,比如输出压缩等这些
•当配置完成后,可以是通过JobCliNET来进行最后的一个提交
(3)作业的一个初始化
•当客户端提交完成后,JobTracker它就会将作业加入到队列里面,然后是进行调度,它的默认的调度方法是FIFO调试方式。
(4)任务的分配
•需要知道TaskTracker和JobTracker它们之间的通信与任务的分配它是通过心跳机制完成的。
•有趣的是TaskTracker它是会主动向JobTracker询问是否是有作业是需要完成的,若自己是可以做的,则就会申请到作业任务,这个任务可以使Map也可能是Reduce任务。
(5)任务的一个执行过程
•当申请到任务后,TaskTracker它就会做如下事情:
- 需要是拷贝代码到本地
- 拷贝任务的信息到本地
- 启动JVM运行任务
(6)状态与任务的更新
•任务在运行过程中,它是首先会将自己的状态汇报给TaskTracker,然后由TaskTracker汇总告之JobTracker。
•需要知道的是任务的一个进度是通过计数器来实现的。
(7)最后是作业的完成
•JobTracker它是在接受到最后一个任务运行完成后,它才会将任务标志为成功。
•这个时候会做删除中间结果等善后处理工作。
总的来说,需要了解的是MapReduce是一种编程的模型,并且是用于大规模数据集(大于1TB)的并行运算。从基本的概念“Map(映射)”和“Reduce(化简)”和他们的主要思想,这些都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。可以方便编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
- MapReduce的工作过程:
在MapReduce整个过程可以概括为以下过程:
输入 --> map --> shuffle --> reduce -->输出
输入文件会被切分成多个块,每一块都有一个map task
map阶段的输出结果会先写到内存缓冲区,然后由缓冲区写到磁盘上。默认的缓冲区大小是100M,溢出的百分比是0.8,也就是说当缓冲区中达到80M的时候就会往磁盘上写。如果map计算完成后的中间结果没有达到80M,最终也是要写到磁盘上的,因为它最终还是要形成文件。那么,在往磁盘上写的时候会进行分区和排序。一个map的输出可能有多个这个的文件,这些文件最终会合并成一个,这就是这个map的输出文件。
流程说明如下:
1、输入文件分片,每一片都由一个MapTask来处理
2、Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
3、从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
4、如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
5、以上只是一个map的输出,接下来进入reduce阶段
6、每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
7、相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
8、reduce输出
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
本次实验准备的文本文档为96-zyd.txt,内容如下图所示。

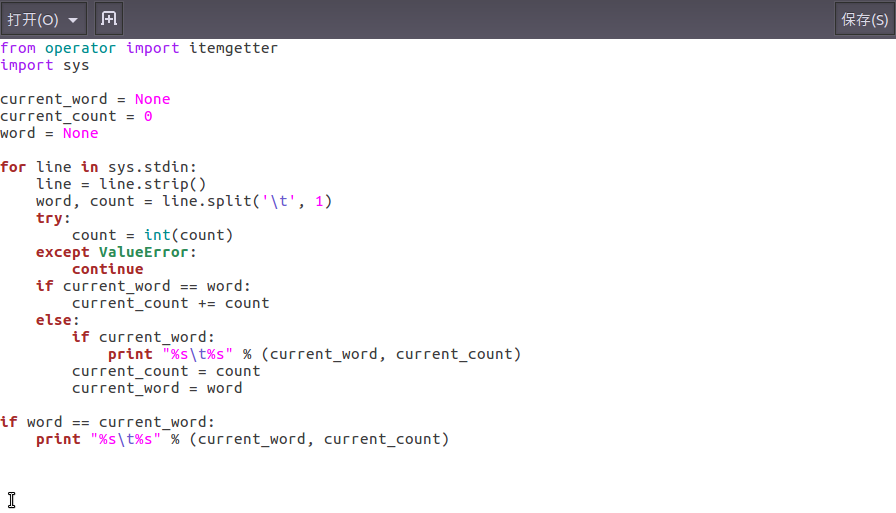
2)编写map函数和reduce函数,在本地运行测试通过
编辑map函数

编辑reduce函数
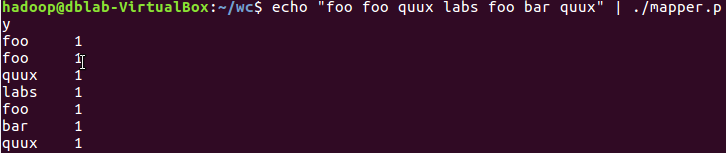
在本地测试是否能够成功运行。

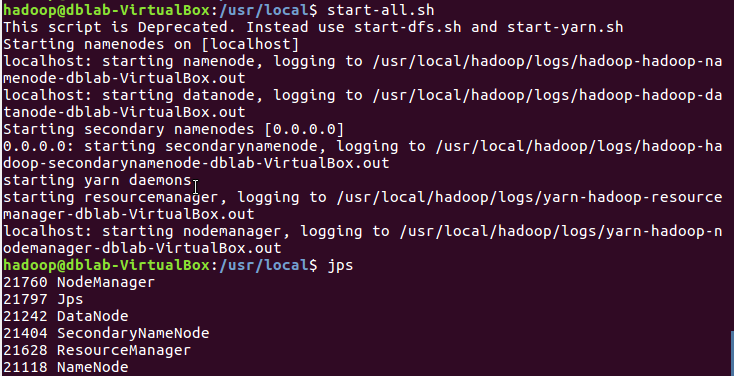
3)启动Hadoop:HDFS, JobTracker, TaskTracker
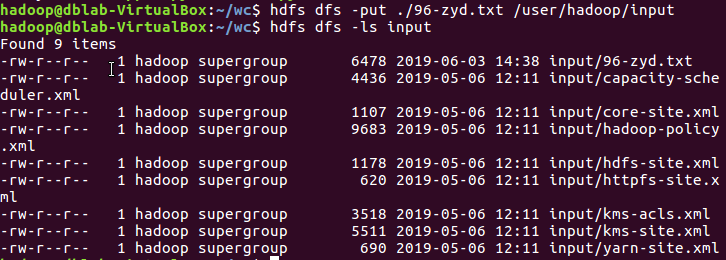
4)把文本文件上传到hdfs文件系统上 user/hadoop/input
5)streaming的jar文件的路径写入环境变量,让环境变量生效

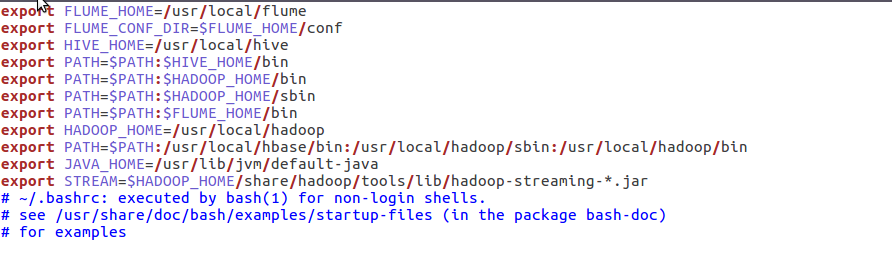
运行以后的检测是否添加环境变量成功。

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh
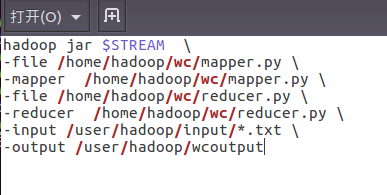
7)source run.sh来执行mapreduce
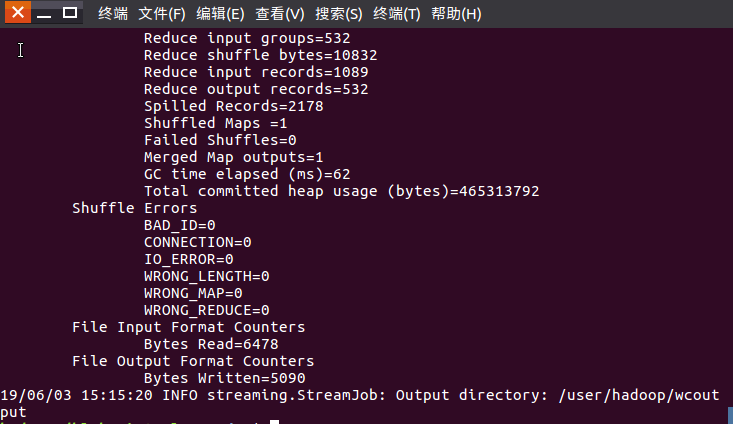
8)查看运行结果
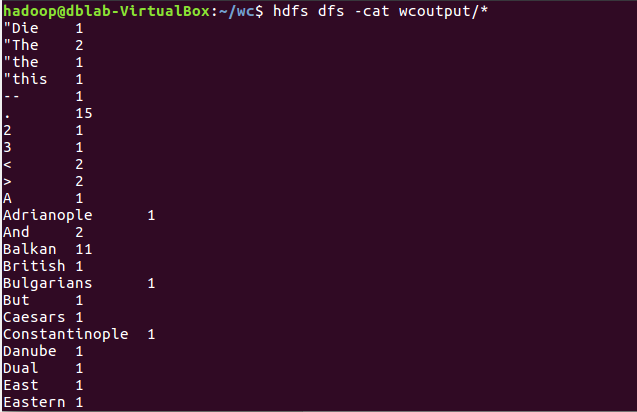
每位同学准备不一样的大一点英文文本文件,每个步骤截图交上博客上。
上述步骤测试通过之后,可以尝试对文本做处理之后再统计次数,如标点符号、停用词等。
有能力的同学尝试对之前爬虫爬取的文本,在Hadoop上做中文词频统计。

