Zookeeper集群安装
环境准备
- 安装jdk
-
通过xftp工具拷贝zookeeper到到linux系统下,为了方便我已经将安装包存储在百度网盘里啦!
链接:https://pan.baidu.com/s/1Z6-ZG7JUvkLcwabJtGYy7A
提取码:1234
-
将拷贝过来的zookeeper压缩包解压到指定目录(我的压缩包在/opt/source目录下,安装包在/opt/app目录下)
[root@shixun source]# tar -zxvf zookeeper-3.5.7-bin.tar.gz -C /opt/app/
-
将解压好的压缩包重命名,改一个简洁明了的名字,方便后续使用
[root@shixun app]# mv zookeeper-3.5.7-bin.tar.gz zookeeper
-
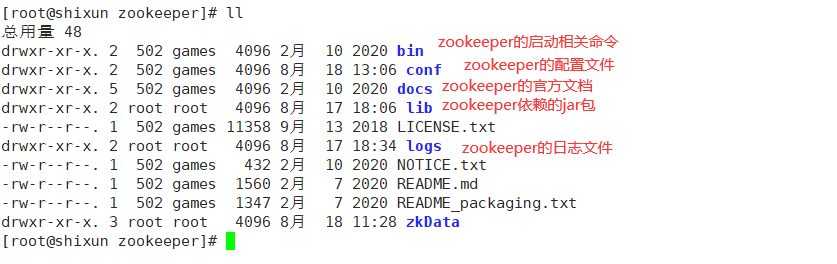
Zookeeper目录
集群规划
由于Zookeeper有一个半数机制,也就是Zookeeper服务器如果超过半数以上的节点存活的话,Zookeeper就可以对外正常提供服务,同时Zookeeper集群中有leader和follower,leader是需要选举完成的,即让超过半数以上的节点选举出同一个节点,这个节点就是Zookeeper中的leader。鉴于这个半数机制,Zookeeper建议安装到奇数台节点上。
故我们在shixun、node1和node2这三个已有节点上部署Zookeeper。
配置Zookeeper
集群规划好之后,就需要进行Zookeeper 的配置了
-
配置环境变量
[root@shixun app]# vim /etc/profile
export ZOOKEEPER_HOME=/opt/app/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
-
在/opt/module/zookeeper/这个目录下创建zkData。zkData是zookeeper中数据持久化存储的路径,也就是说Zookeeper中存储的文件都会在这个目录下
mkdir -p zkData
-
重命名/opt/module/zookeeper/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg
所以,为什么要将zoo_sample.cfg改为zoo.cfg呢?感兴趣的朋友可以在"值得一看"中找到答案!
-
配置zoo.cfg文件
-
修改dataDir地址为zkData的地址
dataDir=/opt/app/zookeeper/zkData
配置到这一步是表示已经配置好zookeeper的单机模式,保存退出后就可以通过zkServer.sh启动Zookeeper了,启动之后观察当前状态:

standalone就表示当前处于单机模式。这时可以通过zkCli.sh对zookeeper通过命令行进行管理。
-
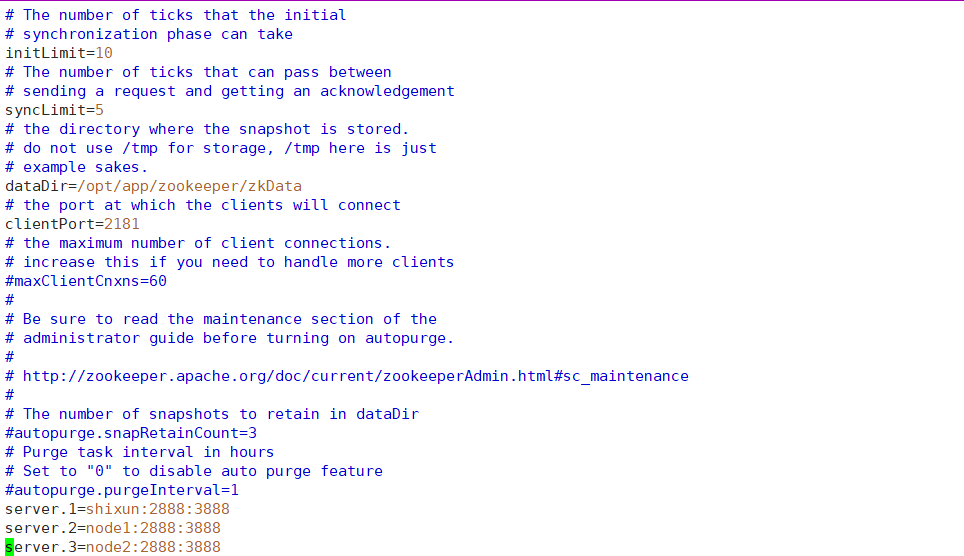
如果想要进行集群安装,还需要在zoo.cfg文件下增加如下配置:
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888

-
zoo.cfg参数解读见"值得一看"
-
-
集群操作
-
在/opt/app/zookeeper/zkData目录下创建一个myid的文件
touch myid
【注意】添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
- 编辑myid文件
vi myid
在文件中添加与server对应的编号:如1

-
- 拷贝配置好的zookeeper到其他机器上
scp -r zookeeper/ root@node1:/opt/app/
scp -r zookeeper/ root@node2:/opt/app/
并分别修改myid文件中内容为2、3
- 分别启动zookeeper
[root@shixun zookeeper]# zkServer.sh start
[root@node1 zookeeper]# zkServer.sh start
[root@node2 zookeeper]# zkServer.sh start
- 查看状态
[root@shixun zookeeper]# zkServer.sh status
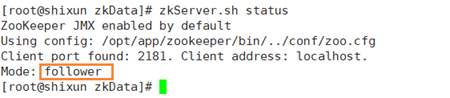
[root@node1 zookeeper]# zkServer.sh status

[root@node2 zookeeper]# zkServer.sh status

配置完成
至此,Zookeeper集群已经搭建完成,可以通过zkCli.sh进入Zookeeper的操作行对Zookeeper进行操作。由于之前搭建过Hadoop的高可用分布式环境,所以可以在Zookeeper中看见目录下有hadoop-ha文件,里面就存储了Hadoop HA环境的相关文件,可以通过Zookeeper完成对其的管理。

值得一看
为什么要把zoo_sample.cfg改为zoo.cfg?
这里附上官网链接https://zookeeper.apache.org/doc/r3.4.11/zookeeperStarted.html#sc_Download。从官网中可以发现这样一句话:

要想启动Zookeeper,必须有一个配置文件:zoo.cfg

再根据这句话的信息可以知道,这个文件也不一定必须是zoo.cfg。我们再去看Zookeeper的启动脚本zkServer.sh,可以发现脚本文件里没有提到启动需要zoo.cfg这个文件,但是却关联了脚本zkEnv.sh。
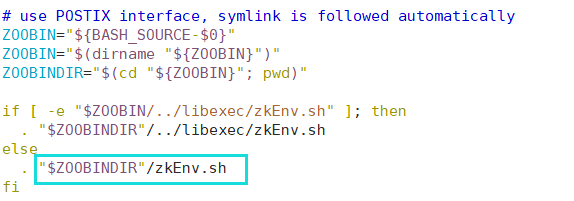
再去zkEnv.sh文件中找,可以发现:

这时大概就知道为什么要将zoo_sample.cfg改为zoo.cfg了,同时通过观察zoo_sample.cfg里面涉及到的信息,可以知道zoo_sample.cfg是zoo.cfg的一个样例,故直接将其改名就可以了。 如果你不想重命名,只需要去 zkEnv.sh 脚本把zoo.cfg修改为zoo_sample.cfg即可。
zoo.cfg参数解读

- tickTime:通信心跳数,Zookeeper服务器心跳时间,单位毫秒
Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个tickTime时间就会发送一个心跳,时间单位为毫秒。它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间。(session的最小超时时间是2*tickTime)
- initLimit:LF初始通信时限
集群中的follower跟随者服务器(F)与leader领导者服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量),用它来限定集群中的Zookeeper服务器连接到Leader的时限;投票选举新leader的初始化时间;Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态;Leader允许Follow在initLimit时间内完成这个工作。
- syncLimit:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果Leader发出心跳包在syncLimit之后,还没有从Follow那收到响应,那么就认为这个Follow已经不在线了。
- dataDir:数据文件目录+数据持久化路径
保存内存数据库快照信息的位置,如果没有其他说明,更新的事务日志也保存到数据库。
- clientPort:客户端连接端口2181/监听客户端连接的端口
-
搭建集群时的参数配置详解:
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
